






又一个媲美 GPT-4 的大模型出现了?挑战OpenAI的新模型免费上线,40%计算量性能逼近GPT-4
本周四,美国 AI 创业公司 Inflection AI 正式发布新一代大语言模型 Inflection-2.5。
据介绍,Inflection-2.5 将强大的 LLM 能力与 Inflection 标志性的「同理心微调」结合在一起,兼具高情商与高智商,可联网获取事实信息,其性能可与 GPT-4、Gemini 等领先大模型相媲美。
Inflection-2.5 现已向所有 Pi 用户开放,在 PC 端、iOS 和安卓 App 上均是免费可用。ps. 机器之心也简单测试了下,觉得确实还只是「逼近」(不如)GPT-4,感兴趣的读者可以自行体验下。
链接:https://pi.ai/talk
值得注意的是,Inflection-2.5 实现了接近 GPT-4 的性能,而训练过程却仅使用 GPT-4 40% 的算力。
Inflection AI 表示,新一代大模型在编码和数学等智商领域取得了特别的进步。这转化为对关键行业基准的具体改进,确保 Pi 始终处于技术前沿。Pi 现在还融入了世界一流的实时网络搜索功能,以确保用户获得高质量的突发新闻和最新信息。
Inflection AI 最近的表现在 LLM 领域很吸引眼球,他们推出的 Inflection-2.5 模型性能可与包括 OpenAI 的 GPT-4 和 Google 的 Gemini 在内的顶尖 LLM 相媲美。
这家公司的快速发展得益于最近一轮由微软、英伟达以及包括 Reid Hoffman、Bill Gates 以及 Eric Schmidt 在内的知名投资者领头的 13 亿美元融资。这次重大的投资使 Inflection AI 累计筹集的资金达到了惊人的 15.25 亿美元。
目前,Inflection AI 在与 CoreWeave 和英伟达的合作下打造全球最庞大的 AI 集群,该集群由 22000 张 NVIDIA H100 Tensor Core 显卡构成,这在历史上是前所未有的。这一强大的计算力量将助力他们培训和部署新一代大规模 AI 模型,推动其在个人 AI 领域取得突破。
该公司目前已经取得了突破性成果。拥有超过 3500 张 NVIDIA H100 Tensor Core 显卡的 Inflection AI 集群,在开源基准 MLPerf 上展现了先进性能。在与 CoreWeave 和英伟达联合提交的报告中,该集群仅用 11 分钟就完成了 LLM 的训练任务,成为这一基准上最快的集群。
在此之前,公司发布了 Inflection-1,这是他们自主开发的 LLM。在多项常用于评估 LLM 的基准测试中,它超过了包括 GPT-3.5、LLaMA、Chinchilla 和 PaLM-540B 在内的行业巨头。用户可以通过简单自然的方式与 Inflection AI 的个人 AI——Pi 互动,从而获得快速、相关、有价值的信息和建议。
Inflection AI 对透明度和可重复性的承诺体现在他们发布的一份技术备忘录上。备忘录详细介绍了 Inflection-1 在多个基准测试中的评估和表现,显示出它在与 PaLM-540B 相同计算量级的模型中表现突出。
Inflection-1 的成功,加上公司计算基础设施的迅速扩张(得益于大规模融资),凸显了 Inflection AI 对于实现 “为每个人打造个人 AI” 这一使命的坚定承诺。随着 Inflection-1 被整合到 Pi 中,用户现在可以体验到个人 AI 的强大能力,享受其富有同理心的个性、实用性和高标准的安全性。
Inflection-2.5

