Scrapy框架(一)
框架简介
Scrapy是纯Python开发的一个高效,结构化的网页抓取框架;
Scrapy是用纯Python实现一个为了爬取网站数据、提取结构性数据而编写的应用框架,用途非常广泛。多用于抓取大量静态页面。
框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便。
Scrapy 使用了 Twisted['twɪstɪd] (其主要对手是Tornado)异步网络框架来处理网络通讯,可以加快我们的下载速度,不用自己去实现异步框架,并且包含了各种中间件接口,可以灵活的完成各种需求。
模块安装
scrapy支持Python2.7和python3.4以上版本。
python包可以用全局安装(也称为系统范围),也可以安装咋用户空间中。不建议安装在系统范围。相反,建议在"虚拟环境"(virtualenv)中安装scrapy。Virtualenv允许不与已安装的Python系统包冲突,并且仍然通常使用pip安装。
Ubuntu 14.04或以上 安装
scrapy目前正在使用最新版的lxml,twisted和pyOpenSSL进行测试,并且与最近的Ubuntu发行版兼容。但它也支持旧版本的Ubuntu,比如Ubuntu14.04,尽管可能存在TLS连接问题。
Ubuntu安装注意事项
不要使用 python-scrapyUbuntu提供的软件包,它们通常太旧而且速度慢,无法赶上最新的Scrapy。
要在Ubuntu(或基于Ubuntu)系统上安装scrapy,您需要安装这些依赖项:
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
如果你想在python3上安装scrapy,你还需要Python3的开发头文件:
sudo apt-get install python3-dev
在virtualenv中,你可以使用pip安装Scrapy:
pip install scrapy
简单使用
第零步:分析网站
首先得想
1. 你的目标是什么?2. 你的目标是动态数据or静态数据?3. 怎么获取第一批数据?
4. 怎么获取多批数据?
5. 怎么做持久化?
第一步: 新建项目
创建项目: scrapy startproject project_name
进入项目目录后创建爬虫:
scrapy genspider spider_name website_domain
执行爬虫:
scrapy crawl spider_name 或者 scrapy runspider spider_file
--------------------------------------------------------------------
scrapy.cfg: 项目部署的配置文件
tz_spider: 项目目录, 包含了项目运行相关的文件
