






📢本周 AI 快讯 | 1 分钟速览🚀
1️⃣ 📝 Manus 全面开放注册 :无需邀请码即可注册,新用户免费获得 1000 积分,每日 300 积分免费任务。
2️⃣ 🔍 阿里 Qwen 推出「深入研究」 :QwenChat 免费开放深度研究助理,仅需数分钟完成复杂研究任务。
3️⃣ 🔧 阿里通义实验室开源 ZeroSearch :强化学习框架让大模型无需依赖真实搜索引擎,自主学习搜索与推理。
4️⃣ 📸 腾讯发布混元图像 2.0 :毫秒级实时生图,超写实画质,避免 AI 味,细节更丰富。
5️⃣ 🧑💻 OpenAI 发布 Codex 软件工程智能体 :支持自动化编程任务,覆盖代码编写、错误修复、测试运行等。
6️⃣ 💡 OpenAI 上线 GPT-4.1 模型 :编程专家版上线 ChatGPT,GPT-4.1 mini 替代 GPT-4o mini,所有用户可使用。
7️⃣ 🔗 OpenAI 测试 MCP 协议 :ChatGPT 即将支持 Model Context Protocol,可连接第三方服务。
8️⃣ 🎤 OpenAI 计划推出 ChatGPT Record 功能 :实现实时会议录音、转录和自动总结。
9️⃣ ⚡ Windsurf 发布 SWE-1 系列 :专为软件工程设计,SWE-1、SWE-1-lite、SWE-1-mini 全面上线。
🔟 🌐 Anthropic 即将发布 Claude Neptune :安全测试收官,挑战 OpenAI 和 谷歌 Gemini,预计 5 月底或 6 月初发布。
