







本文记录了我对kmeans算法的学习,kmeans算是聚类算法最简答的一种,哈哈,这是我接触到的第一个算法,由于刚开始学习python,对python的语法不是很了解,不能熟练的运用python编程,代码写的不是很精简,望见谅!原理参考了JerryLead的博客,这个博客是把斯坦福大学的Andrew Ng的讲义翻译了一遍,不过翻译的不错!值得学习!有兴趣的同学还可以看下《模式识别与机器学习》这本书与Andrew Ng的讲解稍有不同 ,这本书是从损失函数开始讲解,而Andrew Ng直接上算法,最后讨论损失。在这里原理就不多赘述了,直接上代码吧:
#-*- coding:utf-8 -*-
import numpy as np
import matplotlib as mpl
import traceback
'''读取文件
@filePath:路径地址
@return 数据 矩阵
'''
def loadData(filePath):
dataMat = []
file = open(filePath,'r')
for line in file.readlines():
row = []
'''二维数据'''
curLine = line.strip().split()
for x in curLine:
fltLine = float(x)
row.append(fltLine)
X = np.array(row)
dataMat.append(X)
file.close()
return np.mat(dataMat)
# return data
'''computer vector distances'''
def distances(vecA,vecB):
return np.sqrt(np.sum(np.power(vecA - vecB, 2)))
'''构建一个包含随机质心的函数'''
def randCent(dataSet,k):
# n is column number
n = np.shape(dataSet)[1]
# 初始化质心
centeroids = np.mat(np.zeros((k, n)))
# 找出数据集的每一维度的最小值,和范围,并随机初始化质心
for j in xrange(n):
minJ = np.min(dataSet[:, j])
rangeJ = float(np.max(dataSet[:, j]) - minJ)
centeroids[:, j] = minJ * np.mat(np.ones((k,1))) + rangeJ * np.random.rand(k,1)
return centeroids
'''this is K-measn core'''
def kmeans(dataSet,k,distMeans = distances,createCent = randCent):
# 数据集有几个样本
m = np.shape(dataSet)[0]
# 初始化每一个样本的所属类别,那么就创建一个m×2的矩阵,第一列存储标签,后面一列存储距离的平方
clusterAssment = np.mat(np.zeros((m,2)))
# 损失值
# loss = np.mat(np.zeros((k,2))) 不用了这个该行删去
# 创建k个随机质心
centroids = createCent(dataSet,k)
# 一个标志判断质心是否改变
clusterChanged = True
while clusterChanged:
clusterChanged = False
# 遍历每个样本
for i in range(m):
# 初始化最小距离为无群大、最小距离对应的索引为-1
minDist = np.inf;minIndex = -1
# 计算每一个样本和质心的距离
for j in range(k):
distJI = distMeans(centroids[j,:],dataSet[i,:])
if distJI < minDist:
# 如果距离小于当前最小距离,则赋值,最小距离对应的索引为j
minDist = distJI;minIndex = j
# 当前聚类结果中第i个样本的聚类结果发生变化,布尔值设为ture,继续聚类算法
if clusterAssment[i,0] != minIndex:
clusterChanged = True
clusterAssment[i,:] = minIndex,minDist**2
loss = np.sum(clusterAssment[:,1],axis=0)
# 本来i是 minDist**2,用来记录平方误差
print "分为k类,质心为---------------\nk = ",k,centroids
print "每个样本的聚类标签[标签,损失]------------\n",clusterAssment
print "损失------------\n", loss