Inflection AI 的最新模型 Inflection-2.5 现已面向所有使用其个人 AI 助手 Pi 的用户开放,支持包括 Web 端(pi.ai)、iOS、Android 以及全新的桌面应用在内的多个平台。这一整合是 Inflection AI 实现其 “为每个人打造个人 AI” 使命的一个重要里程碑,它不仅能力强大,还保持了该公司特有的富有同理心的个性和高安全标准。
在性能方面也取得了巨大飞跃,与 Inflection AI 之前的模型 Inflection-1 相比,Inflection-2.5 大约只使用了 GPT-4 的 4% 训练计算量(浮点运算),但在各类智力导向任务中的表现已经达到了 GPT-4 的 72%。在 Inflection-2.5 的加持下,Pi 在智能方面也取得了明显提升,特别是在编程和数学领域。
在多项行业关键基准测试中,Inflection-2.5 也展现出了其强大的实力,平均性能达到了 GPT-4 的 94%,尤其在 STEM(科学、技术、工程、数学)领域表现出色。这一卓越成就体现了 Inflection AI 在推进技术创新的同时,始终专注于优化用户体验和安全性。
在编程和数学方面,Inflection-2.5 展现了明显的优势。在 BIG-Bench-Hard(针对大语言模型的一系列挑战性问题)上,它比 Inflection-1 提高了超过 10%。通过 MBPP+ 和 HumanEval+ 这两个编程基准测试,Inflection-2.5 与其前代模型相比取得了明显进步,巩固了其在编程领域的领先地位。
据 DeepSeek Coder 报道,在 MBPP+ 基准测试中,Inflection-2.5 的表现远超其前代,与 GPT-4 不相上下。同样,在 HumanEval+ 基准测试中,Inflection-2.5 显示出了巨大的进步,不仅超越了 Inflection-1,并且接近于 GPT-4 的水平,这一点从 EvalPlus 排行榜上也可以看出。
Inflection-2.5 vs GPT-4
Inflection-1 训练使用的 FLOP 约为 GPT-4 的 4%,在各种「IQ 导向」型任务中,其平均性能约为 GPT-4 水平的 72%。现在,Inflection-2.5 尽管只使用 GPT-4 40% 的 FLOP 来进行训练,但其平均性能却达到了 GPT-4 的 94% 以上。如下图所示,Inflection-2.5 的性能取得了全面的显著提升,其中 STEM 领域知识的改进最大。
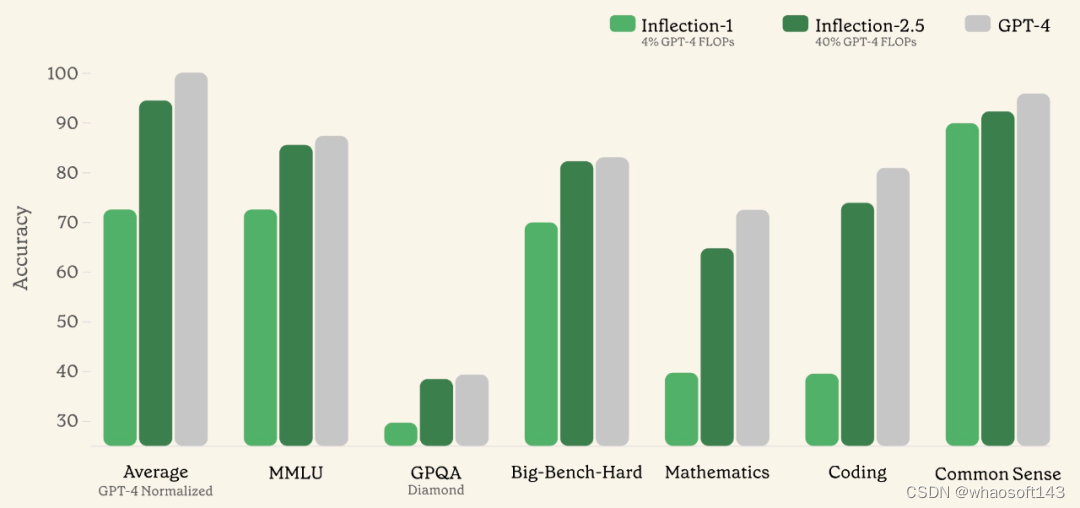
Inflection-2.5 在行业基准测试中表现出色,尤其是在 MMLU 基准和以专家级难度著称的 GPQA Diamond 基准上,与 Inflection-1 相比,明显提升。这些测试结果突出了该模型在处理从高中级难度到专业级挑战的广泛任务方面的能力。
在 STEM(科学、技术、工程、数学)考试中,Inflection-2.5 的表现同样出众,特别是在匈牙利数学考试和物理 GRE 中。在匈牙利数学考试中,Inflection-2.5 通过利用特定的少样本提示和格式,展示了其数学才华,使得结果更容易被复现。
在物理学 GRE(物理学研究生入学考试)中,Inflection-2.5 在 maj@8 中达到了人类考生中的第 85%(多数票为 8),在物理问题解决方面展现了强大实力。此外,该模型在 maj@32 中接近最高分,证明了其在解决复杂物理问题上的高度准确性。
在提升用户体验方面,Inflection-2.5 不仅保持了 Pi 一贯的个性化特点和安全标准,还提升了其作为多功能且极具价值的个人 AI 的地位。从讨论时事、寻找本地推荐、备考、编程,到轻松的日常对话,搭载 Inflection-2.5 的 Pi 承诺提供更加丰富的用户体验。
凭借 Inflection-2.5 的强大功能,用户可以与 Pi 讨论比以往更广泛的内容。该模型处理复杂任务的能力,加上其同理心特质和实时网络搜索功能,确保用户获得高质量、最新的信息和指导。
Inflection-2.5 整合到 Pi 中的影响已经体现在用户情绪、参与度和留存率等方面。Inflection AI 的自然用户增长速度飞快,目前每天有一百万活跃用户,每月有六百万活跃用户与 Pi 交换超过四十亿条信息。
用户与 Pi 的对话持续平均时间达到 33 分钟,其中每天有 10% 的用户对话超过一小时。此外,每周与 Pi 互动的约 60% 用户在下周会继续互动,表明其月度用户黏性超过了行业内的主要竞争者。
Inflection-2.5 在两项不同 STEM 考试 —— 匈牙利数学考试、物理学研究生入学考试(GRE)—— 的成绩如下:

如下表所示,该研究还在 MMLU 基准、GPQA Diamond 基准上评估了 Inflection-2.5。MMLU 基准涵盖 STEM、人文、社会科学等领域的 57 个学科,能够有效地测试 LLM 的综合知识能力,而 GPQA Diamond 基准是一个极其困难的专家级基准。

在 BIG-Bench-Hard 基准上,Inflection-2.5 比 Inflection-1 性能提高了 10% 以上,并且可与 GPT-4 相媲美。BIG-Bench-Hard 基准主要涵盖大型语言模型难以解决的问题。

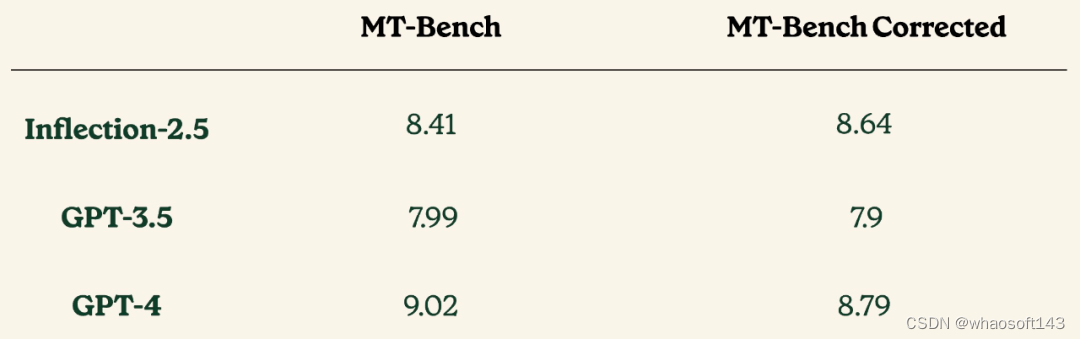
该研究还在 MT-Bench 基准上进行了评估。然而,研究团队意识到该基准在推理、数学和编码类别中有很大一部分(近 25%)的样本示例具有不正确的参考解决方案或前提有缺陷。因此,该研究更正了这些示例,并再次进行评估实验,结果如下表所示:
在 GSM8k 和 MATH 基准上的评估结果表明,Inflection-2.5 在数学和编码能力方面比 Inflection-1 有显著改进:

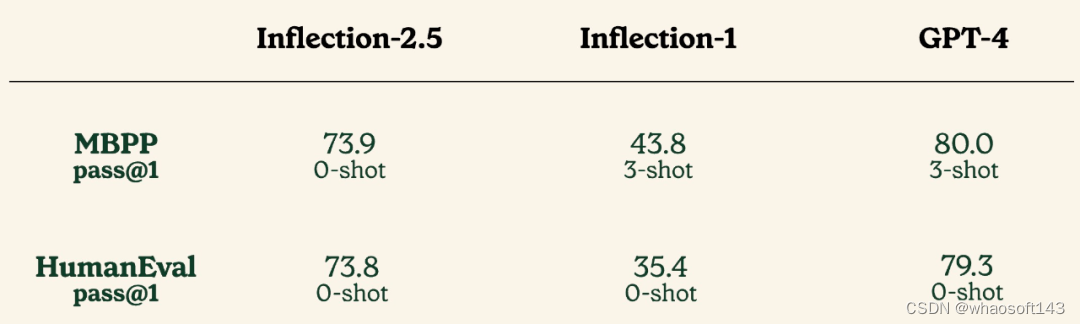
为了进一步测试 Inflection-2.5 的编码能力,该研究在 MBPP+ 和 HumanEval+ 两个编码基准上进行了评估实验,结果如下表所示:
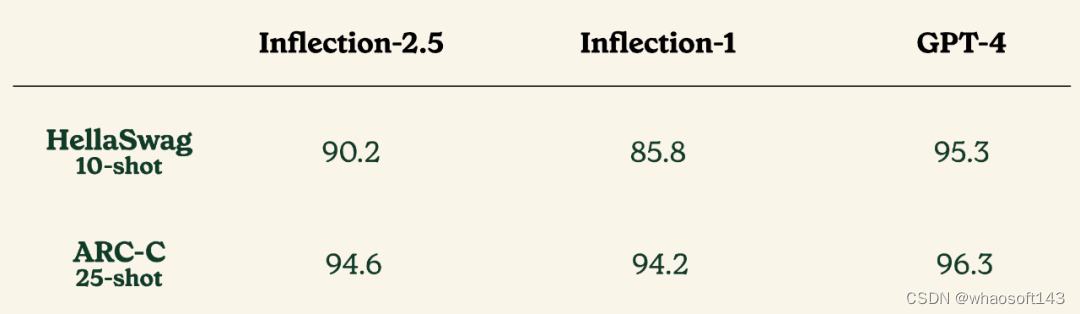
研究团队在 HellaSwag 和 ARC-C、以及各种模型常识和科学基准上评估了 Inflection-2.5。从下图结果来看,Inflection-2.5 在这些基准上实现了强劲性能。
此外,以上所有评估都是使用现在支持 Pi 的模型完成的。但也需要注意,由于网络检索(以上基准没有使用网络检索)、few-shot 提示的结构以及其他生产方面的影响,用户体验可能略有差异。
总的来说,Inflection-2.5 保持了 Pi「走心」的特性和极高的安全标准,成为了一个更全面的有用模型。
最近一段时间,大语言模型的技术竞争进入了白热化阶段,在众多科技公司中,Mistral AI(Mistral Large)、Anthropic(Claude 3)脱颖而出,提出的新技术实现了与 GPT-4、Gemini Ultra 接近的能力。昨天出现的 Inflection-2.5,似乎也要加入第一梯队的行列。
作为硅谷明星创业公司,Inflection AI 的来头不小,它成立与 2022 年,三位联合创始人分别是原 DeepMind 联合创始人 Mustafa Suleyman、Linkedln 联合创始人 Reid Hoffman,还有前 DeepMind 首席科学家 Karen Simonyan。
去年 6 月,Inflection AI 宣布获得 13 亿美元融资,由微软、英伟达以及 Reid Hoffman、比尔・盖茨、谷歌前 CEO 埃里克・施密特领投。目前,Inflection AI 已成为全球第四大生成式 AI 创业公司。
技术细节和基准透明度
在技术细节和基准透明度方面,Inflection AI 履行了其对透明度和可重复性的承诺,提供了 Inflection-2.5 在各行业基准测试中的全面技术结果和细节。例如,在经过修正的 MT-Bench 数据集上,该数据集解决了原始数据集中的一些问题,Inflection-2.5 的表现与其他基准测试中的预期相符。
Inflection AI 还在 HellaSwag 和 ARC-C 等常识和科学基准上对 Inflection-2.5 进行了评估,这些基准被众多模型所采用,结果展示了 Inflection-2.5 在这些饱和基准测试中的强劲表现。
值得注意的是,尽管这些评估代表了 Pi 动力模型的性能,但用户的实际体验可能会因网络检索(未在基准测试中使用)、少样本提示的结构和其他生产端差异等因素略有不同。
总结
Inflection-2.5 代表了在 LLM 领域的一次重大飞跃,可与 GPT-4 和 Gemini 等行业标杆的能力相媲美,同时只使用了一小部分计算资源。在一系列基准测试中表现出色,特别是在 STEM 领域、编程和数学方面,Inflection-2.5 已成为 AI 领域的一支重要力量。
Inflection-2.5 集成到 Inflection AI 的个人 AI 助手 Pi 中,将原始功能与同理心个性和安全标准相结合,可以提供丰富的用户体验。随着 Inflection AI 不断突破 LLM 的极限,整个 AI 社区都在期待这家创新公司接下来的新突破。
Inflection AI 的前瞻性不仅体现在模型开发上,还在于公司意识到了预训练和微调对于创造高质量、安全、有用的 AI 体验的重要性。作为一个垂直整合的 AI 工作室,Inflection AI 自行处理了从数据摄入、模型设计到高性能基础设施的整个过程。
参考链接: https://inflection.ai/inflection-2-5
原文链接: https://www.unite.ai/inflection-2-5-the-powerhouse-llm-rivaling-gpt-4-and-gemini/















 340
340

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