1️⃣1️⃣ 🚀 马斯克称 Grok 3.5 仍需打磨 :还有点太粗糙,预计还需一周推出。
1️⃣2️⃣ ⏳ Meta 推迟发布 Behemoth 模型 :因技术瓶颈,发布时间推至秋季,引发投资者担忧。
1. Manus 官宣全面开放注册
5 月 12 日,曾因邀请码炒至数万元而备受关注的 AI 智能体平台 Manus 宣布全面开放注册,所有用户无需邀请码即可免费体验。注册用户将一次性获得 1000 积分奖励,并可每日免费获得 300 积分,用于执行一项任务,积分当日有效,不可结转。
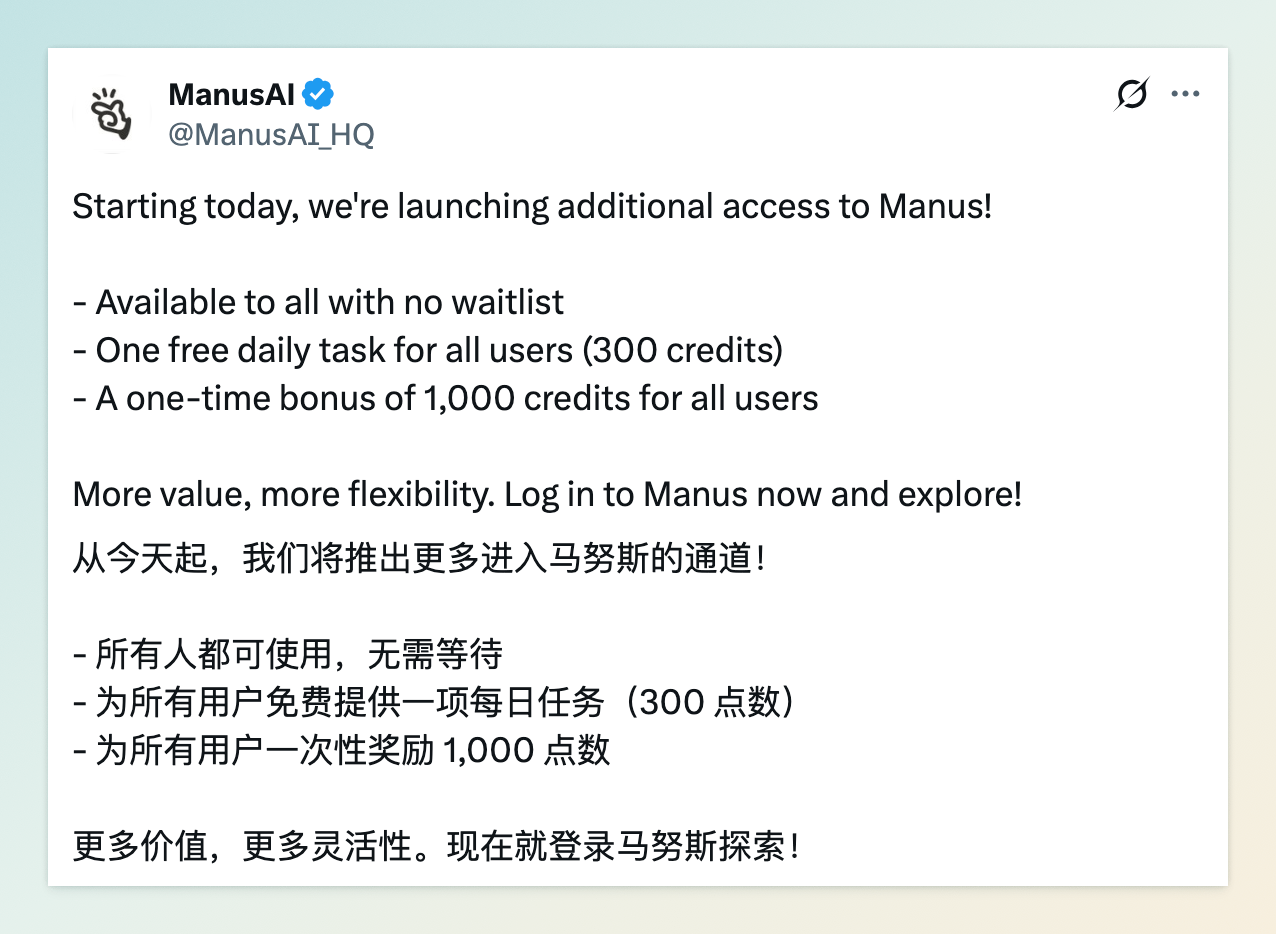
Manus 由中国初创团队 Monica 开发,定位为通用型 AI 智能体,能够自主完成复杂任务,如撰写报告、制作表格等。此前,Manus 采用邀请制,邀请码在二手平台一度被炒至近 10 万元人民币,引发广泛关注。
据报道,Manus 最近完成了由美国风险投资公司 Benchmark Capital 领投的 7500 万美元融资,估值达 5 亿美元。此次融资将用于加速产品开发和市场拓展,应对来自 OpenAI、Google 等科技巨头的竞争。
2. 阿里通义千问上线「深入研究」功能
5 月 13 日,阿里巴巴旗下的通义千问(Qwen)正式推出全新智能助理系统「深入研究」(Deep Research),并在 QwenChat 平台免费向所有用户开放体验。