# 遍历每一个质心
for cent in range(k):
# 将数据集合中所有属于当前质心类的样本通过条件过滤筛选出来
ptsInClust = dataSet[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# 计算这些数据的均值作为该类质心向量,更新质心
centroids[cent,:] = np.mean(ptsInClust,axis=0)
# lossIn = clusterAssment[np.nonzero(clusterAssment[:, 0].A == cent)[0]]
# loss[cent,:] = np.sum(lossIn,axis= 0)
# print "损失------------", loss
# 返回k个聚类,聚类的结果及误差
return centroids,clusterAssment,loss
if __name__ == '__main__':
#聚类个数
K = 2
'''文件路径-------这个是二维数据'''
# filePath = "../data/training_4k2_far.txt"
'''文件路径-------这个是三维数据'''
filePath = "../data/iris.txt"
dataSet = loadData(filePath)
# print dataSet
kmeans(dataSet,K) 对于二维数据我们还可以画图来显示出聚类的效果,代码如下:
#drawing.py
#-*- coding:utf-8 -*-
from matplotlib import pyplot as plt
import kmeans
import traceback
import numpy as np
#创建一个图
def preDataSetaShow(x,y):
try:
# 创建一个图
fig = plt.figure(figsize=(8,5),dpi=80,facecolor='w')
axes = fig.add_subplot(111)
#画点
axes.scatter(x,y,label = "dataSet",s = 20 ,c = 'r')
#加标题
plt.title('dataSet',fontsize = 25)
plt.xlabel("X",fontsize = 20)
plt.ylabel('Y',fontsize = 20)
axes.legend(loc = 2)
plt.show()
except Exception,e:
print traceback.print_exc()
# 聚出2个类
def lastDataSetShow2(x0,y0,x1,y1,centx,centy):
try:
fig = plt.figure(figsize=(8,5),facecolor='w')
axes = fig.add_subplot(111)
cluster0 = axes.scatter(x0, y0, label='cluster0', s=15, c='r')
cluster1 = axes.scatter(x1, y1, label='cluster1', s=15, c='b')
cent = axes.scatter(centx, centy, label='centroids', s=15, c='darkblue', marker='x')
axes.legend(loc=2)
plt.title('lastDataSet', fontsize=20)
plt.xlabel("one feature ", fontsize=20)
plt.ylabel("two feature", fontsize=20)
plt.show()
except Exception,e:
print traceback.print_exc()
# 聚3个类
def lastDataSetShow3(x0,y0,x1,y1,x2,y2,centx,centy):
try:
fig = plt.figure(figsize=(8,5),facecolor='w')
axes = fig.add_subplot(111)
cluster0 = axes.scatter(x0, y0, label='cluster0', s=15,c = 'r')
cluster1 = axes.scatter(x1, y1, label='cluster1', s=15, c= 'b')
cluster2 = axes.scatter(x2, y2, label='cluster2', s=15, c= 'g')
cent = axes.scatter(centx, centy, label='centroids', s=15, c= 'darkblue',marker='x')
axes.legend(loc = 2)
plt.title('lastDataSet',fontsize= 20)
