







正态分布,也以高斯分布而被人熟知。换句话说,正态分布也称为高斯分布。我们都清楚正态分布是用于处理连续型数据的好工具,尤其是当我们的研究对象符合正态分布时。
对于一维正态分布这个名字我其实比较不认可。在英文中,它叫“Univariate normal distribution”,直译过来就是单变量正态分布。中文的这个名字其实与原义是有点偏差的。(很来外来的知识,被中国所谓的专家起了一个高大尚的名字后,使中国人觉得其高深莫测,难以消化,其实背后是很简单的东西。真的是自己人难倒了自己人。)
一个正态分布可以由两个参数定义出来,一个是平均值(mean),用μ表示,它控制了正态分布的中心位置(正态分布中,平均值、中位数、众数都是相等),另一个是标准差(standard deviation),用σ表示,标准差是衡量数据如何分布的度量,它越小,说明数据是紧紧围绕平均值分布的,形状看起来就是又窄又高,它越大,说明数据离平均值比较远,形状看起来就是又宽又矮,所以说它控制了分布的形状。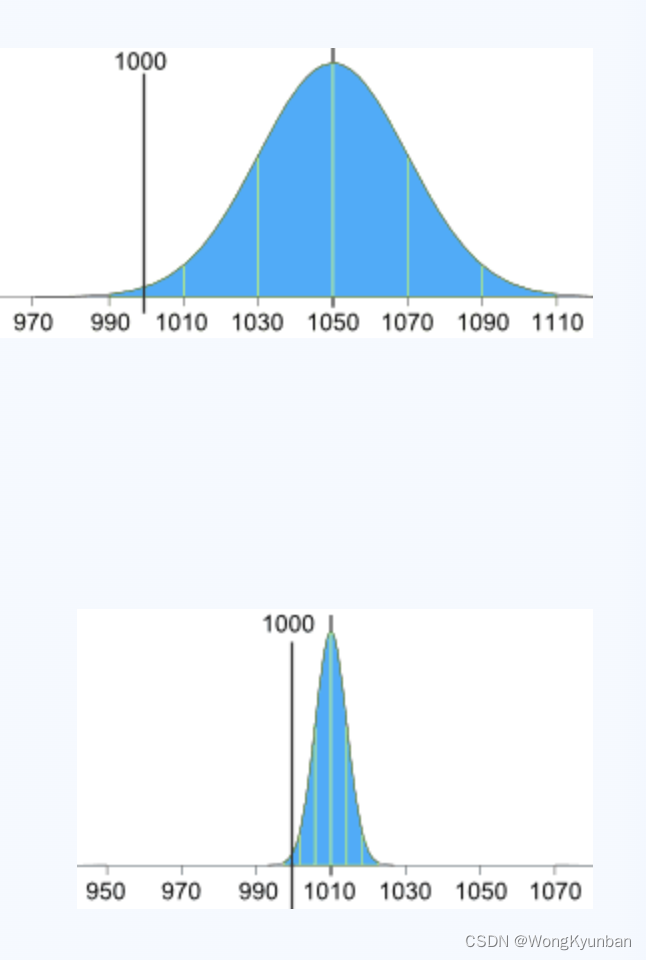
标准差的平方就是方差(variance),用σ2 表示。那么正态分布就可以表示为N(μ,σ2)
在概率中,我们都知道计算连续型数据的概率不能用离散数据相似的方法来计算,理由就是离散数据的都有确定的值,这些值都是能够提前知道的,而连续型数据则只能知道其在某个数据区间,并提前不能知道确切的值,它可以是这个区间里的任意值。那么正态分布就是要解决这个问题的。首先要确定正态分布,这个由前面提供到两个参数μ,σ来确定,然后使用下面的概率密度函数来计算某个值的概率:
P ( x ∣ μ , σ 2 ) = 1 2 π σ 2 exp ( − ( x − μ ) 2 2 σ 2 ) P(x∣μ,σ^2)= \frac1{\sqrt{2πσ^2}}\exp(-\frac{(x-μ)^2}{2σ^2}) P(x∣μ,<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









