






 本文详细介绍如何使用Python的Pandas库高效筛选Excel表格中的数据,通过实例演示了18岁以上男性参加三次会议的筛选过程,包括数据读取、条件设置及结果计算。适合数据处理初学者理解Pandas在数据筛选中的应用。
本文详细介绍如何使用Python的Pandas库高效筛选Excel表格中的数据,通过实例演示了18岁以上男性参加三次会议的筛选过程,包括数据读取、条件设置及结果计算。适合数据处理初学者理解Pandas在数据筛选中的应用。
Pyhton 批量筛选Excel的方法——Pandas的使用
摘要
在进行数据处理时,经常需要筛选出满足条件的数据,本文给出一种使用Python筛选Excel表格中数据的简单方法。
说明
对一张表几个字段的筛选无法体现Python处理数据的能力,本文所举案例只为示范说明。
1、初始化数据(可跳过)
假设有这样一个表,统计单位与会人员的信息,1表示到会,0表示缺席,session-1表示第一次会议,session-2表示第二次会议,以此类推。首先生成一个这样的数据表,在此基础上进行筛选:
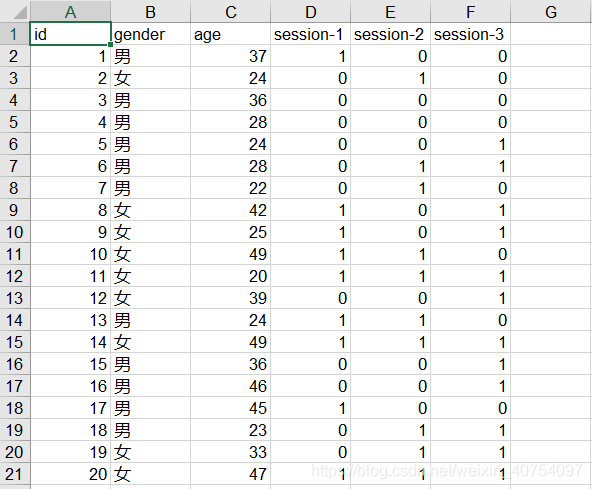
生成数据所用的代码,供参考:
def init_data():
# 创建Excel文件、工作表
file = xlwt.Workbook(encoding='utf-8')
table = file.add_sheet('Sheet1')
# 设计字段名
row = ['id', 'gender', 'age', 'session-1', 'session-2', 'session-3']
gender = ['男','女']
# 写入字段
for j in range(6):
table.write(0, j, row[j])
# 写入具体数据
for i in range(1,21):
# 写入编号
table.write(i, 0, i)
# 写入性别
table.write(i, 1, gender[random.randint(0,1)])
# 写入年龄
table.write(i, 2, random.randint(18, 50))
# 写入是否到会
table.write(i, 3, random.randint(0, 1))
table.write(i, 4, random.randint(0, 1))
table.write(i, 5, random.randint(0, 1))
# 保存文件
file.save('data.xls')
2、根据条件筛选数据
假设条件为:18岁以上的男性分别参加这3次会议的数据。
具体方法为:
(1)先用pandas读取Excel的办法将数据读入,记为data,同时使用DataFrame函数使之在Python中也呈现为一个二维数组表,记为df;
(2)使用类似于语句 df[df['字段名1'] == 条件1]这样的语句进行筛选,同时进行一些简单计算。先上代码:
def select_data(path):
# 使用pandas读取文件
data = pd.read_excel(path)
# 将数据存成规范的二维数组表
df = pd.DataFrame(data)
# 取出第一行的字段名
first_row = df[0:0]
# 根据自己的需要进行筛选
for row in first_row:
if row.startswith('session'):
# 设置筛选条件
df1 = df[(df[row] == 1) & (df['gender'] == '男') & (df['age'] < 45)]
# 打印出筛选后的表
print(df1)
# 进行一些简单计算:例如到会人员的平均年龄
print(sum(df1['age'])/len(df1[row]))
运算结果:

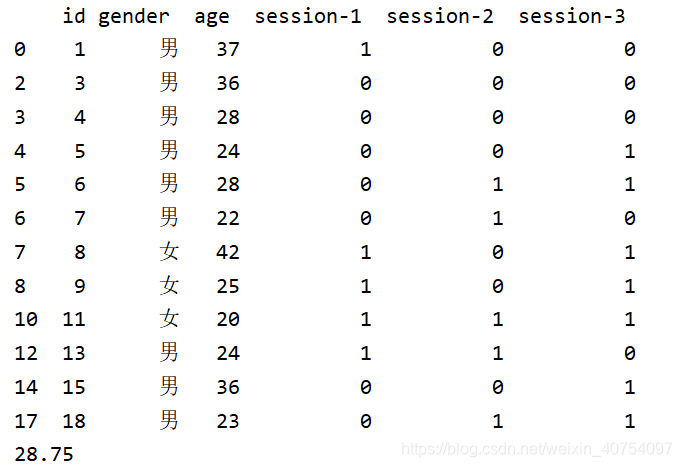
(3)补充说明:
① if 判断可以没有,我这里是为了一次性筛出3次会议的数据;
② 条件可以是单条件,多条件与或非的组合,例如条件改为:到会或是男性的45以下人员,条件语句写为:
((df[row] == 1) | (df['gender'] == '男')) & (df['age'] < 45)
相应的部分运算结果,以session-1为例:
以下是头文件和main函数的调用,代码组合后可以运行测试:
import random
import xlwt
import pandas as pd
if __name__ == '__main__':
# init_data() # 运行一次生成文件后注释
select_data('data.xls')
以上就是Python + Pandas筛选Excel数据的一个简单案例,实际上也可以筛选CSV数据,读入时使用pd.read_csv()函数,关键在于筛选条件的书写,对于二维数组表的理解。

















 2652
2652

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