plt.xlabel("one feature ",fontsize = 20)
plt.ylabel("two feature",fontsize = 20)
plt.show()
except Exception,e:
print traceback.print_exc()
# 聚出四个类,画四个类别
def lastDataSetShow4(x0,y0,x1,y1,x2,y2,x3,y3,centx,centy):
try:
fig = plt.figure(figsize=(8,5),facecolor='w')
axes = fig.add_subplot(111)
cluster0 = axes.scatter(x0, y0, label='cluster0', s=15,c = 'r')
cluster1 = axes.scatter(x1, y1, label='cluster1', s=15, c= 'b')
cluster2 = axes.scatter(x2, y2, label='cluster2', s=15, c= 'g')
cluster3 = axes.scatter(x3, y3, label='cluster3', s=15, c= 'y')
cent = axes.scatter(centx, centy, label='centroids', s=15, c= 'darkblue',marker='x')
axes.legend(loc = 2)
plt.title('lastDataSet',fontsize= 20)
plt.xlabel("one feature ",fontsize = 20)
plt.ylabel("two feature",fontsize = 20)
plt.show()
except Exception,e:
print traceback.print_exc()
# 聚出5个类,画5个类别
def lastDataSetShow5(x0,y0,x1,y1,x2,y2,x3,y3,x4,y4,centx,centy):
try:
fig = plt.figure(figsize=(8,5),facecolor='w')
axes = fig.add_subplot(111)
cluster0 = axes.scatter(x0, y0, label='cluster0', s=15,c = 'r')
cluster1 = axes.scatter(x1, y1, label='cluster1', s=15, c= 'b')
cluster2 = axes.scatter(x2, y2, label='cluster2', s=15, c= 'g')
cluster3 = axes.scatter(x3, y3, label='cluster3', s=15, c= 'y')
cluster4 = axes.scatter(x4, y4, label='cluster4', s=15, c='teal')
cent = axes.scatter(centx, centy, label='centroids', s=15, c= 'darkblue',marker='x')
axes.legend(loc = 2)
plt.title('lastDataSet',fontsize= 20)
plt.xlabel("one feature ",fontsize = 20)
plt.ylabel("two feature",fontsize = 20)
plt.show()
except Exception,e:
print traceback.print_exc()
# 聚出6个类,画6个类别
def lastDataSetShow6(x0,y0,x1,y1,x2,y2,x3,y3,x4,y4,x5,y5,centx,centy):
try:
fig = plt.figure(figsize=(8,5),facecolor='w')
axes = fig.add_subplot(111)
cluster0 = axes.scatter(x0, y0, label='cluster0', s=15,c = 'r')
cluster1 = axes.scatter(x1, y1, label='cluster1', s=15, c= 'b')
cluster2 = axes.scatter(x2, y2, label='cluster2', s=15, c= 'g')
cluster3 = axes.scatter(x3, y3, label='cluster3', s=15, c= 'y')
cluster4 = axes.scatter(x4, y4, label='cluster4', s=15, c='teal')
cluster5 = axes.scatter(x5, y5, label='cluster5', s=15, c='brown')
