






大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024我们一起变强。
2024年3月26日,吴恩达教授在红杉资本(Sequoia Capital)的人工智能峰会(AI Ascent)上发表了一次主题为《Agentic Reasoning》的演讲。虽然演讲时长仅有13分钟,但包含的内容相当丰富,吴恩达教授表达了自己对AI Agent未来发展的观点、思考和展望,并分享了当下AI Agent主流的4种设计模式,包括反思、工具调用、规划和多智能体协作。

本文将以吴恩达教授的这次演讲为引,对演讲中提到的观点和设计模式进行学习和讨论。文末附这次演讲的原始视频(已添加中文字幕,视频仅做学习交流使用)。

关于吴恩达教授
吴恩达教授,全名Andrew Ng,是全球知名的人工智能和机器学习领域的专家和领军人物。Andrew是DeepLearning.AI的创始人兼CEO,Landing AI的创始人兼CEO,AI Fund的总合伙人,以及在线学习平台Coursera的联合主席和联合创始人。此外,他还担任斯坦福大学计算机科学系的兼职教授。

在学术界,吴恩达教授以其在机器学习和在线教育方面的开创性工作而闻名。他曾在斯坦福大学领导开发了主要的MOOC(大规模开放在线课程)平台,并教授了超过10万名学生的在线机器学习课程,这一课程后来成为了Coursera平台上的标志性课程。他的研究主要集中在机器学习、深度学习、计算机视觉和自然语言处理等领域,并发表了超过200篇学术论文。
在工业界,吴恩达教授曾担任百度的首席科学家,领导了该公司1300人的AI团队,推动了公司的全球AI战略和基础设施建设。他还在Google创立并领导了Google Brain项目,被誉为“谷歌大脑之父”,这一项目是深度学习领域的重要里程碑。2024年4月,吴恩达被任命为亚马逊公司董事会成员,显示了他在科技界的重要地位和影响力。
除了在学术和工业界的卓越贡献,吴恩达教授还致力于普及AI知识,提高公众对这一前沿技术的认知和理解。他创办的AI Fund、DeepLearning.AI和Landing AI公司,旨在帮助各行各业应用人工智能技术,解决实际问题。
我们为什么需要AI Agent/Agentic Workflow?
Zero-shot Prompting VS Agentic Workflow
在当下,不论是国外的AI工具如ChatGPT、Claude、谷歌的Gemini,还是国内的Kimi、通义千问和文心一言,我们大多数人的使用方式还是以“zero-shot prompt”直接对话的形式,也就是我们直接抛给ChatGPT一个问题,比如“写一篇关于xx主题的论文”,让它一次性给出回复。在这个过程中,LLM模型只会执行“生成”这一个动作。
