







>> 返回函数,闭包,匿名函数
当返回一个函数时,该函数并未执行,返回参数中不应该引用任何可能会发生变化的变量或者可以循环改变的变量,当实际调用函数时,需要在后面加().

Lambda 的使用:
如果一个函数内包含lambda(即上图中的f1,即函数f1中嵌套了lambda函数):则lambda冒号前是内层函数g(x)的变量,内层函数可以不定义变量。冒号后面是内层函数的函数表达式,内层函数g(x)表达式可以引用上层函数f(x)的变量,
如果函数本身便是lambda函数:如 f= lambda a,b: a+ b,则a,b即为函数本身的参数,因为只有一个函数,没有嵌套函数。


F1中参与计算的是内层函数的x和y,即lambda中冒号前面的x和y,外层函数的即f1(x,y)中的x,y实际不参与计算,根据变量作用区域的规则,参与计算的是内层函数的x和y

>>本地作用域和全局作用域使用相同变量名的变量,使用全局变量时采用 _main__.variable

>>判断函数的参数是否 是 一个函数, 使用内置函数 callable , callable(s) 根据返回值是True or False 判断变量类型是否是函数, 或者import types type(a) == types.FunctionType。
>>装饰器:参考如何理解Python装饰器?
1)装饰器函数本身不需要参数
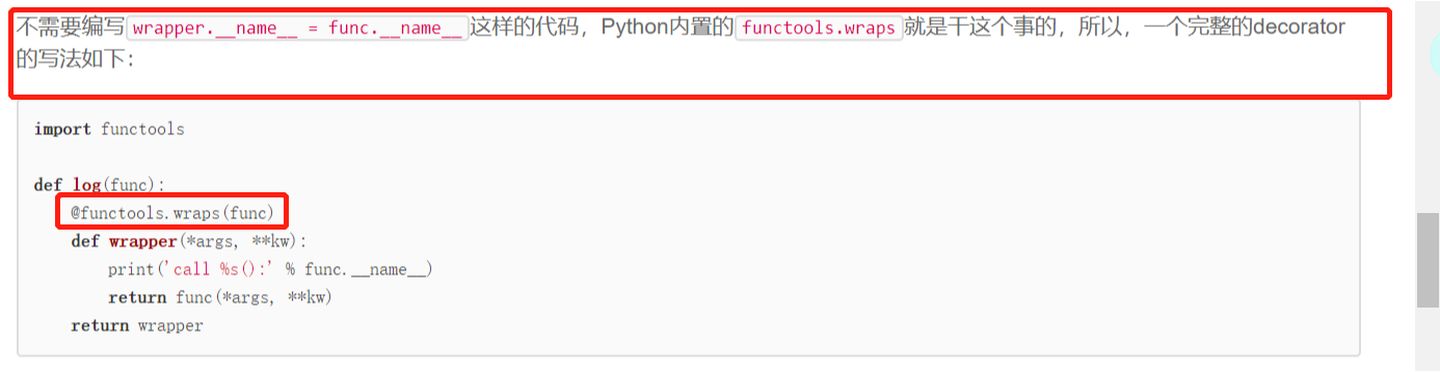
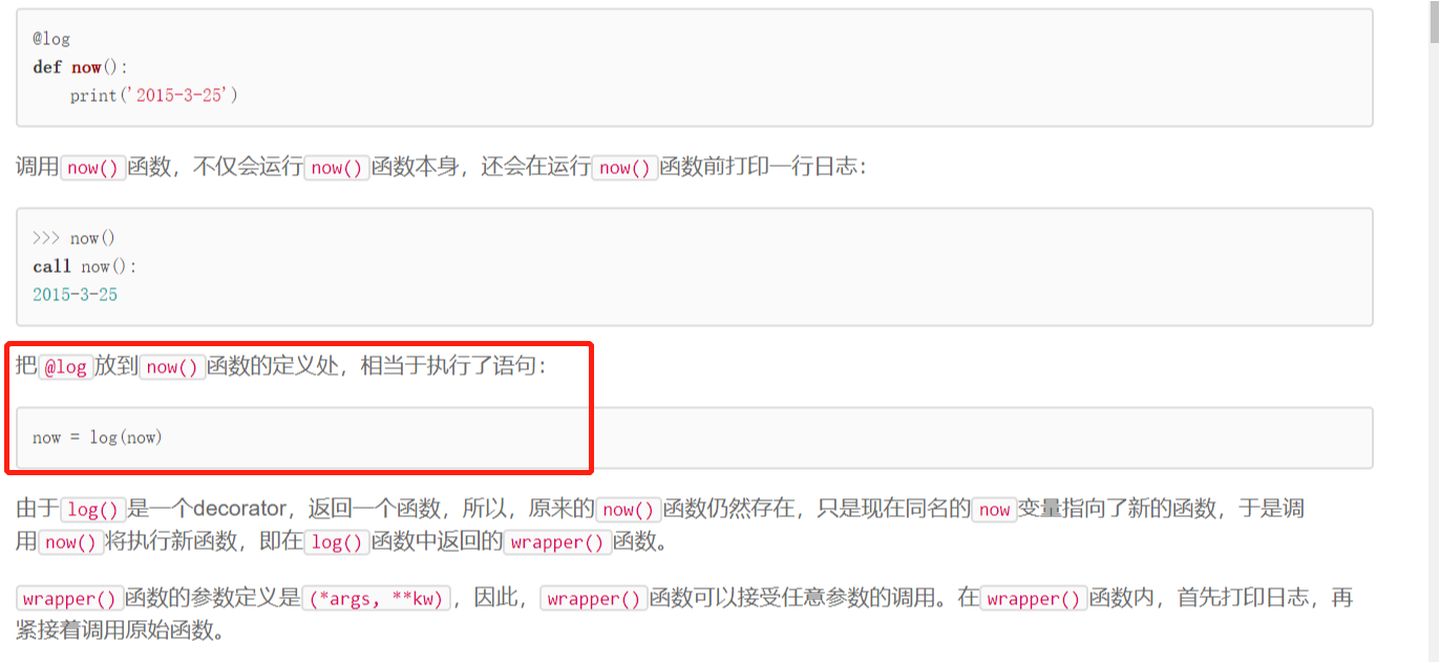
2)装饰器本身需要带参数的
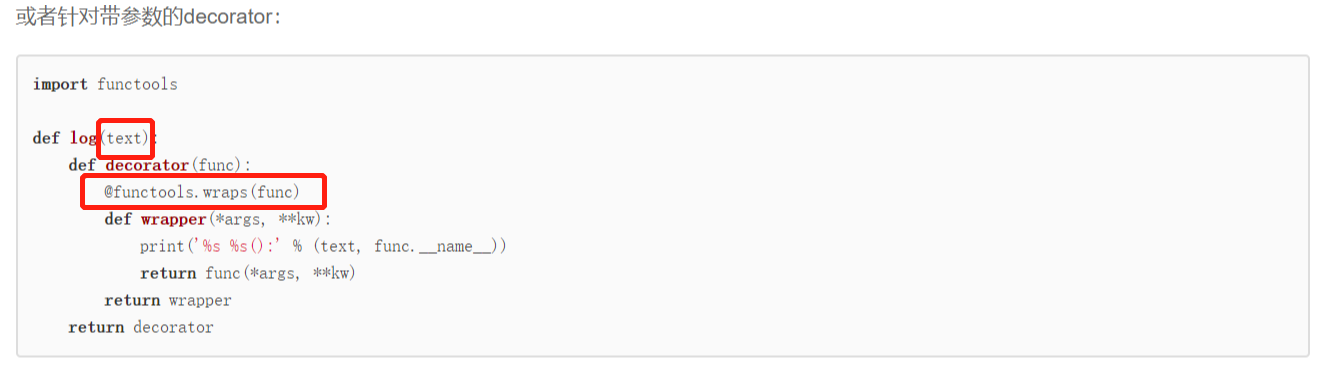
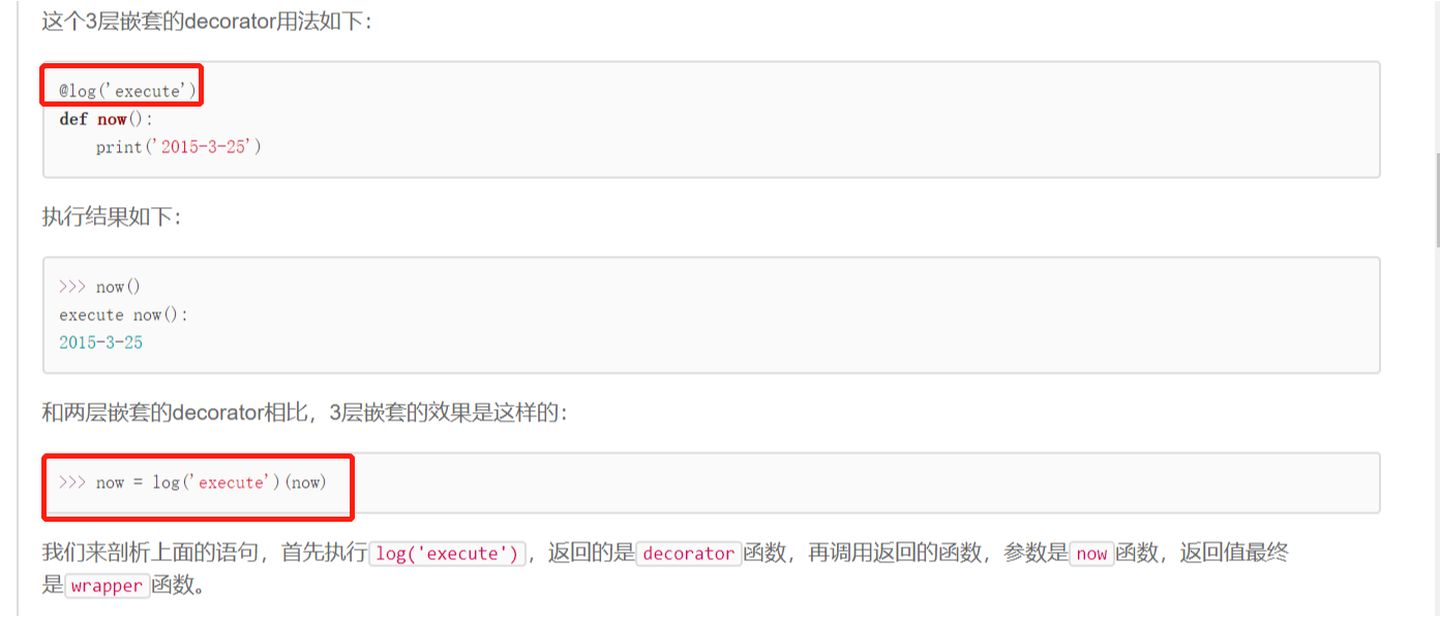
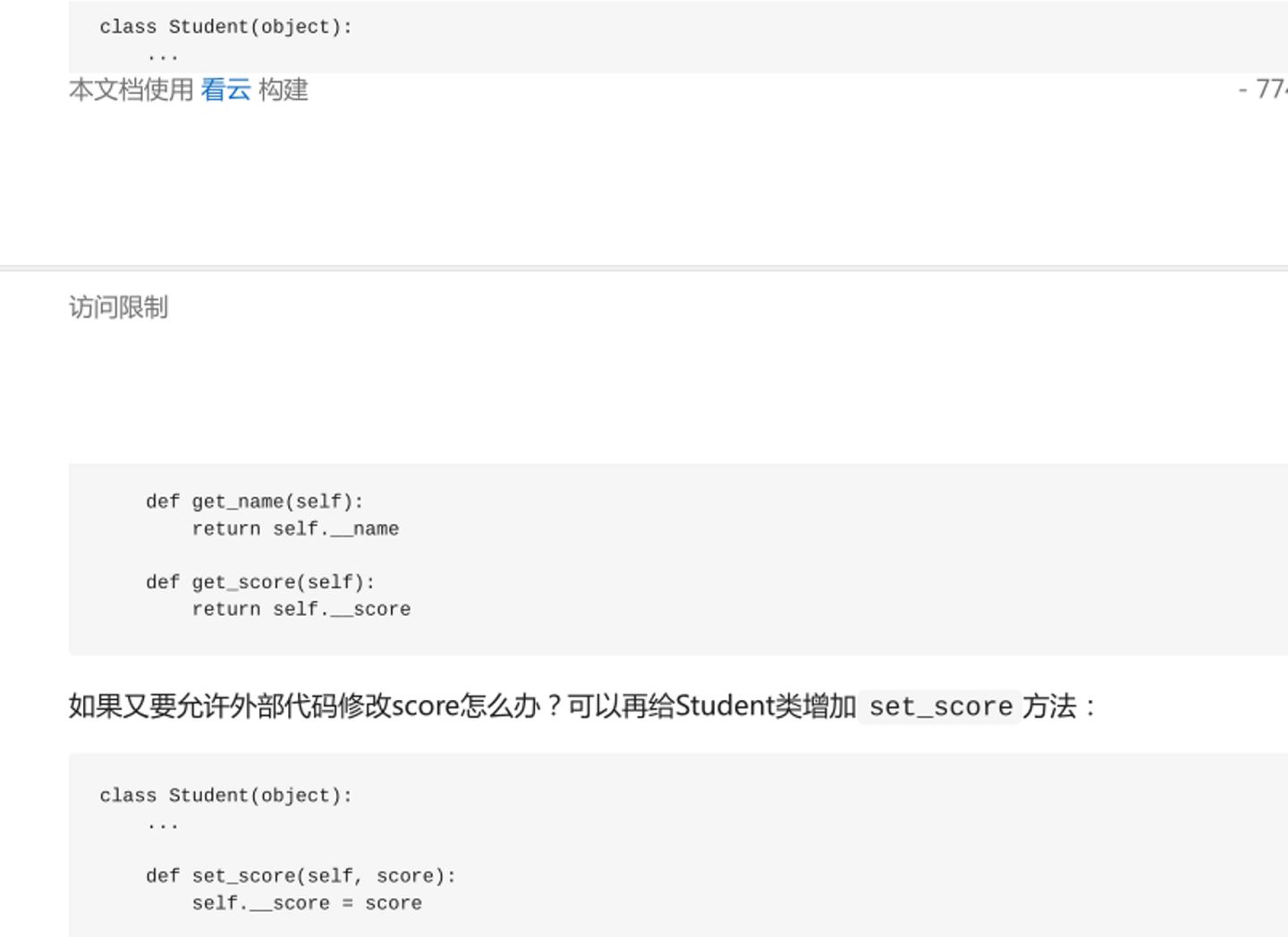
>>类中的变量:
私有变量:

如果想要访问或者修改类中的私有变量,则需要单独在类中设置方法对私有变量访问和修改,调用该方法。
>>给类和类的实例绑定方法:
1)给实例绑定方法用 methodtype
2) 给类绑定方法,用 class_name.function_name = function_name,即直接给类的方法赋值即可

>>三种类方法: self staticmethod classmethod
参考:
python中@classmethod @staticmethod区别www.cnblogs.com
Python 中的 classmethod 和 staticmethod 有什么具体用途?www.cnblogs.com
Python 实例方法、类方法和静态方法blog.csdn.net
Python静态方法和类方法深度总结_IT晓可程序员之路-CSDN博客_python类方法和静态方法blog.csdn.net
Python 实例方法、类方法、静态方法的区别与作用www.cnblogs.com
>>python中的递归和尾递归优化


>>filter 函数:
使用filter函数筛选素数:
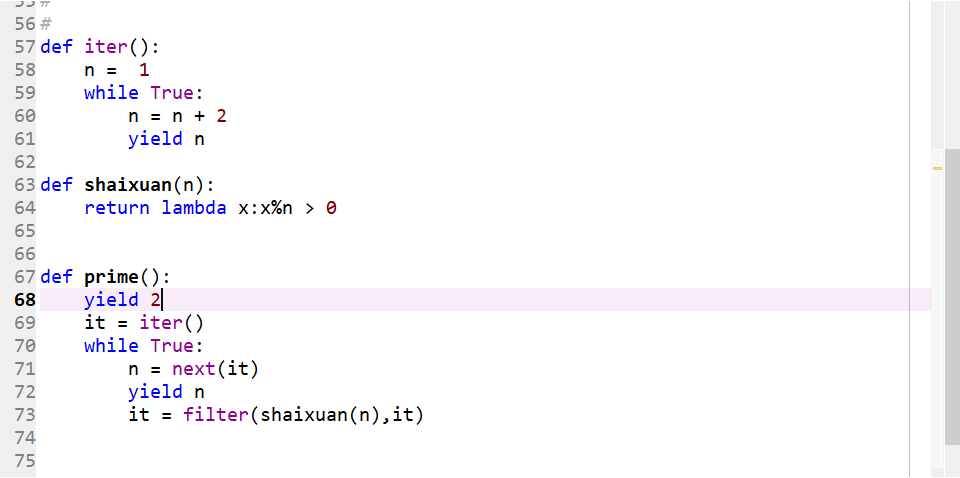
筛选函数在调用时,第一个参数为n,第二参数为x,如第二幅图所示。 筛选函数 _not_divisible 函数中使用了匿名函数即匿名函数中也是用了一个参数 n, 在filter(_not_divisible(n), it) 中,_not_divisible(n)实际是返回一个函数,而这个函数是由lambda方法表示的匿名函数,该匿名函数的参数是x,即lambda中冒号前面的参数。而要调用执行lambda必须要给x赋值。因此fileter函数实际将 可迭代对象中的每一个值赋值给lambda函数的x变量,相当于 _not_divisible(n)(i) for i in it

>>reduce函数:
将包含小数的字符串转化为float。

>>生成器
生成器和普通函数的执行流程是不同的,函数是顺序执行,遇到return语句或者最后一行函数语句就返回。而变成generator的函数,在每次调用next()的时候执行,遇到yield语句返回,再次执行时从上次返回的yield语句处继续执行。