cent = axes.scatter(centx, centy, label='centroids', s=15, c= 'darkblue',marker='x')
axes.legend(loc = 2)
plt.title('lastDataSet',fontsize= 20)
plt.xlabel("one feature ",fontsize = 20)
plt.ylabel("two feature",fontsize = 20)
plt.show()
except Exception,e:
print traceback.print_exc()
#这个是二维数据聚类后的损失函数
def lossCluster(lossx,lossy):
try:
plt.figure(figsize=(8,5),facecolor='w')
plt.plot(lossx,lossy,label="LossTrend",c = 'r')
plt.xlabel("x axis",fontsize= 15)
plt.ylabel("y axis",fontsize= 15)
plt.title("Loss",fontsize= 20)
plt.legend(loc=1)
plt.show()
except Exception,e:
print traceback.print_exc()
if __name__ == '__main__':
# '''需要修改聚的类的个数'''
# # 聚类个数
# K = 5
# #文件路径
# filePath = "../data/training_4k2_far.txt"
#
# dataSet = kmeans.loadData(filePath)
#
# # 画未聚类的图
# x = []
# y = []
#
# x = dataSet[:,0].tolist()
# y = dataSet[:,1].tolist()
#
# # preDataSetaShow(x,y)
#
# # 画出聚类后的图
#
# '''画质心'''
# centroids = kmeans.kmeans(dataSet,K)[0]
# print centroids
# cx = []
# cy = []
# # 命名得注意centy课能是不能用的 因为len(centy)为0
# cx = centroids[:,0].tolist()
# cy = centroids[:,1].tolist()
#
# # print len(cx),len(cy)
#
# '''画出聚的类的个数'''
# clusterAssment = kmeans.kmeans(dataSet,K)[1]
# # 创建一个列表来接受分类后的dataSet
# # ptsInClust = np.mat(np.zeros((K,2)))
# lastData = []
# for cent in range(K):
# # 将数据集合中所有属于当前质心类的样本通过条件过滤筛选出来,列表里有四个矩阵
# lastData.append((dataSet[np.nonzero(clusterAssment[:, 0].A == cent)[0]]))
# # print len(lastData[1][:, 0]),len(lastData[1][:, 1])
# # print len(lastData[2][:, 0]), len(lastData[2][:, 1])
# # print len(lastData[3][:, 0]), len(lastData[3][:, 1])
# # print len(lastData[0][:, 0]), len(lastData[0][:, 1])
# x0 = []
# y0 = []
#
# x0 = lastData[0][:, 0].tolist()
# y0 = lastData[0][:, 1].tolist()
#
# x1 = []
# y1 = []
#
# x1 = lastData[1][:, 0].tolist()
# y1 = lastData[1][:, 1].tolist()
#
# x2 = []
# y2 = []
#
# x2 = lastData[2][:, 0].tolist()
# y2 = lastData[2][:, 1].tolist()
#
# x3 = []
# y3 = []
#
# x3 = lastData[3][:, 0].tolist()
# y3 = lastData[3][:, 1].tolist()
#
# x4 = []
# y4 = []
#
# x4 = lastData[4][:, 0].tolist()
# y4 = lastData[4][:, 1].tolist()
# x5 = []
# y5 = []
#
# x5 = lastData[5][:, 0].tolist()
# y5 = lastData[5][:, 1].tolist()
# lastDataSetShow2(x0, y0, x1, y1, cx, cy)
# lastDataSetShow3(x0, y0, x1, y1, x2, y2, cx, cy)
# lastDataSetShow4(x0, y0, x1, y1, x2, y2, x3, y3, cx, cy)
# lastDataSetShow5(x0, y0, x1, y1, x2, y2, x3, y3, x4, y4, cx, cy)
# lastDataSetShow6(x0, y0, x1, y1, x2, y2, x3, y3, x4, y4, x5, y5, cx, cy)
'''画出loss函数'''