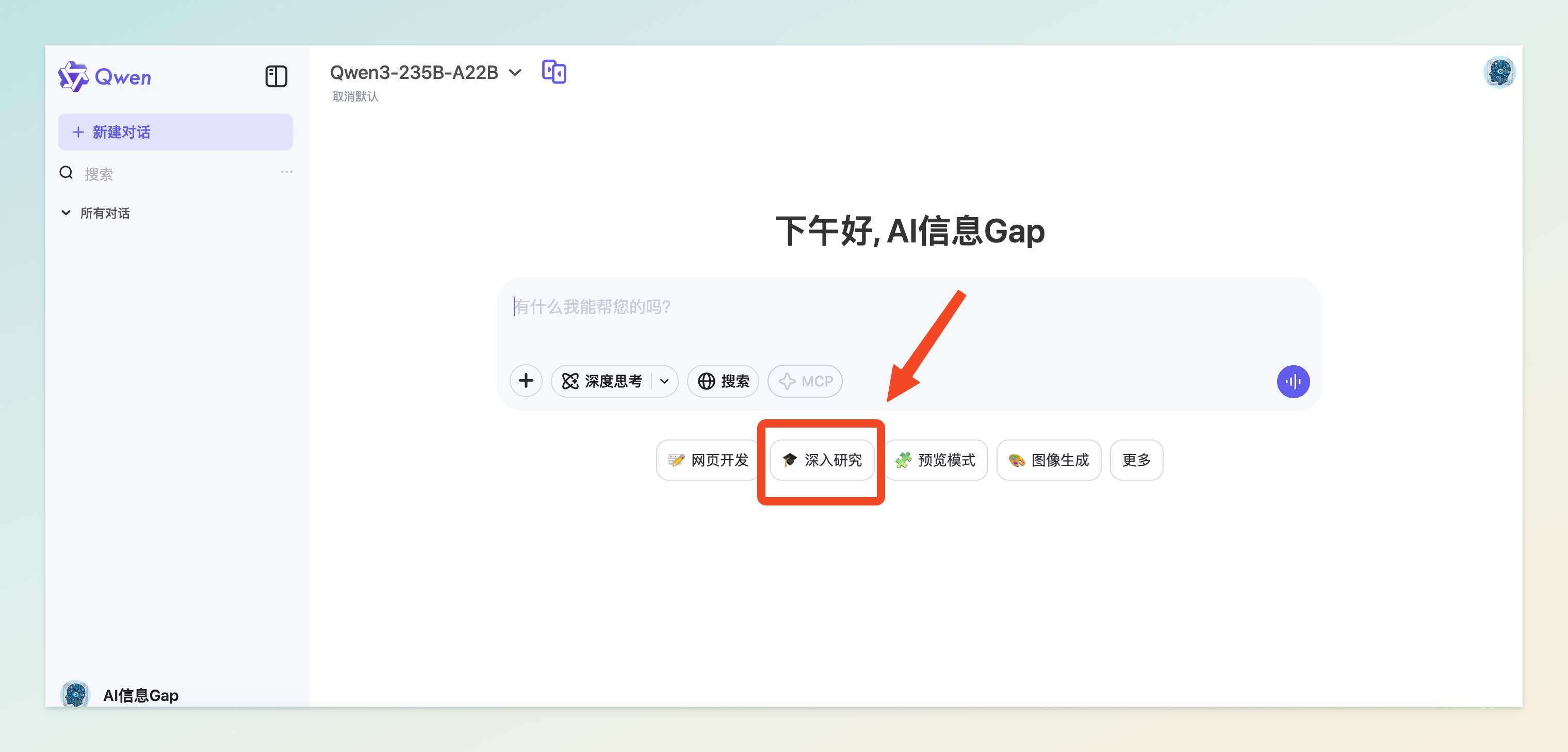
「深入研究」能够根据用户提供的提示词(prompt),自动规划多步骤的研究流程。系统首先分析用户需求,提出反问以确认任务细节,随后制定研究计划,自动查找、分析并整合来自网络的相关信息,最终生成结构清晰、数据可信的研究报告。这一过程大幅缩短了研究时间,原本需要数小时的任务现在仅需十几分钟即可完成。
该功能深度融合了 Qwen 的模型推理能力、Agent 能力及长上下文窗口技术,并通过强化学习优化性能,实现了从需求理解到成果交付的闭环。用户只需在 QwenChat 对话框中点击“深入研究”按钮,即可立即体验这一智能助理。
3. 阿里通义实验室开源搜索框架 ZeroSearch
阿里通义实验室近日正式开源了 ZeroSearch,这是一个创新性的强化学习框架,旨在让大型语言模型(LLM)在无需依赖真实搜索引擎的情况下,学习搜索与推理能力。该方法通过模拟搜索环境,显著降低了训练成本,同时在多个评测中展现出超越传统搜索引擎的性能。
ZeroSearch 的核心在于使用预训练的 LLM(如 Qwen2.5 系列)模拟搜索引擎的行为。实验结果显示,使用 3B 参数的模拟模型即可有效训练 LLM 的搜索能力;7B 模型的性能已与谷歌搜索相当;而 14B 模型则在多个基准测试中超越了谷歌搜索。
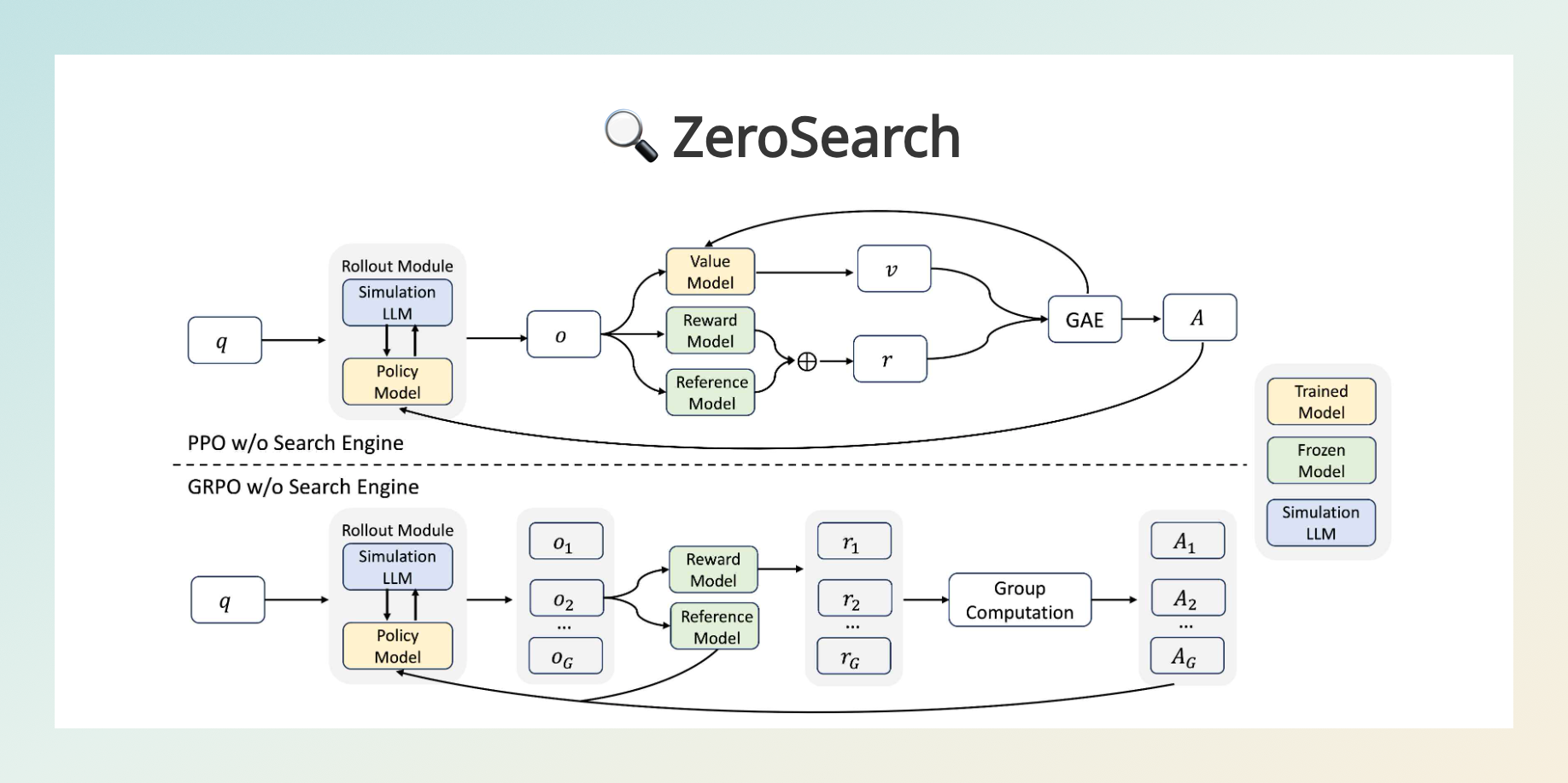
