







时间序列
生成指定范围的日期,例:
pd.date_range(‘4/1/2018’,‘4/5/2018’)
‘2018-04-01’,2018-04-02’,‘2018-04-03’ …‘2018-04-05’
指定起始或者结束日期,并指定步长(单位是“日”),例:
pd.date_range(start=‘4/1/2018’,periods=5)
pd.date_range(end=‘4/5/2018’,periods=5)
将时间列设为索引,时间的标准格式对应类似于20190101这样的格式,Y为四位年,
df.date = pd.to_datetime(df.date,format="%Y%m%d")
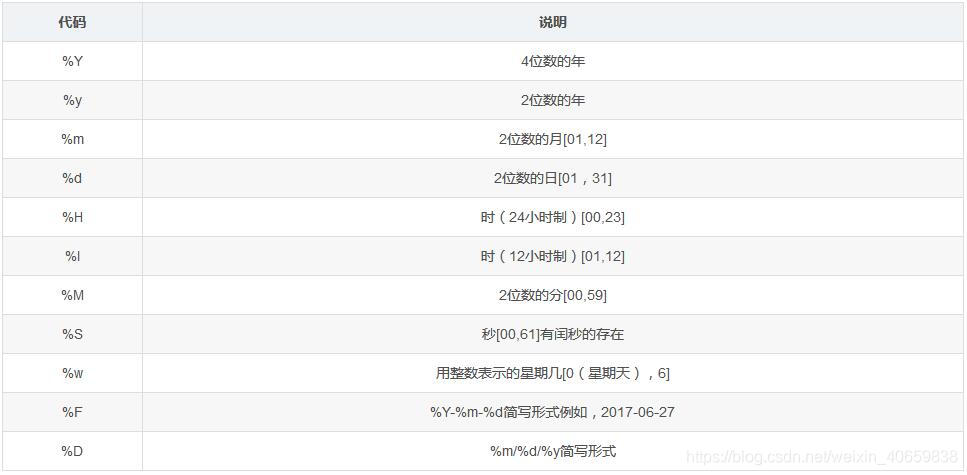
datetime格式标准
dataFrame按时间聚合
大多标准按时间生成的数据,可以用时间作索引,pandas在时间聚合上有很好的函数应用,用得比较多的就是resample,重采样。比如以分钟为标准的数据,可以聚合成按小时的,日,月,季,或年数据,并且在后面加上mean()、sum()可以求平均值或累计值。
用日数据,按月、季、年统计平均值,例:
原数据格式
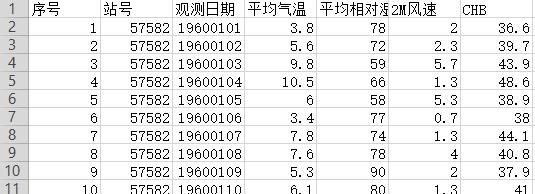
其中有一列为时间,此列在应用resample前设为索引,并转化为时间格式
resample(‘M’) 按月,resample(‘Y’)按年,resample(‘D’)按天。还有Q,按季,T按分,2T每两分钟,3M每三个月。W按周等。
#Author: Wu dongqiao July 9, 2019
import pandas as pd
import time
path='D:\\CHB.csv'
data=pd.read_csv(path,index_col=0) #读取数据
#将CHB列中缺失的数据线性插值
data['CHB']=round(data['CHB'].interpolate(method = 'linear', axis=0),1)
#将时间列转为时间格式
data['观测日期']=pd.to_datetime(data['观测日期'],format='%Y%m%d')
#将时间作为索引
data = data.set_index('观测日期')
#保留一位小数
format1=lambda x:"%.1f"%x
#按月进行平均值统计
dfM=data.resample('M').mean()
dfM[['平均气温','平均相对湿度','2M风速','CHB']]=dfM[['平均气温','平均相对湿度','2M风速','CHB']].applymap(format1)#保留一位小数
#保存月平均数据
dfM.to_csv('D:\\舒适指数月平均.csv',encoding='gbk')
#按年进行统计
dfY=data.resample('Y').mean()
dfY[['平均气温','平均相对湿度','2M风速','CHB']]=dfY[['平均气温','平均相对湿度','2M风速','CHB']].applymap(format1) #保留一位小数
#保存年平均数据
dfY.to_csv('D:\\舒适指数年平均.csv',encoding='gbk')
#按季进行统计
dfQ=data['1960-5':'2018-11'].resample('3M').mean()
dfQ[['平均气温','平均相对湿度','2M风速','CHB']]=dfQ[['平均气温','平均相对湿度','2M风速','CHB']].applymap(format1) #保留一位小数
dfQ.to_csv('D:\\舒适指数季平均.csv',encoding='gbk')
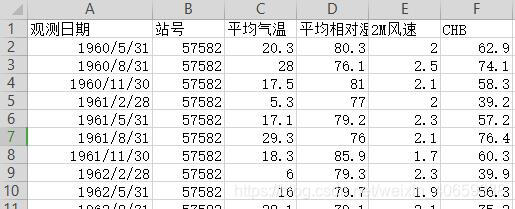
结果数据格式
月平均:

季平均
年平均(略)
时间值默认显示统计到间隔的最后一天。















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