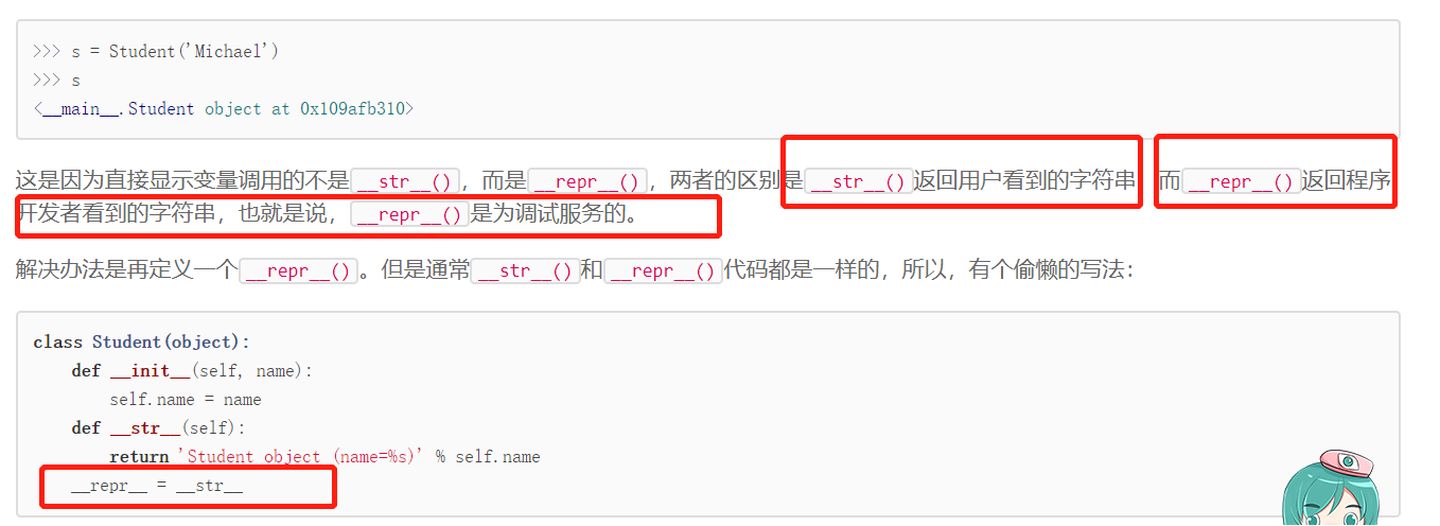
>>运算符重载
_str用于print变量展示,_repr_用于直接显示变量

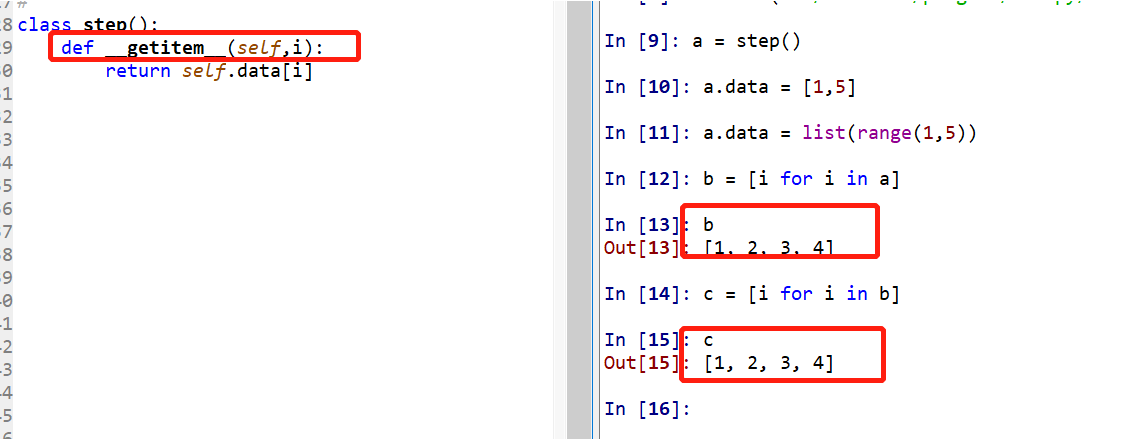
__iter__和 __next__
__Iter__通过列表生成器循环一次后,原对象变为空。而__getitem__可以循环多次,见下两图


通过调整__iter__方法返回的对象,可以改变成多个活跃迭代
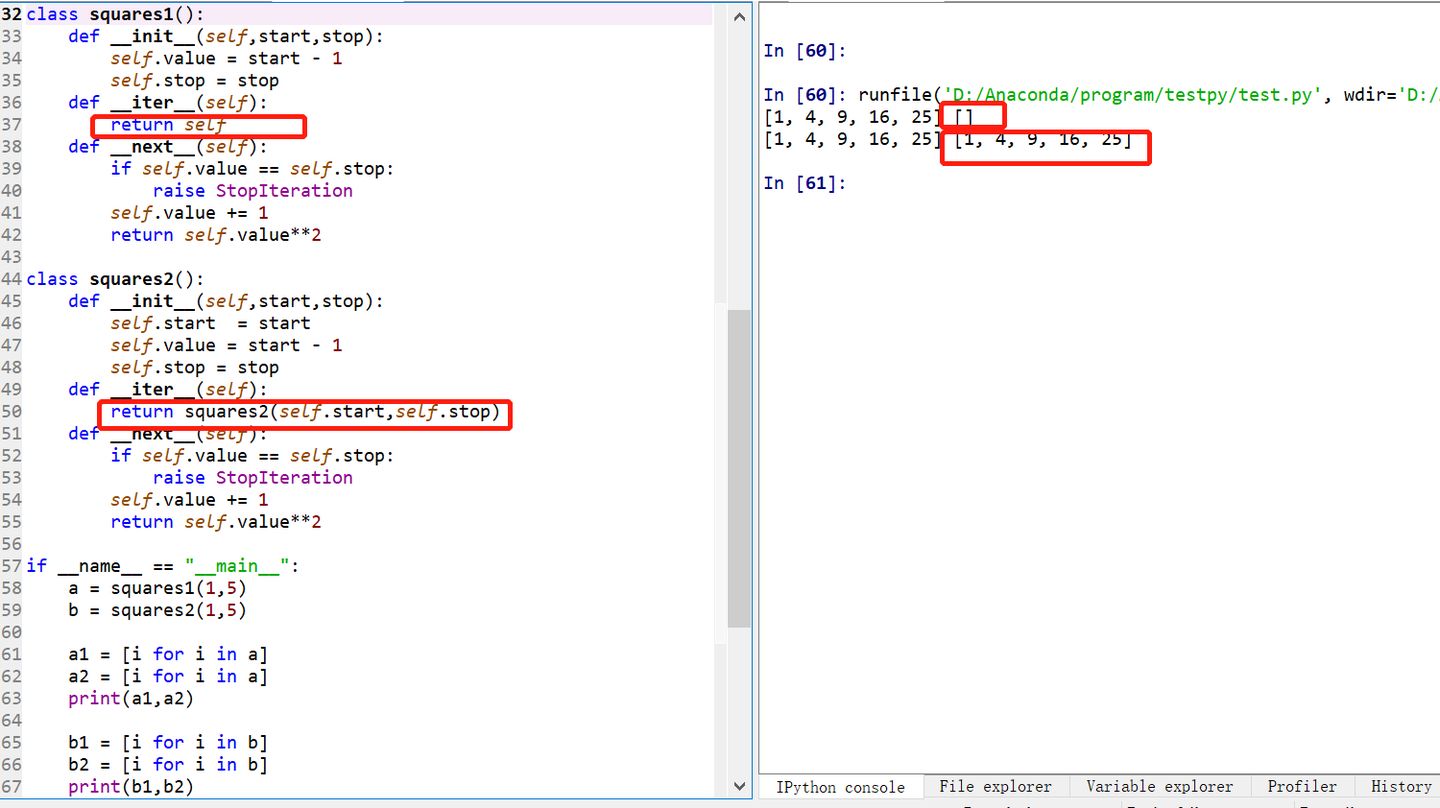
__contains__ __iter__ __getitem__:如果有__contain__方法,在判断 in 的代码时,会调用 __contain__方法,如果不存在,调用__Iter__和__next__方法迭代,如果前两者都不存在,最后调用 __getitem__方法遍历。



__getattr__ 和 __setattr__



通过 __setattr___设置私有属性,不允许修改:

__bool__ 和 __len__: 先调用 __bool__方法判断,如果没有,则调用 __len__方法判断

_getattr__和__getattribute__:
1)__getattr__只适用于未定义的属性,并且前提是类中未定义__getattribute__的情况下。拦截未定义的属性,调用__getattr__方法,返回相应的值
2)__getattribute__用于拦截所有属性的调用,即所有 instance.shuxing和instance.method都会调用该方法,如果该方法中出现self.shuxing 或self.method。则会导致再次调用__getattribute__方法,导致递归调用,最终导致堆栈溢出出错。因此要用父类的方法调用才可以。在类中如果同时设置__getattr__和__getattribute__方法,在访问未定义属性时,首先会访问__getattribute__方法,然后会访问__getattr__方法。前提是__getattribute__方法返回相应的获取属性的方法。

上图中的return object.__getattribute__(self,name) 可以换为return super().__getattribute__(name),结果相同