然而,这与我们在真实世界中完成工作任务的流程是截然不同的。还是以写论文为例,一般我们会起草一个初稿,然后评估、分析、修订,迭代出第二、第三个版本,直到我们满意为止。其他工作和学习任务也是如此,我们通常会将其分解为一个一个的流程,然后按照流程来操作,以保证结果的质量。LLM模型也理应如此为我们服务。
-
直接对话执行“生成”任务:

-
添加了Agentic Workflow的迭代流:

这里需要对零样本提示(Zero-shot prompting)多说两句。零样本提示是指LLM模型在没有针对具体任务进行专门训练的情况下,仅依赖于提示词(prompt)和预训练中获得的广泛语言知识来执行任务的能力。例如,给出“将以下句子翻译成法语:‘你好,你好吗?’”的提示,模型可以直接生成“Bonjour, comment ça va?”的翻译。这种方法的优势在于灵活性高、适用范围广,无需为每个特定任务准备专门的训练数据。然而,由于缺乏特定任务的训练,其生成质量是无法保证的。
Agentic Workflow赋能LLM模型
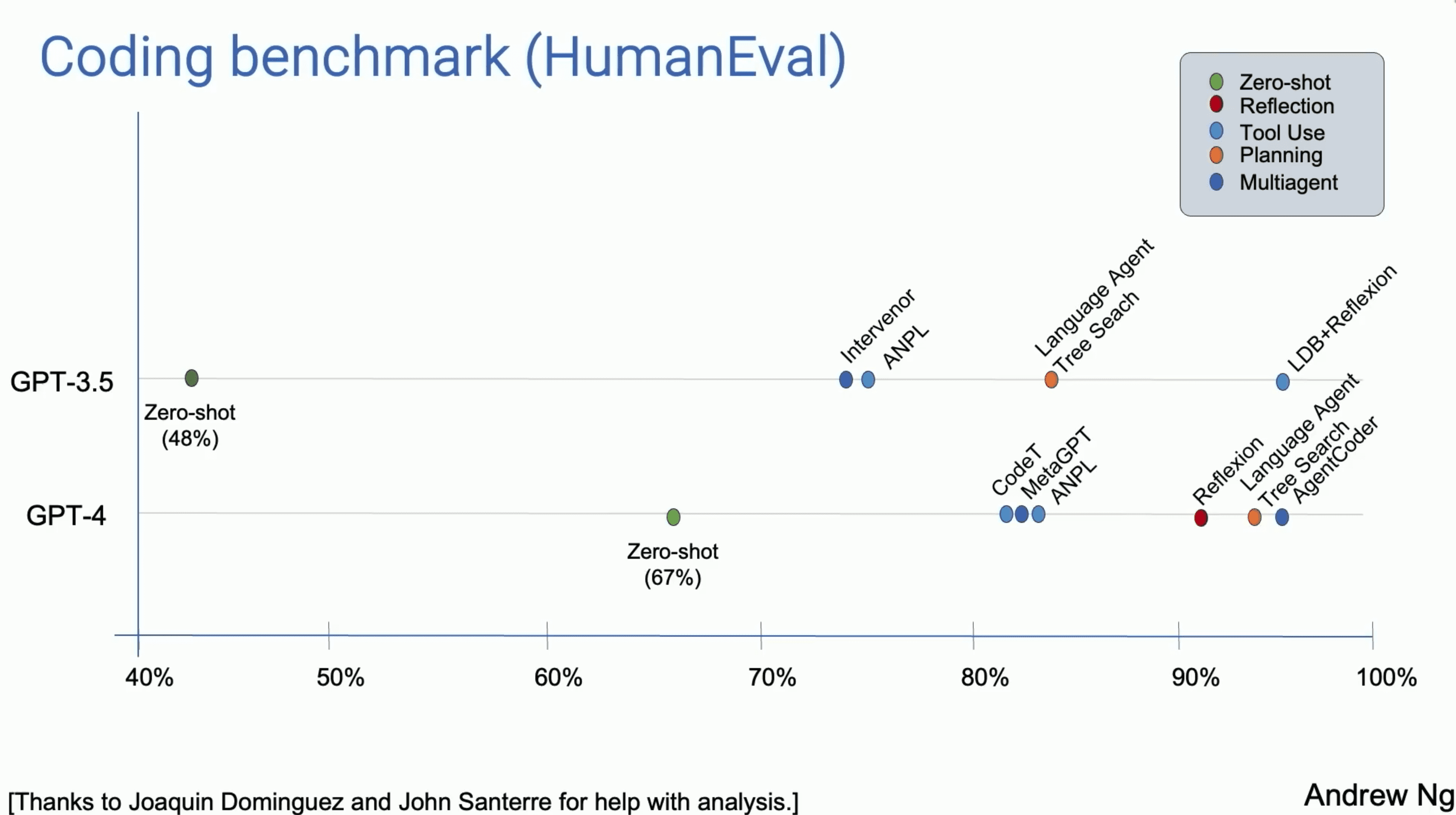
吴恩达教授的团队对“Zero-shot prompting”以及添加了不同设计模式的AI Agent的表现做了数据分析和对比,详情如下图。图中的纵坐标分别表示基座模型是GPT-3.5和GPT-4,横坐标表示在“Coding benchmark”下各模型/Agent的正确率(表现),百分比越高表现越好。
-
Zero-shot模式:
-
GPT-3.5的Zero-shot性能为48%。
-
GPT-4的Zero-shot性能显著提升,为67%。
-
结论:Zero-shot模式下,模型在没有具体任务示例的情况下,仅依赖于其预训练的知识来执行任务。这种情况下比拼的是模型的通用基础能力,可以理解为模型的“智商”,GPT-4表现好是意料之中的。
-
-
AI Agent(智能体)模式:
-
Reflection反馈模式通过模型自身的反思与调整来改进任务执行。
-
Tool Use工具调用模式涉及模型调用外部工具或库来帮助解决任务。
-
Planning规划模式通过提前计划和组织任务步骤来提高效率和准确性。
-
Multiagent多智能体协作模式涉及多个智能体的协同工作,以提高整体任务执行能力。
-
结论1:添加了Agentic Workflow的AI Agent在任务执行中的表现显著提升,不论基座模型是GPT-3.5还是GPT-4。
-
结论2:即使基座模型是GPT-3.5,通过添加Agentic Workflow将其设计为AI Agent后,性能表现也超过了Zero-shot模式下的GPT-4!