lossx = []
lossy = []
lossx = [2,3,4,5,6]
lossy = [859.539169,491.82270747,134.70451691,115.35163924,103.16034334]
lossCluster(lossx,lossy)
这是一个标准的二维数据测试集training_4k2_far.txt:
2.7266 3.0102
3.1304 2.4673
3.0492 2.525
3.226 3.1649
2.7223 2.5713
3.2862 2.8255
3.111 3.2994
3.2398 2.9681
2.8661 2.5533
3.2616 3.4902
1.99 3.2137
2.7017 2.61
3.0131 3.5208
2.8395 2.6816
2.9831 3.1657
3.7537 2.6608
3.0544 2.6474
3.3826 3.2356
3.2362 3.1535
3.0911 2.7883
2.4905 2.8723
2.8458 2.7137
2.7267 3.1528
3.1643 3.0671
3.3906 2.3585
2.1004 3.0724
2.8911 3.2043
2.6157 2.1725
3.1961 3.1735
1.7841 3.0763
3.4923 3.4455
3.4772 3.3968
3.3189 3.5495
3.2798 2.1895
2.2937 3.3527
2.8161 3.2286
2.3536 3.5656
3.3436 2.9659
3.0465 2.5304
3.9403 3.0006
2.9572 2.5322
3.1434 2.7548
2.9806 3.0031
3.6446 2.7736
2.8164 3.6278
3.4821 4.0864
3.6661 2.6847
2.3413 3.4814
3.2312 2.7373
2.6234 2.5361
3.2563 2.973
2.8906 2.0936
3.1462 3.7418
2.6438 2.7712
3.5794 2.373
2.3408 3.4678
2.9322 3.1776
3.2282 3.4508
2.8451 2.6851
3.1893 2.7909
2.7477 2.3049
2.5491 3.6024
3.3117 3.0164
3.0925 3.1162
2.884 2.7418
3.118 2.6412
3.4545 2.0397
2.4624 3.095
2.5876 2.6469
3.0391 3.5873
2.6821 3.3018
1.9979 2.7849
3.6046 4.4167
2.8052 2.3741
3.3704 3.5485
2.5016 2.8316
2.4297 2.3209
3.5564 2.5427
2.8552 2.5938
2.5227 2.2445
3.6131 3.0072
3.5096 3.6762
2.8118 2.9116
3.4572 3.1999
3.2817 2.5862
3.1585 2.6506
3.3324 2.3196
3.282 3.3363
2.9604 3.1444
2.7604 2.7121
2.953 2.5977
2.518 3.3706
3.1038 3.2042
2.6108 3.2932
2.7133 3.5879
3.022 3.2819
3.2887 3.6587
2.7811 2.5675
3.1395 2.8455
2.8075 2.9971
2.5235 3.3553
3.3622 3.1813
2.6712 4.1989
3.1562 3.9358
2.9157 3.2074
2.3513 2.7011
3.2596 2.7134
2.7007 2.8752
3.0785 2.813
3.5539 2.7665
3.4948 2.4448
3.4598 2.0789
2.4891 2.8472
3.3896 2.505
2.5973 2.8949
3.5049 3.6834
2.559 2.9035
2.1629 3.0291
2.5993 2.5164
3.1497 3.167