>>_dict_方法
对于实例而言,只会显示实例自身的属性,不包括从父类继承的属性。如果要获得所有的属性和方法(包括继承父类的的属性和方法),使用dir函数。
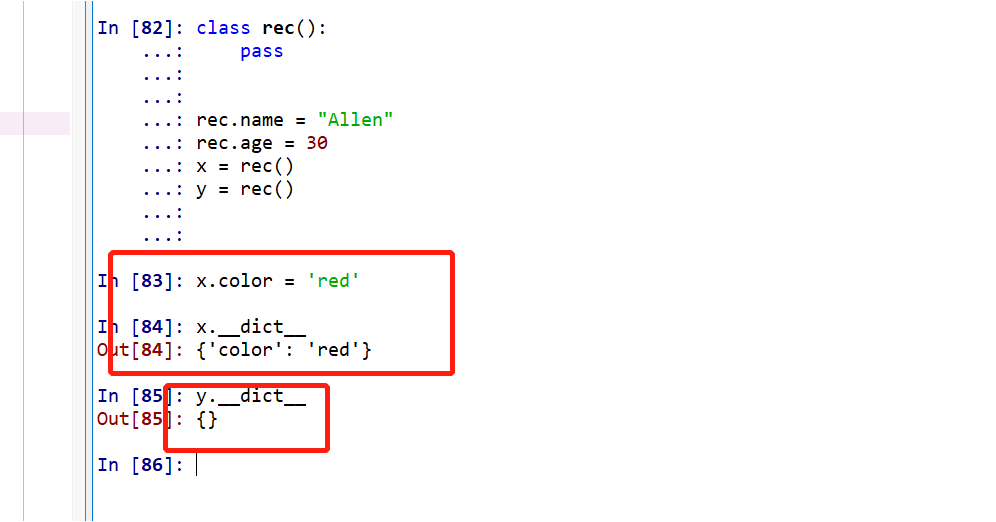
对于类而言,只会显示该类的属性,不包括从父类继承的属性,下图的类a3的__dict__方法并没有包含父类a1和a2的data1和data2属性
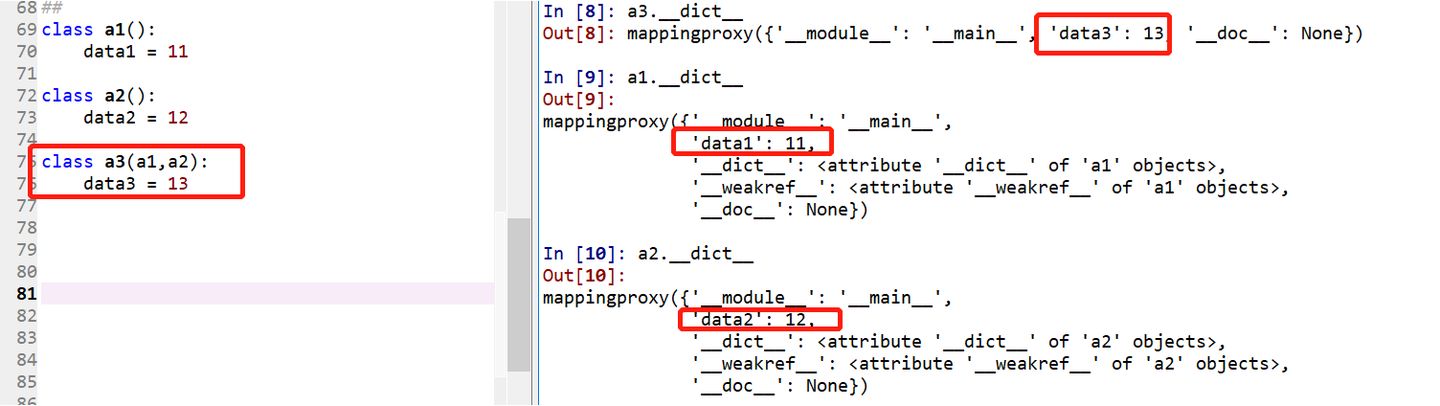
>>重构父类构造函数的两种方法
左图中的方法是parentclass.__init__(self,)直接指明父类名,简洁明了,如果是要继承多个父类的方法,则需要手动多次调用。
右图中的方法是super(子类名,self).__init_()等价于super().init_()


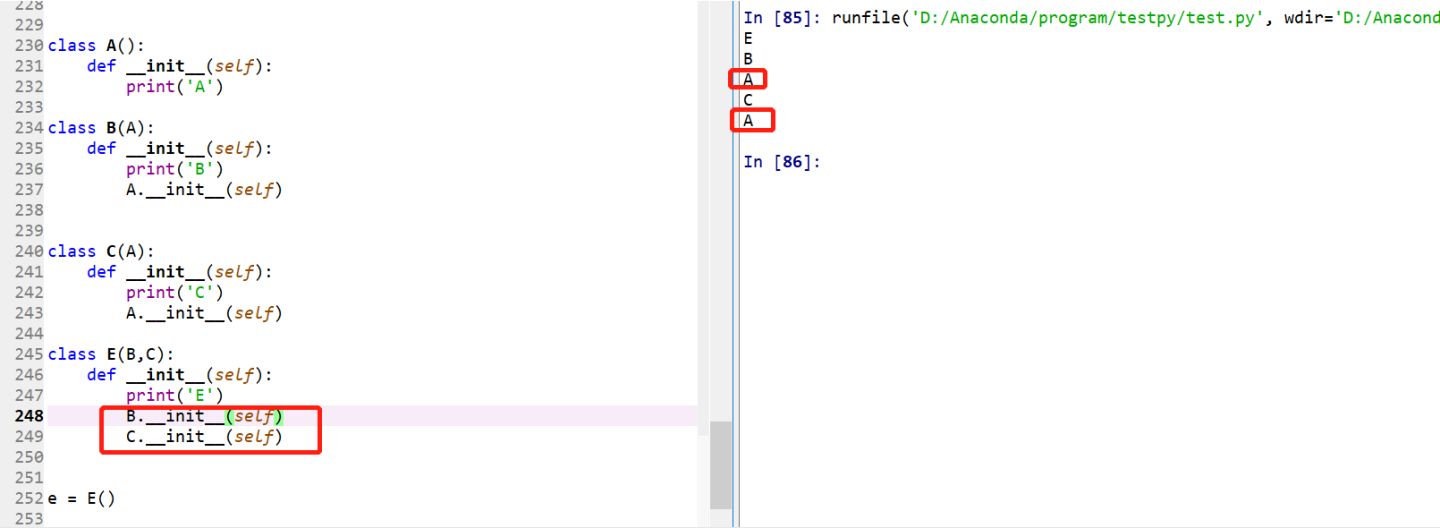
方法1:Super()._ _ init_ _(variables) 等价于 super(子类,self).__init__(variables)(下图中分别对两种方法做了测试。)。如果有参数,则调用时也应该传入参数,如下图可以看出,调用super时不但会搜索父类,也会搜索同位置的兄弟类。类E调用了父类B和C的两个类的构造函数,值得注意的是,虽然B和C都是继承A,但是在E搜索并调用父类构造函数时,A的构造函数只执行了一次。即下图中只输出了一次“A”。这是区别于第二种方法

方法2:父类.__init__(self,variables)如果分别调用父类B和C的构造函数,此时输出时发现输出了两次“A”
>>关于range生成倒叙序列:
关于range参数的用法 range(start,stop,step),如果是获得正序的数组,start < stop且step为正,如果是获得倒叙即从大到小的序列则start > stop,step应该负。注意:无论是start 和stop的大小关系如何,step默认均为1。所以在start > stop的情况下会得到空序列,无法输出,见下图。即在start > stop时,一定要指定step。