-
其实这种结论也很好理解,对于一项工作或学习任务来说,光有“智商”是不足以保证任务完成质量的,更重要的,与如何完成这项任务的方式方法有关系。“智商”(即大脑,LLM模型)可能起到一定作用,但合理的规划,完善的流程设计在后期任务执行过程中也起到关键的作用,虽然这常常被我们忽略。
AI Agent 4种主流的设计模式
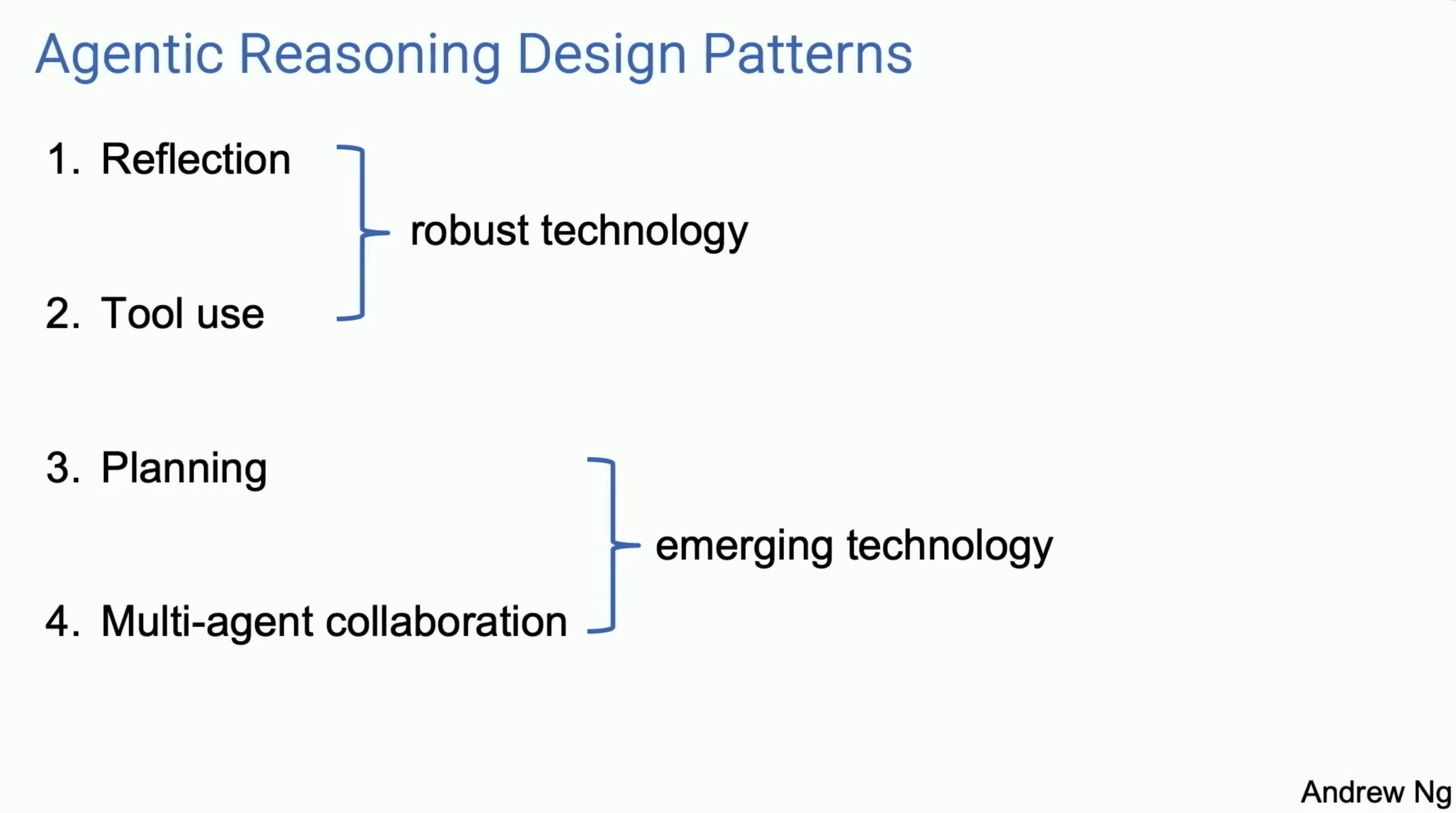
关于AI Agent的研究和相关论文非常多,吴恩达教授总结和介绍了四种较为常见的设计模式,分别是反馈(Reflection)、工具调用(Tool Use)、规划(Planning)和多智能体协作(Multi-agent Collaboration)。反馈和工具调用是比较成熟的技术,通过反馈机制自我调整和调用外部工具来提高任务执行能力。规划和多智能体协作则是是更为新兴的技术,前者通过系统化任务步骤来提升效率,后者通过多个智能体的协作来增强整体任务处理能力。
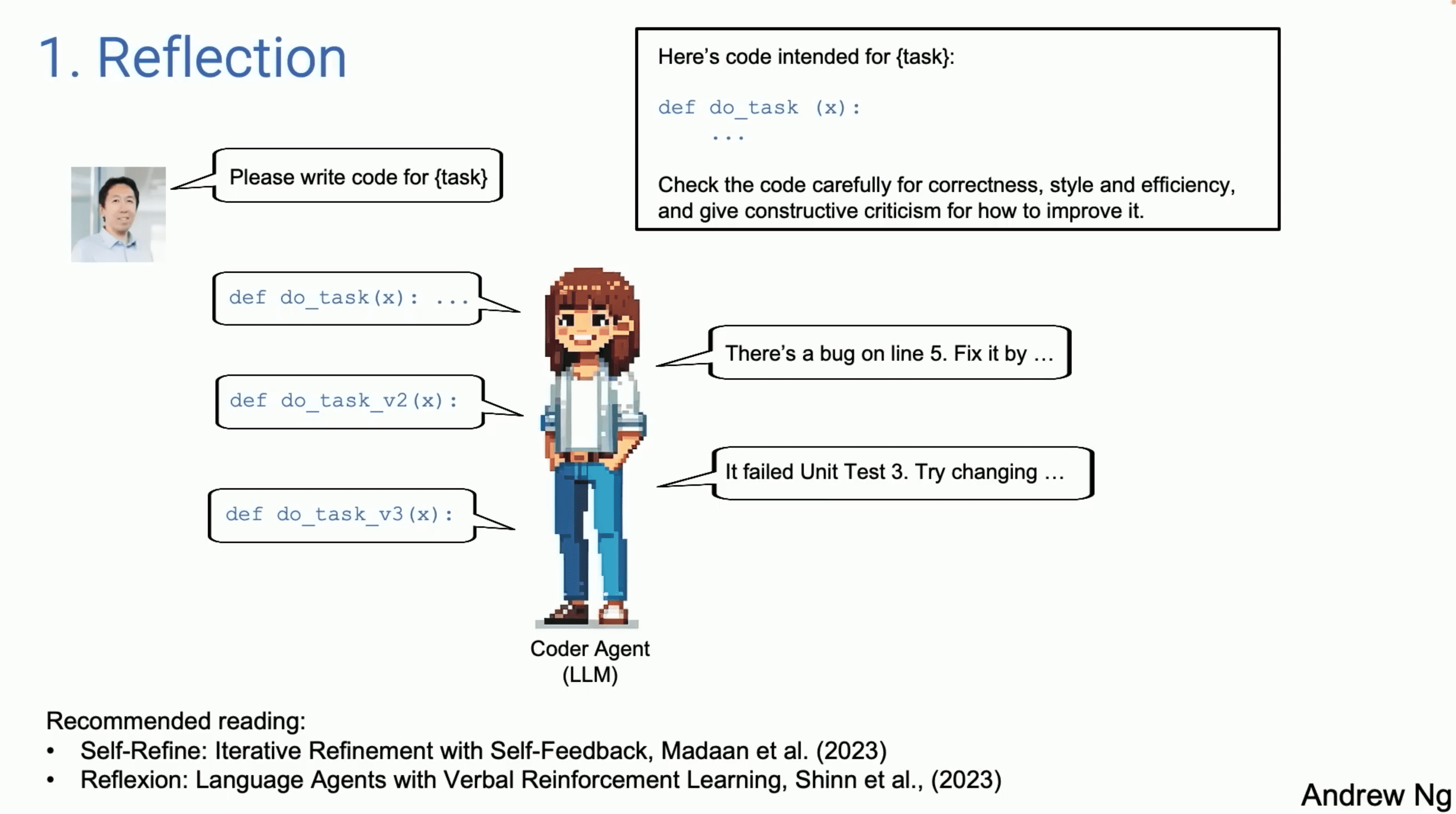
1. 反馈(Reflection)
反馈(Reflection)设计模式是一种让AI模型通过自我反思和迭代改进来提高任务执行能力的方法。在这种模式中,模型不仅生成初始解决方案,还会通过多次反馈和修改,不断优化其输出。
描述
-
任务定义:
-
初始任务由用户提供,例如编写特定功能的代码。
-
-
初始生成:
-
模型根据任务要求生成初始解决方案(例如,生成第一版代码)。
-
-
自我反馈:
-
模型对生成的初始解决方案进行自我检查和评估,包括检查代码的正确性、风格和效率。
-
模型会标识出可能存在的问题(例如,第5行有错误,需要修复)。
-
-
迭代改进:
-
模型根据自我反馈进行修改,生成改进版的解决方案。
-
这一过程会进行多次,直到模型生成一个满意的最终解决方案(例如,经过多次迭代后生成版本v2和v3)。
-
解释
-
自我反思:模型在生成初始输出后,对自身的输出进行反思和评估,找出其中的不足。这类似于人类在完成一项任务后,回顾自己的工作并找出改进之处的过程。
-