传统的搜索增强训练方法依赖于真实搜索引擎,导致高昂的 API 成本和不可控的文档质量。ZeroSearch 通过模拟搜索过程,成功将训练成本降低了近 88%。例如,使用谷歌搜索 API 训练 64,000 个查询的成本约为 586.70 美元,而使用 14B 参数的模拟模型在四个 A100 GPU 上训练的成本仅为 70.80 美元。
目前,ZeroSearch 已在 GitHub 和 Hugging Face 上开源,提供完整的代码、数据集和预训练模型,支持全球开发者在本地环境中进行训练和部署。这一创新性的框架为中小型企业和研究机构提供了低成本、高效能的解决方案,有望推动 AI 搜索技术的普及与发展。
4. 腾讯发布生图模型:混元图像 2.0
5 月 16 日,腾讯正式发布了 混元图像 2.0 模型(Hunyuan Image2.0),在腾讯混元官方网站上线,并对外开放注册体验。该模型的核心特点为“实时生图”和“超写实画质”。

混元图像 2.0 相较前代模型,参数量提升了一个数量级,得益于超高压缩倍率的图像编解码器以及全新扩散架构,其图像生成速度显著快于行业领先模型。在同类商业产品每张图推理速度需要 5 到 10 秒的情况下,腾讯混元号称可实现毫秒级响应,支持用户可以边打字或者边说话边出图,改变了传统“抽卡 — 等待 — 抽卡”的方式,带来交互体验革新。