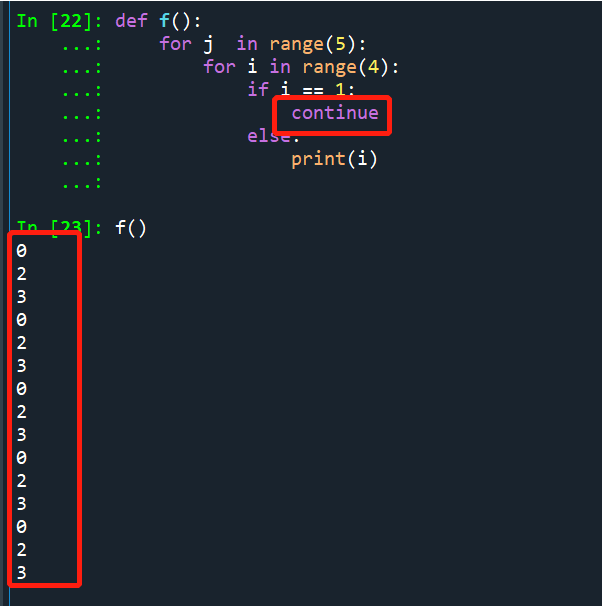
>>关于break continue return 跳出循环的区别:
continue只是对后面的语句不执行,继续执行该层循环的下一个值
Break 是结束该层循环,即该层循环下i= 2 3 时都不执行,追溯到上层循环的下一个变量值即j
return是直接返回,跳出当层函数

>>python中路径搜索的顺序。分别在程序主目录、内置库的文件夹(anaconda/lib)、环境变量路径(anaconda/program)、pth文件(my_package)同时设置string1.py文件,然后分别测试执行顺序。经测试的执行顺序是:
(1)程序主目录 (2)内置库文件 (3)环境变量路径 (4)pth文件添加的路径
但是尽量不要设置同名模块。
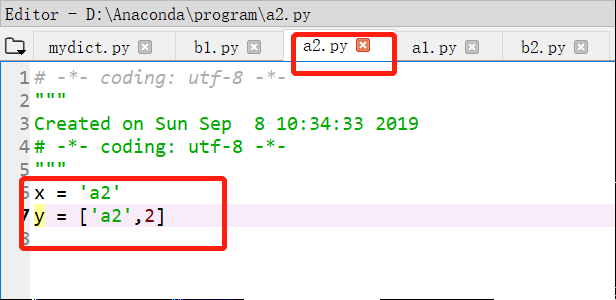
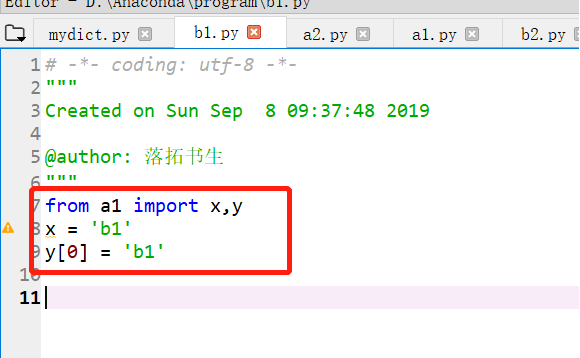
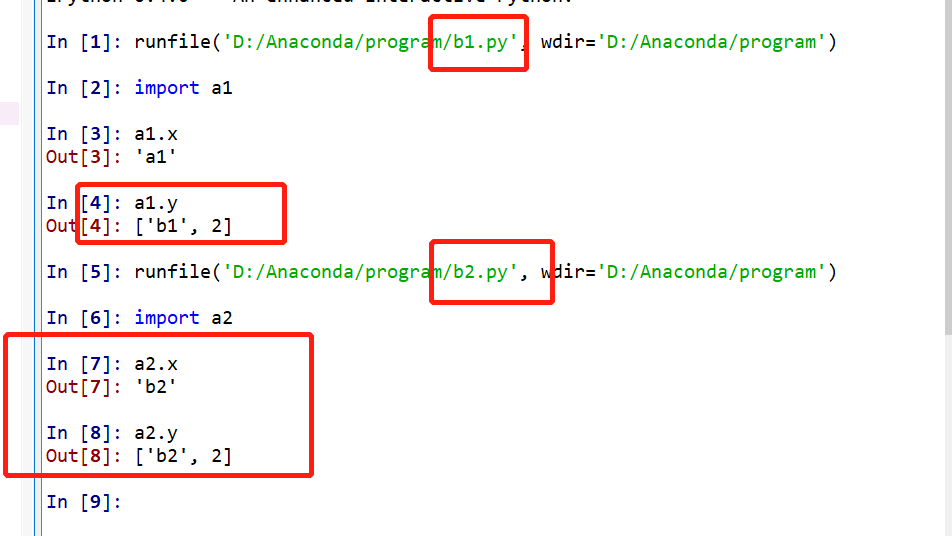
>>导入模块变量并修改,两种方式的差别:
下面是对导入模块的变量的两种修改方式的不同:
b1和b2的修改方式不同,b1是导入变量,对变量修改,b2是导入模块,对模块.变量修改。
b1的修改方式只有y发生了修改,因为y是列表为可变对象
b2的修改方式,x,y为均发生了修改。
因此如果要对其他模块中的变量进行修改并且希望在脚本运行期间其他脚本对该模块的引用时使用修改了数值,则采用b2的修改方式。


>>from import 和import的区分:


>>模块导入
对于如下三个文件。在test3中不能使用 Import test2.test1,必须是在代码语句中使用test2.test1 。点号操作时包导入(目录导入),因为test2和test1不是文件夹,没有__init__.py文件,所以不能在import中使用点号操作。
即如果是包导入(目录导入,即相应文件夹下有init文件),可以在import语句中使用点号操作;如果不是包导入,只能先import module,然后在代码中使用module.func等等
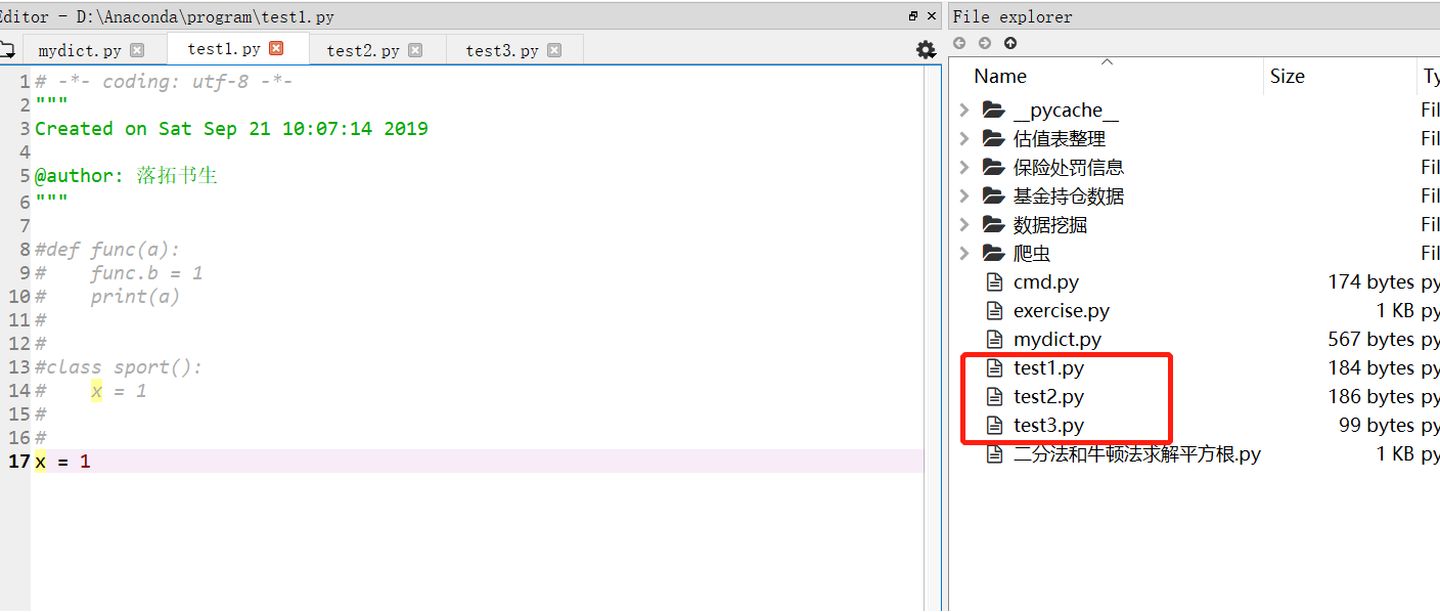
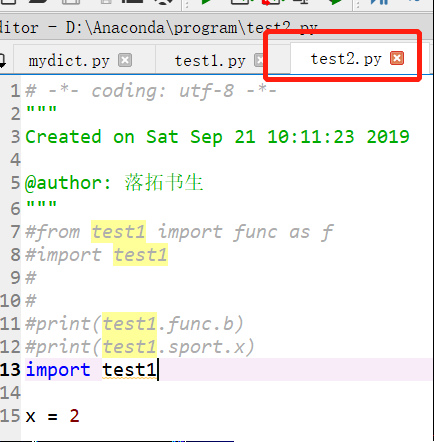
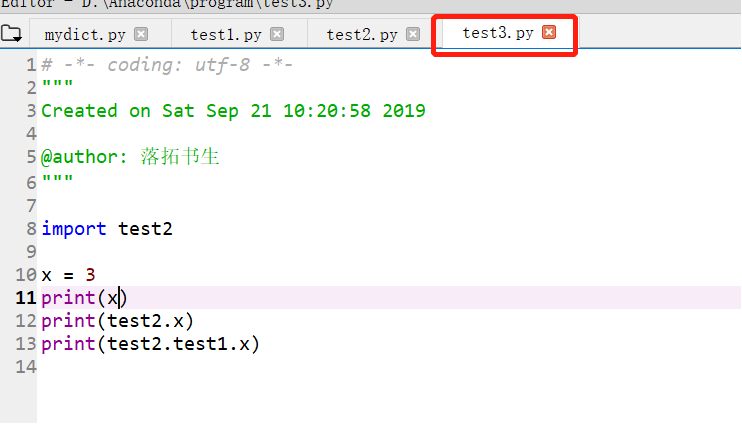
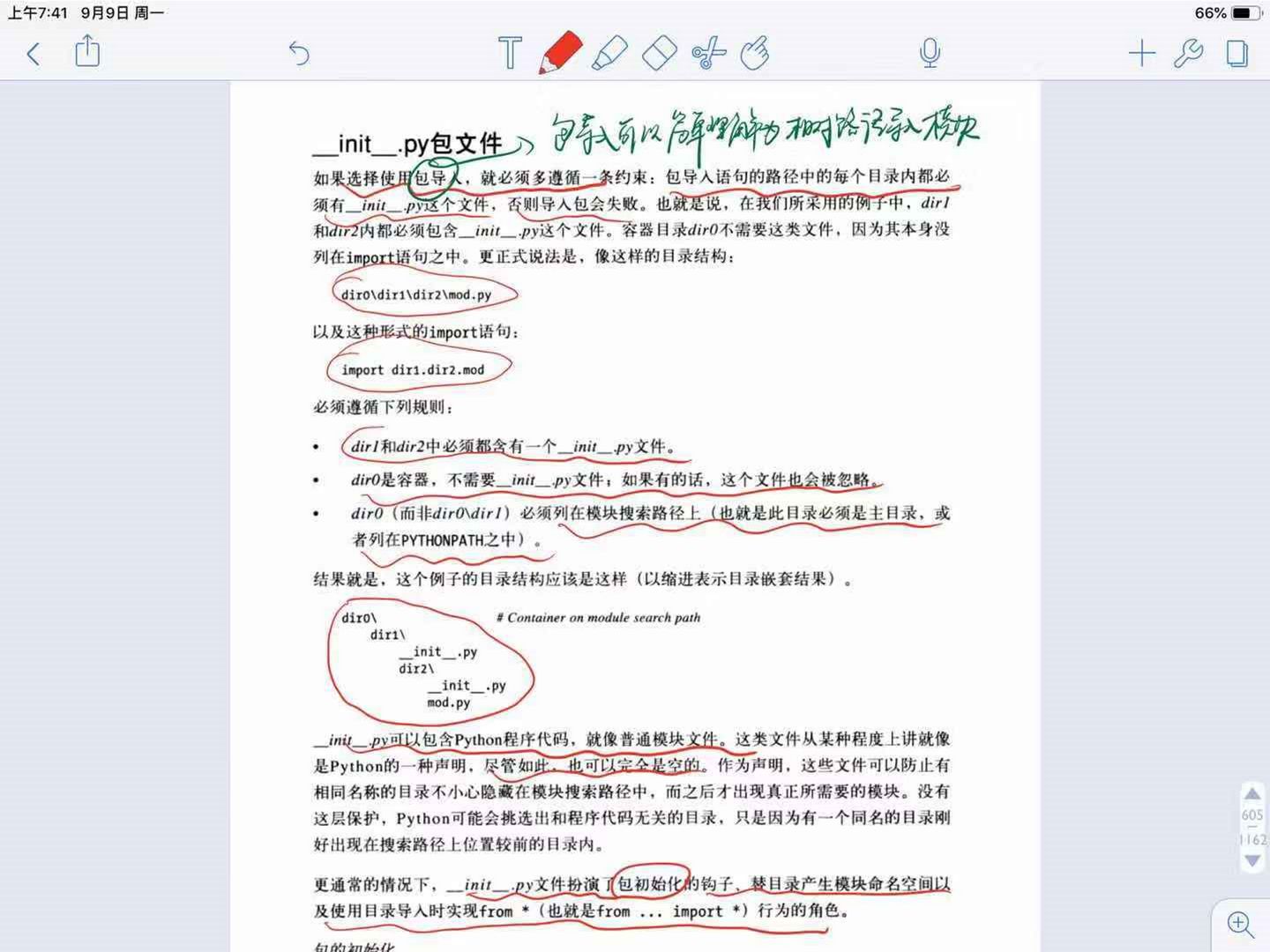
>>包导入(目录导入)
1)当前工作文件所在目录的子目录 。下图工作目录为D:\,test file为工作目录的子目录,所以直接可以import导入,dir1为工作目录的孙目录(即D子目录test file的子目录),所以不能直接import
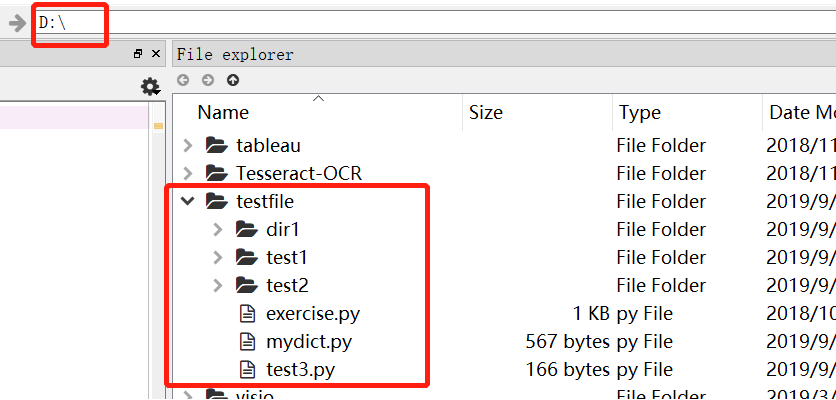
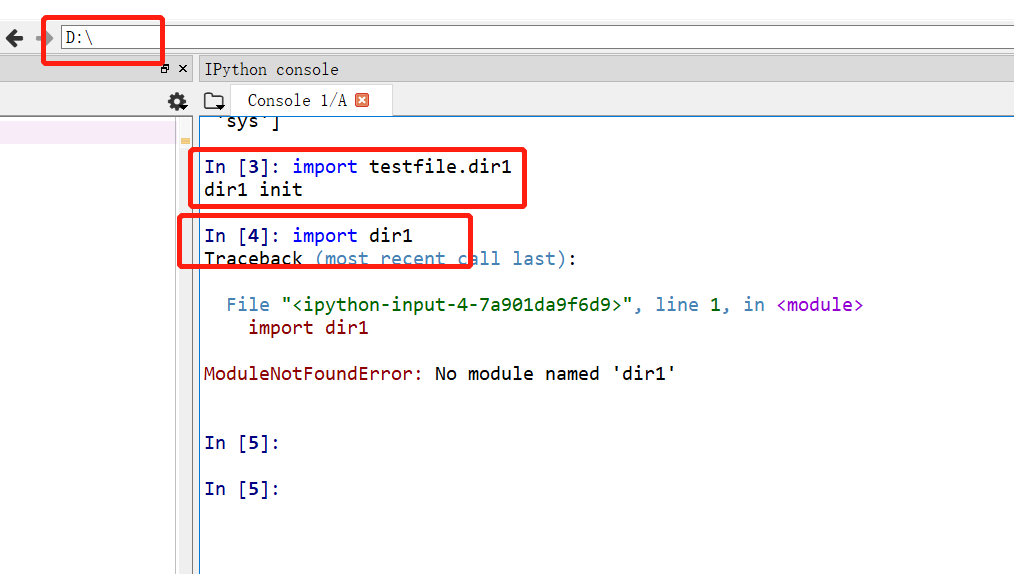
2)sys.path中目录的子目录,注意必须是子目录,不能是孙目录,图2运行时工作目录为c盘,由于testfile为program目录的子目录(program目录在sys.path的列表上),所以也可以直接import