迭代改进:基于反馈进行的反复改进,使得每一次生成的结果都比上一次更好。这个过程增强了模型的学习和自我调整能力。
分析
-
优点:
-
提高准确性:通过反复的自我检查和修改,模型能够显著提高输出的准确性和质量。
-
适应性强:模型能够根据任务的具体要求进行调整,表现出更高的灵活性和适应性。
-
减少错误:通过多次迭代,模型可以发现并修正初始生成中可能存在的错误,从而减少最终输出中的错误率。
-
-
缺点:
-
计算资源消耗:多次迭代和反馈过程需要更多的计算资源和时间。
-
复杂度增加:反馈和迭代过程的实现相对复杂,需要设计有效的反馈机制和改进策略。
-
实例
在吴恩达教授提到的例子中,任务是编写代码,模型首先生成初始版本,然后通过多次反馈和修改生成更优化的版本。例如,初始代码版本存在错误,模型通过反馈指出错误并进行修正,最终生成一个通过所有测试的版本。
推荐阅读
-
Self-Refine: Iterative Refinement with Self-Feedback, Madaan et al. (2023)
-
Reflexion: Language Agents with Verbal Reinforcement Learning, Shinn et al. (2023)
2. 工具调用(Tool Use)
工具调用(Tool Use)设计模式是一种让AI模型通过调用外部工具或库来增强任务执行能力的方法。在这种模式中,模型并不仅仅依赖于自身的知识和能力,而是利用各种外部资源来完成任务,从而提高效率和准确性。
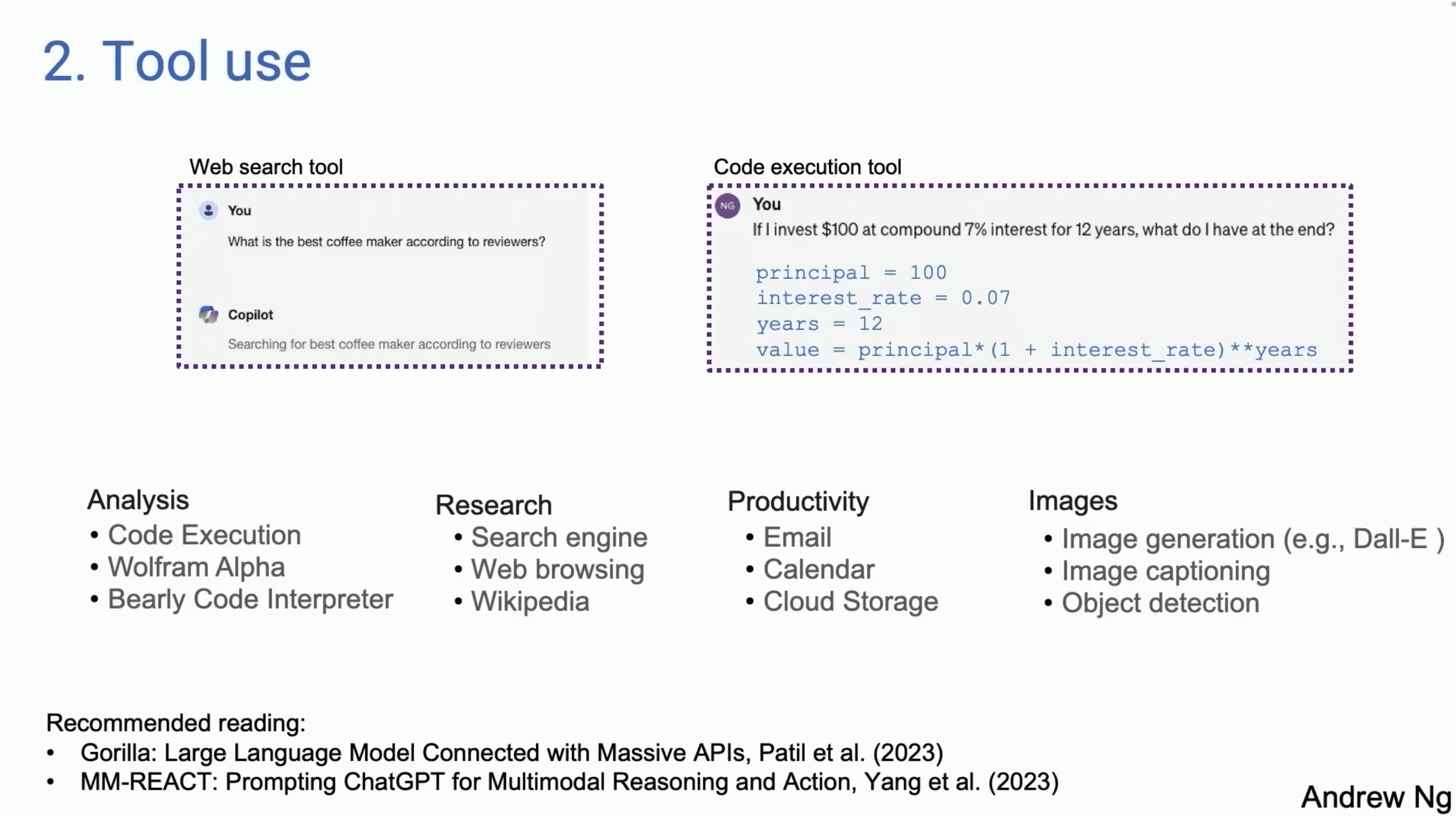
描述
-
任务定义:
-
用户提出问题或任务,例如查找最佳咖啡机的评论或计算复利。
-
-
调用工具:
-
模型识别需要完成的任务并选择合适的外部工具来解决问题。
-
例如,对于查找评论,模型可以调用Web搜索工具;对于计算复利,模型可以调用代码执行工具。
-
-
执行任务:
-
模型通过调用工具执行具体操作,例如进行网页搜索或运行代码。
-
生成的结果会返回给用户,回答问题或解决任务。
-
解释
-
工具集成:模型可以集成多个外部工具,如Web搜索引擎、代码执行平台、图像生成和识别工具等,以扩展其功能。