2.7022 3.2358
3.0475 3.2566
3.2959 3.3595
2.8036 2.3961
2.9221 3.2034
3.097 3.7377
2.7234 3.4401
2.6777 2.7403
2.1883 2.8882
3.0051 3.3939
2.7537 2.5876
2.6726 3.4831
3.3822 2.4474
2.6018 2.4145
3.2896 3.308
2.7854 2.3219
2.574 2.3544
2.7345 2.6018
4.2289 3.058
2.6282 3.4221
3.3936 3.1938
2.4638 3.8204
3.0994 2.4435
3.508 3.7114
2.6488 2.0721
2.2956 3.4115
1.8437 3.1186
2.83 2.7157
2.7668 3.8732
7.4256 8.266
8.703 7.4874
8.4307 7.7491
8.0501 8.6516
8.5896 8.4566
8.0519 8.3274
8.4173 7.5257
8.579 7.8808
8.0708 7.9862
8.0786 8.4343
8.2881 8.821
8.2579 7.8648
7.5377 7.2675
7.7397 7.5936
8.3348 7.9979
8.0718 8.6614
7.3806 8.1896
7.6868 7.733
8.2079 7.3411
7.7795 7.8079
9.2059 7.8076
8.5043 8.3472
7.4194 7.2467
7.6992 7.892
7.9446 7.872
7.2857 7.1511
8.0719 8.0038
8.2507 7.8614
8.4375 7.5687
7.9359 7.9991
8.0518 8.7005
8.2761 7.984
8.7712 7.7401
7.9218 7.7272
8.475 7.9472
8.3559 8.2356
8.6742 7.5134
7.6074 8.1905
7.8984 8.1305
8.0892 7.6176
8.4908 8.1264
7.2717 7.2312
7.6027 7.9745
8.6869 8.1516
7.3566 8.2209
8.0468 8.8111
8.2436 7.4516
8.7382 8.6116
7.7793 8.0716
7.9856 8.3365
8.8393 7.5225
7.8965 7.8471
8.5374 7.8589
8.7422 8.0283
8.3421 8.6652
7.8882 8.2419
7.9541 8.6037
8.3586 8.0111
7.853 7.6305
8.0515 8.1975
8.497 8.0638
8.8102 7.2967
8.4419 7.8188
8.2358 7.6146
8.1958 7.9179
8.1346 7.4925
7.0101 8.7125
8.2017 7.9962
8.1583 8.3481
8.1205 7.9192
7.6749 7.6971
7.5198 8.2414
7.7911 8.4015
7.8028 8.2066
8.3084 7.3386
7.756 7.919
8.0038 8.0903
7.8845 7.1217
7.7541 7.8179
7.3147 8.3037
8.0674 8.2433
7.8393 8.482
8.1533 8.1583
7.8958 7.3012
8.0175 8.4396
7.6834 7.5814
8.6523 8.0479
7.6882 7.7331
7.8279 8.0414
7.6931 7.7269
8.2605 8.4346
7.6377 7.6857
8.2584 8.5359
8.0147 8.0012
8.7019 7.5311
7.405 7.5773
7.4772 7.7605
8.2869 8.7212
8.5142 6.4754
7.8035 8.2711
8.9912 8.1837
8.2268 8.7324
7.9031 7.3747
8.7893 8.3092
8.1417 7.9259
8.2175 7.8444
8.6563 8.506
7.6683 7.4926
8.6393 7.0973
8.5349 7.8904
7.8057 8.3872
8.3471 7.6245
7.8746 7.8769
8.3337 7.8474
8.0863 8.2693
7.7654 7.836
8.3298 8.5828
7.8341 7.3557
7.0727 8.0753
8.6399 7.0368
7.9424 7.8251
8.0321 7.0214
8.4529 8.317
8.7172 7.8672
7.3876 8.1845
8.6239 7.6609
8.502 8.2946