除了速度快以外,腾讯混元图像 2.0 模型图像生成质量提升明显,通过强化学习等算法以及引入大量人类美学知识对齐,生成的图像可有效避免 AIGC 图像中的“AI 味”,真实感强、细节丰富、可用性高。
5. OpenAI 推出 Codex 软件工程智能体
5 月 16 日,OpenAI 正式发布了 Codex 智能体,这是一个基于云端的 AI 软件工程助手,通过自动化编程任务,如代码编写、错误修复和测试运行,提升开发者的工作效率。
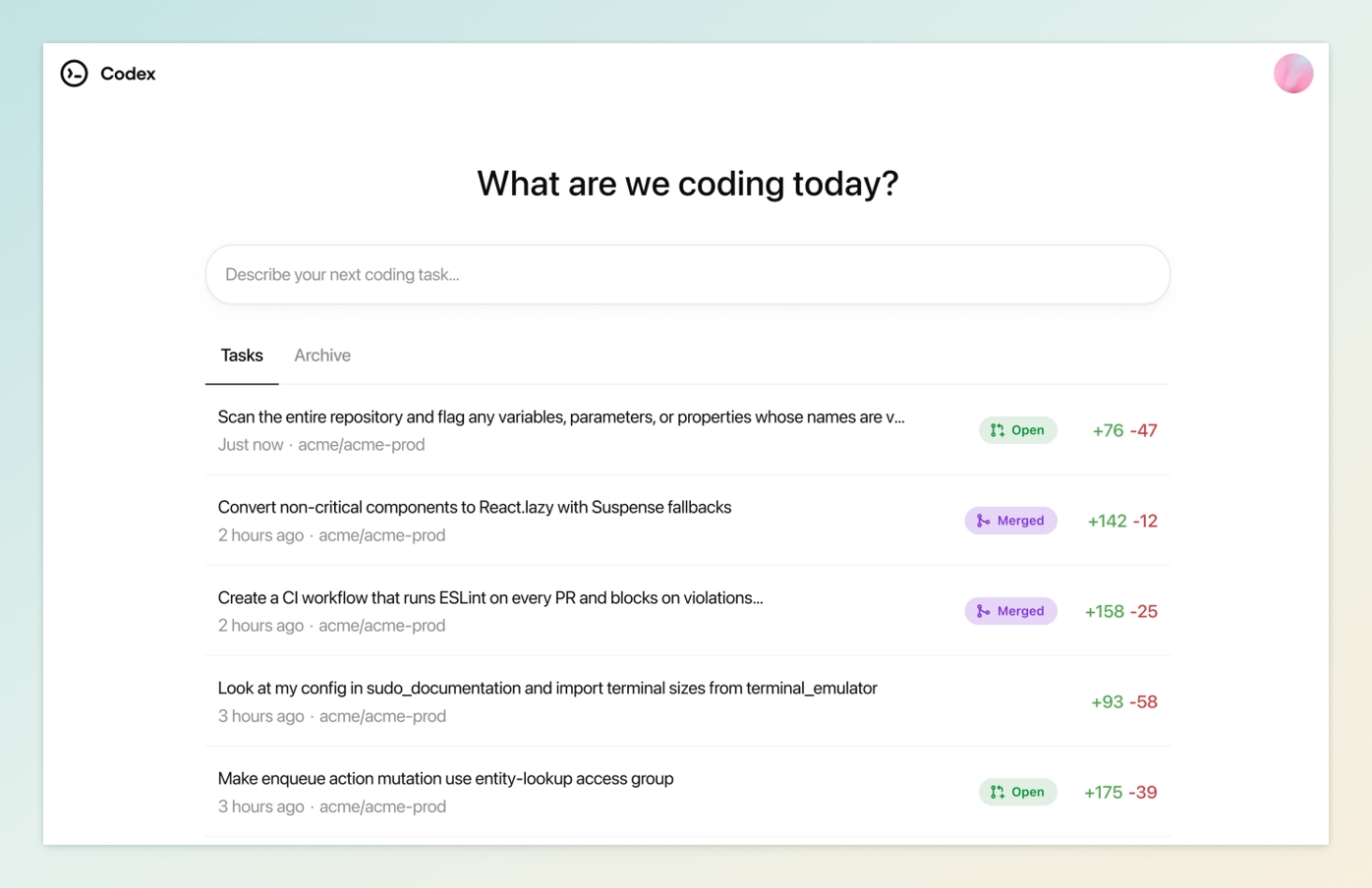
Codex 由 OpenAI 的 codex-1 模型驱动,这是在 o3 推理模型基础上,专为软件开发任务优化的版本。该智能体能够并行处理多个开发任务,包括实现新功能、修复代码错误、回答代码库相关问题,并提出代码审查请求。每项任务都在独立的云端沙盒环境中运行,预加载用户的代码库,确保操作的安全性和隔离性。
与传统的代码自动补全工具不同,Codex 不仅能生成代码,还能在虚拟环境中执行命令、运行测试,并根据测试结果进行迭代优化。此外,Codex 具备解释其操作的能力,帮助开发者理解其生成的代码和修改建议,从而提高协作效率。
Codex 目前已集成至 ChatGPT,面向 ChatGPT Pro、Team 和 Enterprise 用户开放使用。未来,OpenAI 计划将 Codex 的访问权限扩展至 Plus 和 Edu 用户,并持续优化其功能。
6. OpenAI 为 ChatGPT 推出 GPT-4.1 模型