-
任务多样性:工具使用模式使得模型能够处理多种任务,从信息检索到数据分析,从生产力工具使用到图像处理。
分析
-
优点:
-
增强能力:通过调用外部工具,模型能够处理其自身能力范围之外的任务,显著扩展了其应用范围。
-
提高效率:工具使用模式可以加快任务处理速度,提高解决问题的效率。例如,调用计算工具可以快速完成复杂计算。
-
准确性提升:利用专门的工具可以提高任务执行的准确性和可靠性,例如使用代码解释器进行准确的代码执行。
-
-
缺点:
-
依赖性:模型对外部工具的依赖增加,如果工具不可用或出现故障,可能会影响任务执行。
-
复杂性:集成和调用多种工具增加了系统的复杂性,需要有效的管理和协调。
-
实例
吴恩达教授展示了两个示例:
-
Web搜索工具:用户询问最佳咖啡机的评论,模型调用Web搜索工具进行搜索并返回结果。
-
代码执行工具:用户询问复利计算,模型调用代码执行工具计算并返回最终结果。
推荐阅读
-
Gorilla: Large Language Model Connected with Massive APIs, Patil et al. (2023)
-
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action, Yang et al. (2023)
3. 规划(Planning)
规划(Planning)设计模式是一种通过提前计划和组织任务步骤来提高效率和准确性的方法。在这种模式中,模型将复杂任务分解为多个步骤,并依次执行每个步骤,以达到预期的目标。
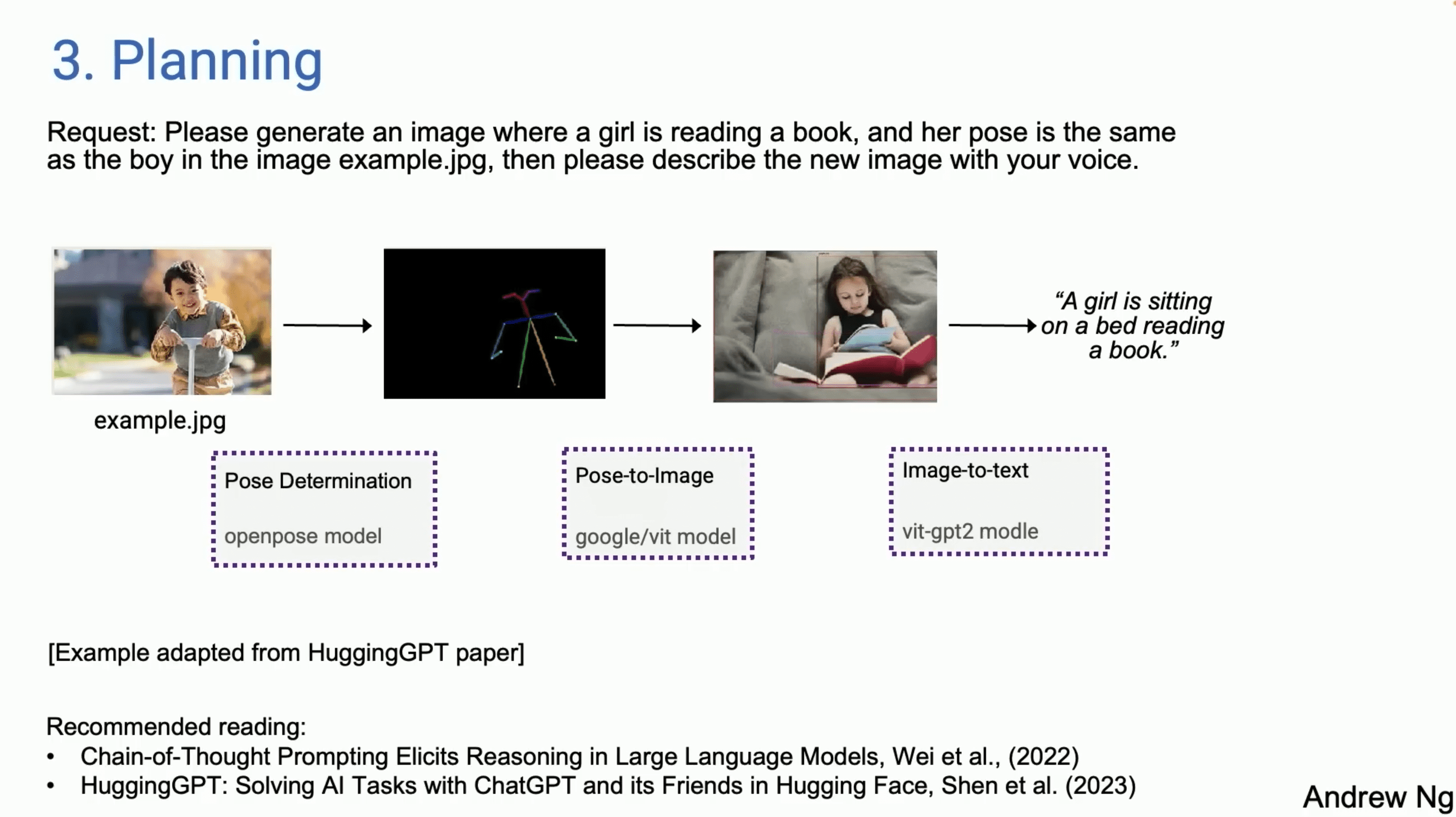
描述
-
任务定义:
-
用户提出一个复杂的任务请求,例如生成一个特定姿势的图片并进行描述。
-
-
步骤分解:
-
模型将任务分解为多个步骤,例如确定姿势、生成图像和生成描述文本。
-
-
依次执行:
-
模型依次执行每个步骤,确保每一步都得到正确的结果。例如,使用OpenPose模型确定姿势,使用Google/VIT模型生成图像,使用VIT-GPT2模型生成描述文本。