7.5958 8.3769
8.3163 8.0605
7.7711 8.05
8.8454 8.4523
8.4656 8.4876
8.604 7.6903
8.2437 7.8624
7.6448 8.5157
8.3876 8.3474
7.9066 8.2761
7.7884 7.1085
7.5304 7.6864
8.518 9.0936
7.3841 7.5885
7.8675 8.1986
8.1031 8.0378
7.9853 7.8377
7.0016 8.2089
8.5393 8.3508
7.2779 8.4457
3.2709 6.1369
2.9987 5.9714
2.5602 5.9316
2.9639 6.0448
3.2984 6.1485
3.2752 6.3167
3.5049 6.3118
2.9292 6.2216
2.7027 5.855
2.891 6.0381
2.9622 6.3197
3.3382 6.3632
3.0187 5.7204
3.0559 6.5856
2.7205 5.865
2.6009 6.1153
2.7392 5.6576
3.1698 6.0758
3.3396 6.3712
2.9096 5.522
3.105 6.1714
2.9602 6.1118
3.4558 6.1802
2.8195 5.5693
3.1139 5.8101
3.0492 5.9645
3.451 5.7826
3.3912 6.195
2.8793 5.9447
2.9069 6.069
2.5756 5.6331
2.9775 6.2627
2.6917 5.5368
3.0577 6.0647
2.7511 5.8085
2.535 5.0883
2.3498 6.2257
3.011 6.413
3.1564 6.3013
2.7182 5.9668
2.7663 5.8458
2.4842 5.7768
3.4016 5.8005
3.5514 5.8075
3.356 5.8858
3.1057 6.3061
3.4432 5.9784
3.541 5.8704
3.1079 6.0222
2.9206 6.4314
2.8793 6.2424
3.1371 5.6366
3.2722 6.1326
6.6044 5.4906
6.8257 4.8702
7.0364 4.8652
7.2246 4.74
7.1077 5.4081
6.6286 5.0261
6.8289 4.9542
6.4988 4.8895
6.811 5.1143
6.5591 4.817
7.0664 5.1008
6.81 5.2355
7.5544 5.1802
7.1528 4.8791
6.4411 5.2578
6.7477 4.8343
7.4801 4.8656
6.2978 4.3821
6.7147 5.4213
6.4965 4.8323
7.4137 4.5293
7.2749 5.2806
7.543 5.2511
6.7118 5.2895
7.1741 5.2429
6.914 5.0772
7.5856 5.3146
6.7756 5.1347
7.4576 4.4974
6.7791 6.0667
7.3444 4.9963
6.8172 5.011
6.6711 4.8114
7.1353 5.3525
6.5235 5.2443
6.8068 5.5866
6.8967 4.8194
7.5556 4.6326
6.842 4.7881
6.8945 5.2523
7.3522 5.1422
7.0194 4.9704
7.4171 5.1301
6.6505 4.891
7.2328 4.8636
7.4017 4.7617
7.6063 5.0272
7.2716 5.0681
6.7997 5.3631
6.8852 5.1578
7.0737 5.0648其结果如下:
k=2:
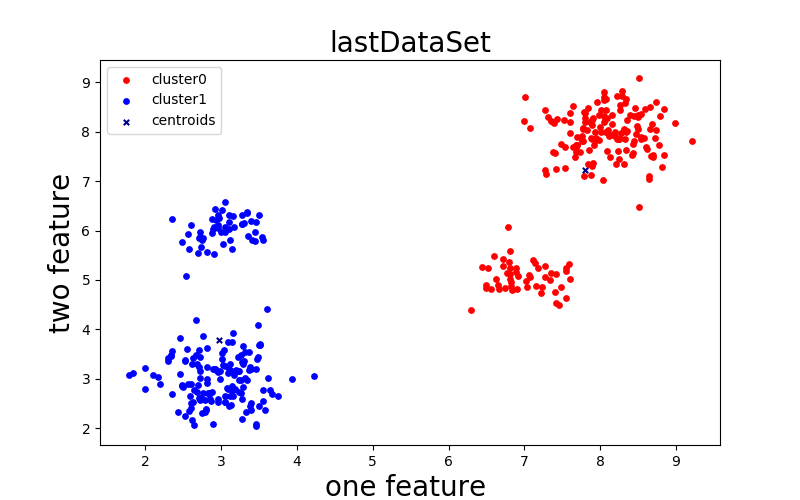
k=3:

k=4:
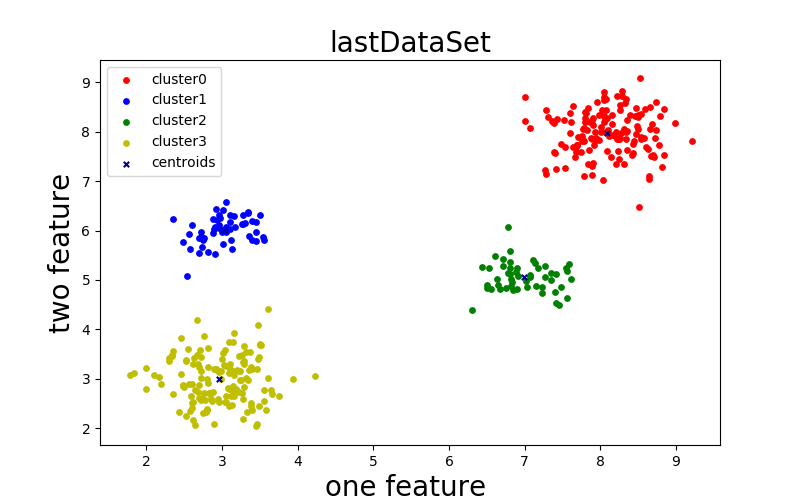
k=5:
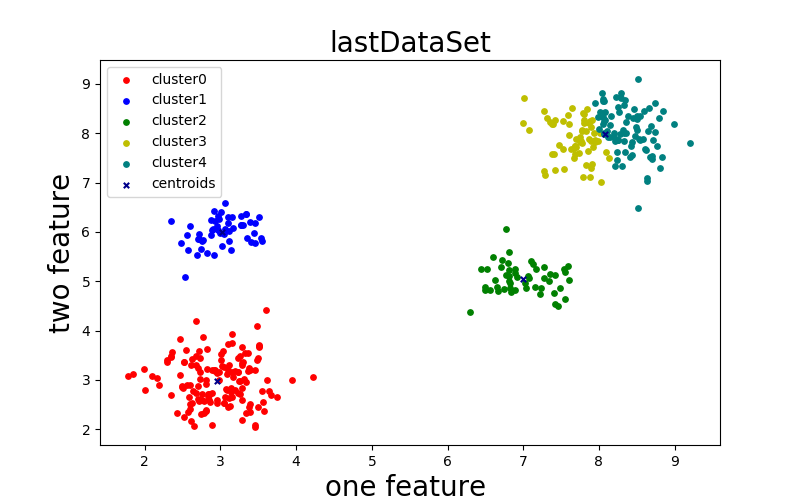
k=6:

其损失的图像为:
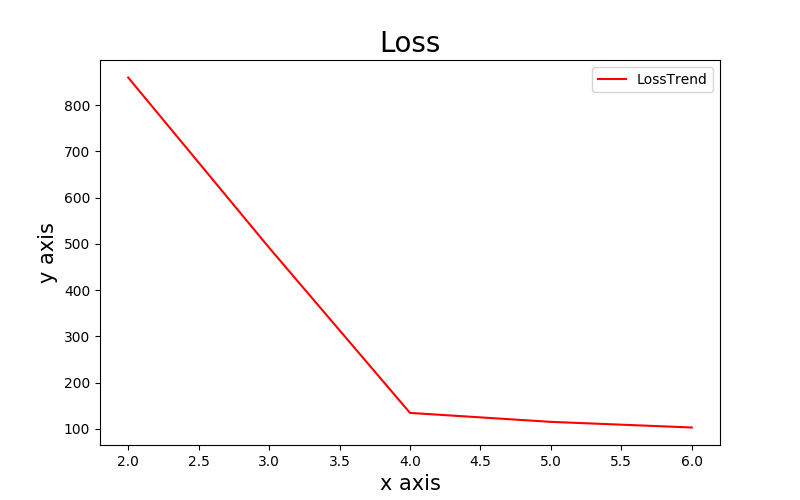
横坐标是聚的类的个数,纵坐标为损失值,这可以很清楚的看出其肘点为k=4,这时候损失值几乎不变,也可以说这个数据集分4类是最合适的,那么对于更高维度的数据不能画出其聚类图像,这样就只能从损失函数中来看该数据集应该分几类了。
到此为止也就结束了,希望对大家有所帮助,在这里感谢一位学长,感谢他一直对我的指导以及对我的帮助,非常感谢!














 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