itsms.py: 项目的目标文件
middlewares.py: 项目的中间件文件
pipelines.py: 项目的管道文件
settings.py: 项目的设置文件
spiders: 项目的爬虫目录
第二步: 设置项目目标
进入items.py文件中设置爬取的目标
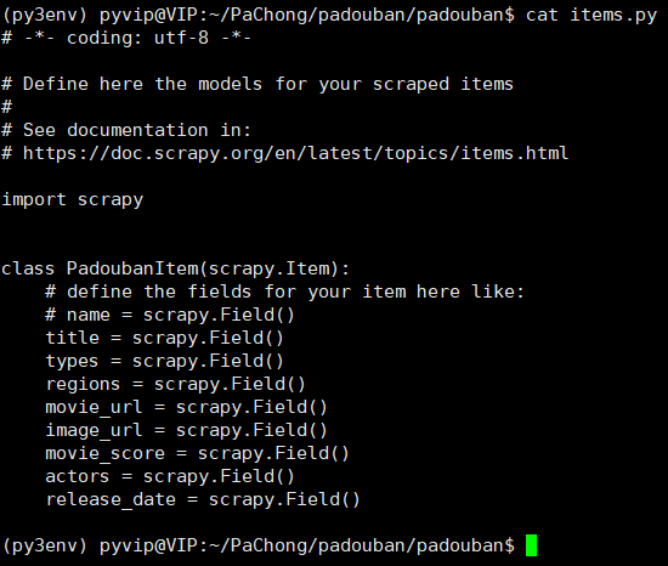
第三步: 设置管道文件
编辑pipelines.py文件, 让目标数据流向到指定点. 如: 数据保存到文件中
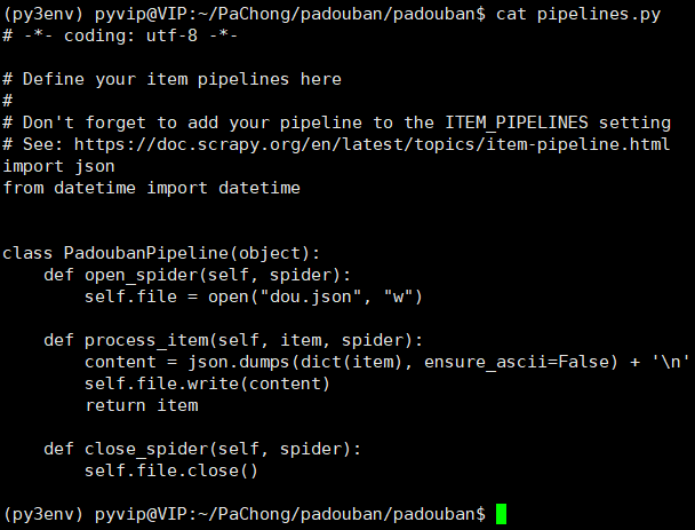
注意: 管道文件设置好后, 需要在settings.py文件注册记得注册
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'papaixin.pipelines.PapaixinPipeline': 300,
}
第四步: 修改设置文件
设置UA信息
# User_Agent信息设置
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/75.0.3770.80 Safari/537.36'
设置不遵循robots检测
# Obey robots.txt rules
# ROBOTSTXT_OBEY = True
设置爬取时间间隔
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 0.5
设置管道文件注册
# Configure item pipelines
# See https://doc.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'papaixin.pipelines.PapaixinPipeline': 300,
}
第五步: 编写spider
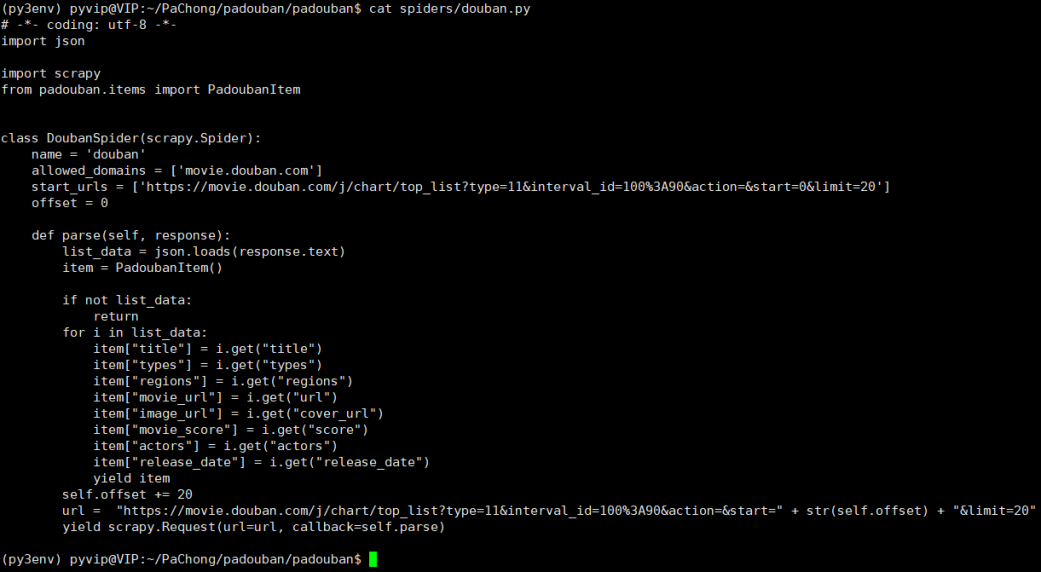
第六步: 报错了怎么办
先排语法错误
再排拼写错误
继排逻辑错误
后排数据错误
运行流程
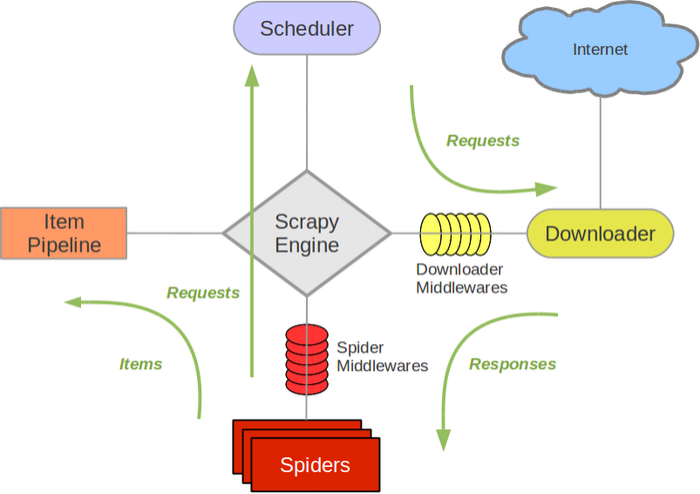
Scrapy构架解析:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
Downloader Middlewares:(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
作业
1.实践豆瓣电影案例, 保存数据到json文件中.

























 3626
3626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