-
-
结果整合:
-
将每个步骤的结果整合在一起,完成整个任务。例如,最终生成的结果是包含特定姿势的图像和相应的文本描述。
-
解释
-
步骤分解与执行:规划模式通过将复杂任务分解为更小、更可控的步骤,使得每个步骤都能够更加准确和高效地执行。这类似于人类在处理复杂任务时所采用的分步计划和执行方法。
-
模块化处理:每个步骤可以由不同的模型或工具来完成,增强了整体任务处理的灵活性和扩展性。
分析
-
优点:
-
提高准确性:通过逐步执行任务,每个步骤都可以进行独立验证和优化,提高了整体任务的准确性。
-
增强灵活性:任务的每个步骤都可以根据需要调整或替换,增加了处理复杂任务的灵活性。
-
简化复杂任务:通过任务分解,复杂任务变得更加可管理和易于执行。
-
-
缺点:
-
依赖性强:每个步骤的成功执行依赖于前一步的正确性,如果某一步出错,可能会影响整个任务的结果。
-
计算资源需求高:分步执行和结果整合需要更多的计算资源和时间。
-
实例
吴恩达教授在演讲中展示了一个示例:用户请求生成一个阅读书本的女孩图片,并且姿势与示例图片中的男孩相同,然后生成描述文本。
-
步骤1:使用OpenPose模型确定示例图片中的姿势。
-
步骤2:使用Google/VIT模型根据确定的姿势生成新图片。
-
步骤3:使用VIT-GPT2模型生成图片的描述文本。
推荐阅读
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, Wei et al. (2022)
-
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face, Shen et al. (2023)
4. 多智能体协作(Multi-agent Collaboration)
多智能体协作(Multiagent Collaboration)设计模式是一种通过多个智能体之间的合作来提高任务执行效率和准确性的方法。在这种模式中,多个智能体分担任务,并通过相互交流和协作,共同完成复杂任务。

描述
-
任务定义:
-
用户提出一个需要多智能体合作完成的复杂任务,例如开发一个五子棋游戏。
