







借鉴
https://blog.csdn.net/nickzzzhu/article/details/81539138
https://blog.csdn.net/zpalyq110/article/details/79527653
https://blog.csdn.net/q383700092/article/details/53744277
GBDT
GBDT–Gradient Boosting (Regression) Decistion Tree
GBDT(Gradient Boosting Decision Tree) 又叫 MART(Multiple Additive Regression Tree),是一种用于回归的机器学习算法,该算法由多棵回归决策树组成,所有树的结论累加起来做最终答案。当把目标函数做变换后,该算法亦可用于分类或排序。
回归问题
-
明确损失函数是误差最小

目标是找到一种函数映射关系,即多维特征X到标签Y的映射关系F,使得所有样本的损失函数值的总和最小。
一般来说,F是属于函数空间的,有无数种选择方式,但是我们需要确定一种明确的表达方式h来限制F,变成一个确定的函数模式,也就是用参数集P来确定唯一的F,上述公式用am表示了P。 -
构建第一棵回归树
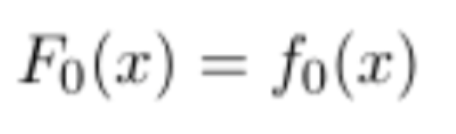
一般来说,初始化的第一个回归树的输出是所有标签的均值。
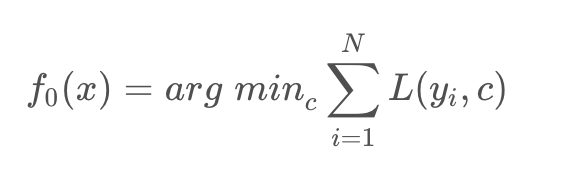
网上举的例子都是按照平方损失来当做损失函数,因为举例这样很简单。 -
学习多棵回归树

在函数空间的优化,可以把F当做变量,但是F无参数,需要对F进行参数化h表示,h中有很多参数用am表示,步长用ρm表示。
其中的stagewiseme每轮会更新值,也就是更新每个样本的标签,
stepwise每轮也会更新,但是是函数空间的更新,又多加入了一个基学习器,ρgm(x)
当然,虽然每轮学习的目标是梯度(平方损失时是残差),但是每轮不一定学到100%,所以拟合程度还是有限,不能写成ρgm,这是最好的结果,应该是用h拟合g,g是负梯度,基学习器是ρh。
总结来说,我们要使所有样本损失函数总和最小化,以前在参数空间优化,GBDT在函数空间优化,每次学到一个使损失函数减小最快的函数进行加法模型的叠加,那么这个函数空间F没有参数化的话我们没法进行数值化求解,所以需要用参数化的函数h来表示F空间中的一个f,h有他的权重ρ,找到h后就可以通过数值运算优化F,那么F优化最快的办法是梯度下降,那就要计算F的负梯度方向,这里就需要将F自己作为自变量求导,求得到的梯度方向g是每个样本需要按照这个方向,整体的损失减小最快的方向,那么我们每次学习这个梯度方向就是学习最快的方法,这也体现到每次样本的标签都会改变的原因。所以这个g就是每轮的样本权重,我们的yi→gm,当然每次拟合不一定100%,我们需要尽力使(gm-h)² 最小,这就需要参数am去调整,调整好之后得到了h是当前最优的,体现了前向分步算法,GBDT中还体现了步长ρ,虽然我们第m轮学到了很接近gm的回归树,但是我们只采用ρh,剩下(1-ρ)我们用后面的学习器学习,抑制过拟合,更新Fm=Fm-1+ρh,这一轮学完后,下一轮还需要求梯度
这里我理解的是,一般损失时,用原始标签yi对Fm求梯度,结果作为下一轮学习标签。
平方损失时,yi对Fm求梯度,梯度=0算出
Fm=yi
Fm-1+hm = yi
hm = yi-Fm-1=残差
这里hm是第m轮学习器,也就是这一轮需要学习的标签=yi-前m-1轮的预测结果=yi - ∑im-1ρh=yi - ρ1h1-ρ2h2-…-ρm-1hm-1
也就是说我们不用每次用原始的yi对F求导,直接对上一轮的残差拿来,对当前轮的预测值再进行残差计算,就是下一轮的标签。
这里一般损失时,gm是当前梯度,假设我们不知道极小值在哪,只能试探走,所以不让gm=0
平方损失时,我们直接让gm=0,每次学习直冲向极小值,所以学习的更新值略有不同。
迭代:计算梯度/残差gm(如果是均方误差为损失函数即为残差)
公式中的步长/缩放因子ρ,用 a single Newton-Raphson step 去近似求解下降方向步长,
通常的实现中 ρ 被省略,采用 shrinkage 的策略通过参数设置步长,避免过拟合
也就是说,公式中的迭代过程就类似于梯度下降,放到二维里面理解就是要找到曲线最小值就需要从当前点按照负导数方向进行移动,负导数方向就是负梯度方向,那么移动多远就是步长,在梯度下降中,步长ρ是超参数,不属于学习范围,人为设定的。但是在GBDT中这一步ρ不在这一步的代码实现中,转向在最后shrikage策略体现,就是我尽全力拟合gm(x)和h(x)
拟合好之后,对预测的结果记性缩减,实际学到的是ρh,这时的残差(平方损失时)就是gm-ρh,那这个值也就是相当于损失函数对Fm求梯度的值,我们可以理解成,当损失函数是平方损失时,求梯度步骤全部换成求残差的过程,结果当做下一轮的标签/目标进行学习。
第m棵树fm=pgm
模型Fm=Fm-1+pgm
4. F(x)等于所有树结果累加 














 8797
8797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