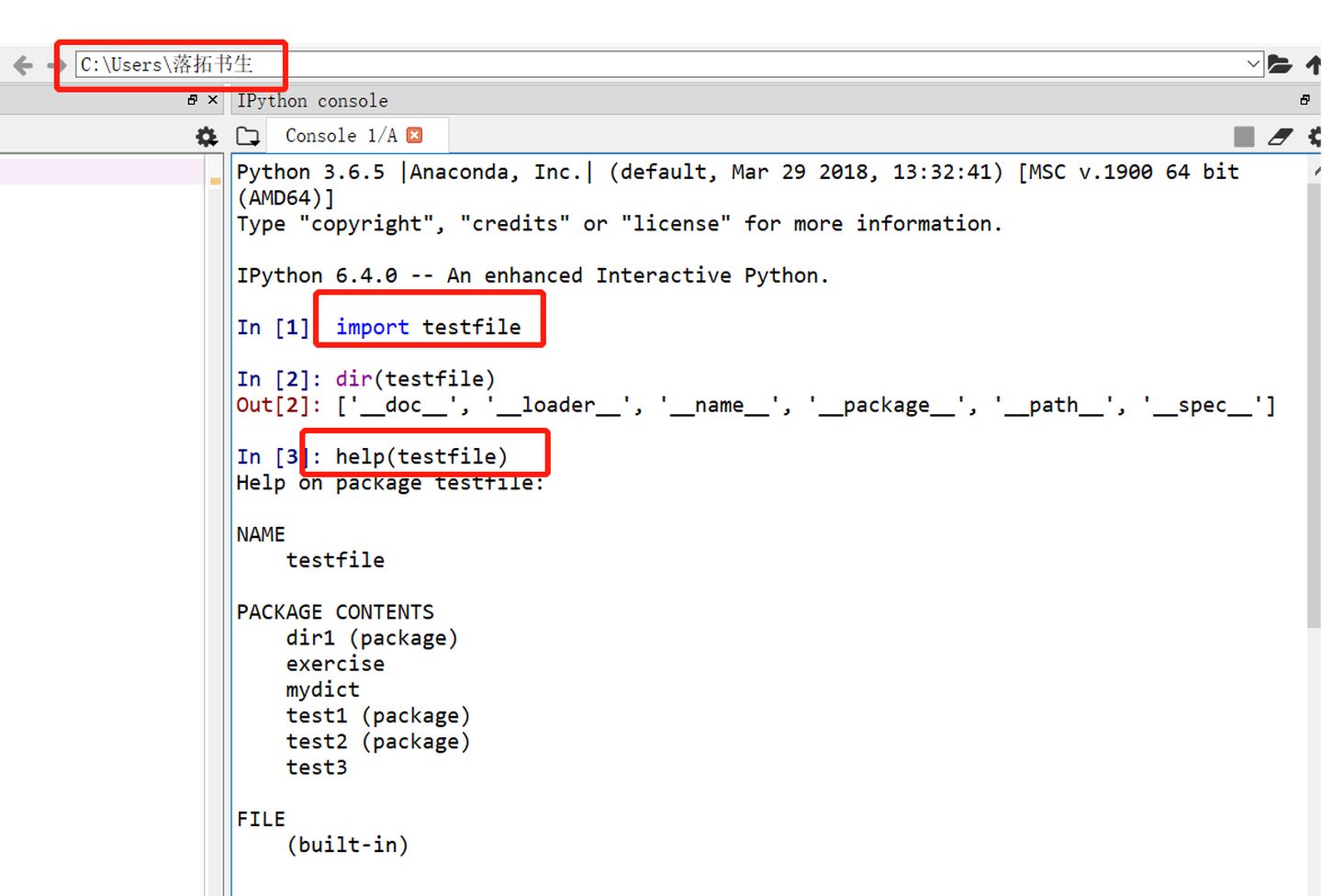
>>模块重载:reload(A)只能重载A模块,如果A模块中import B C,reload(A)并不能重载B和C模块。如果需要重载所有模块,需要编写特定方法,如下图:

>>组合

















 436
436











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