-
-
智能体分工:
-
不同的智能体负责任务的不同部分,例如设计、编码、测试和文档编写等。
-
-
协作执行:
-
各个智能体通过交流和协作,共同完成任务。每个智能体在完成自己部分任务的同时,会与其他智能体交换信息和反馈。
-
-
结果整合:
-
将各个智能体完成的部分任务结果整合在一起,完成整个任务。例如,最终开发出一个功能完善的五子棋游戏。
-
解释
-
分工合作:多智能体协作模式通过将任务分解并分配给不同的智能体,使得每个智能体可以专注于其擅长的部分,增强了任务处理的效率和准确性。
-
协同工作:智能体之间通过交流和反馈,共同优化和改进任务执行,确保每个部分都能顺利衔接,最终完成整体任务。
分析
-
优点:
-
提高效率:通过分工合作,多智能体协作模式能够显著提高任务处理的效率和速度。
-
增强准确性:不同智能体之间的交流和反馈可以发现和修正错误,提高任务执行的准确性。
-
灵活应对复杂任务:多智能体协作模式适用于处理复杂任务,能够通过智能体之间的合作应对各种挑战。
-
-
缺点:
-
协调复杂:多个智能体之间的协调和通信需要有效的管理,否则可能导致混乱或任务延误。
-
资源需求高:多智能体协作模式需要更多的计算资源和时间来管理和协调各个智能体。
-
实例
吴恩达教授的PPT中展示了一个多智能体协作的示例:开发一个五子棋游戏。
-
设计阶段:一个智能体负责游戏的设计,包括界面和规则。
-
编码阶段:另一个智能体负责游戏的编码,实现核心功能。
-
测试阶段:第三个智能体负责测试游戏,找出并修复错误。
-
文档编写阶段:第四个智能体负责编写游戏的使用文档和说明。
通过智能体之间的分工合作,最终成功开发出一个完整的五子棋游戏。
性能对比
表格显示了多智能体协作与单智能体在不同任务中的性能对比:
-
传记写作:多智能体的准确率为73.8%,显著高于单智能体的66.0%。
-
MMLU(多任务语言理解):多智能体的准确率为71.1%,高于单智能体的63.9%。
-
国际象棋:多智能体的准确率为45.2%,远高于单智能体的29.3%。
推荐阅读
-
Communicative Agents for Software Development, Qian et al., (2023)
-
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation, Wu et al., (2023)
4种设计模式的总结

结语
AI Agent/Agentic Workflow对AI应用的落地至关重要,因为它能够拓展AI的使用场景,并且有效地提高任务完成质量。

-
任务集拓展:
-
由于引入了Agentic Workflow,AI能够执行的任务种类将显著增加。这意味着AI不仅能处理更广泛的任务,还能更高效地完成复杂任务。
-
-
任务委派与耐心等待:
-
我们需要习惯将任务委派给AI智能体,并耐心等待其完成。随着AI智能体的能力提升,它们能在较长时间内完成更复杂的任务,这需要我们调整预期和工作方式。
-
-
快速Token生成的重要性:
-
生成速度对于AI的性能至关重要。即使是低质量的语言模型,通过生成更多的tokens,也能获得良好的结果。这表明生成速度和数量可以在一定程度上弥补模型质量的不足。
-
-
早期模型的Agentic Reasoning性能:
-
即使是早期版本的模型(如GPT-4),通过应用Agentic Reasoning方法,也能达到接近未来更先进模型(如GPT-5、Claude 4、Gemini 2.0)的性能。这意味着我们可以在现有技术基础上,通过优化工作流和方法,提升模型的实际应用效果。
-
完整版演讲视频(中文字幕)
由于平台限制,完整版视频请关注我的微信公众号观看。
精选推荐
实际上,大概两周前,我写过一篇万字长文,详细介绍了AI Agent架构的概况,里面提到了更广泛的一些设计模式,感兴趣的朋友可以看看。
关于目前最新最强大模型GPT-4o的详细介绍,可以看我下面这些文章。
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。

















 1424
1424

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