5 月 14 日,OpenAI 正式在 ChatGPT 中上线了全新一代多模态模型 GPT-4.1,并同步推出轻量版 GPT-4.1 mini。

GPT-4.1 被定位为“编程专家模型”,在代码生成、调试、测试和文档撰写等任务中表现出色。相比前代 GPT-4o,新模型在 SWE-bench 编程基准测试中的得分提升了 21%,并支持高达 100 万个 token 的上下文窗口,约为 GPT-4o 的 8 倍,显著增强了处理大型项目和复杂指令的能力。
目前,GPT-4.1 已向 ChatGPT 的 Plus、Pro 和 Team 用户开放,Enterprise 和 Edu 用户将在未来几周内获得访问权限。
同步推出的 GPT-4.1 mini 替代了原有的 GPT-4o mini,成为所有 ChatGPT 用户(包括免费用户)的默认模型。
7. 爆料:ChatGPT 即将支持 MCP 协议
5 月 16 日,科技媒体 bleepingcomputer 发布爆料称,OpenAI 正在测试将 Model Context Protocol(模型上下文协议,简称 MCP)集成至 ChatGPT 的功能,允许用户将第三方服务作为上下文接入 AI 对话流程。这一新功能通过新增的“Connectors”设置,用户可自定义添加工具,输入名称、URL 和描述,使 ChatGPT 能够访问外部应用或 API 的信息。例如,用户可连接 Gmail、日历、数据库等服务,实现更丰富的交互体验。
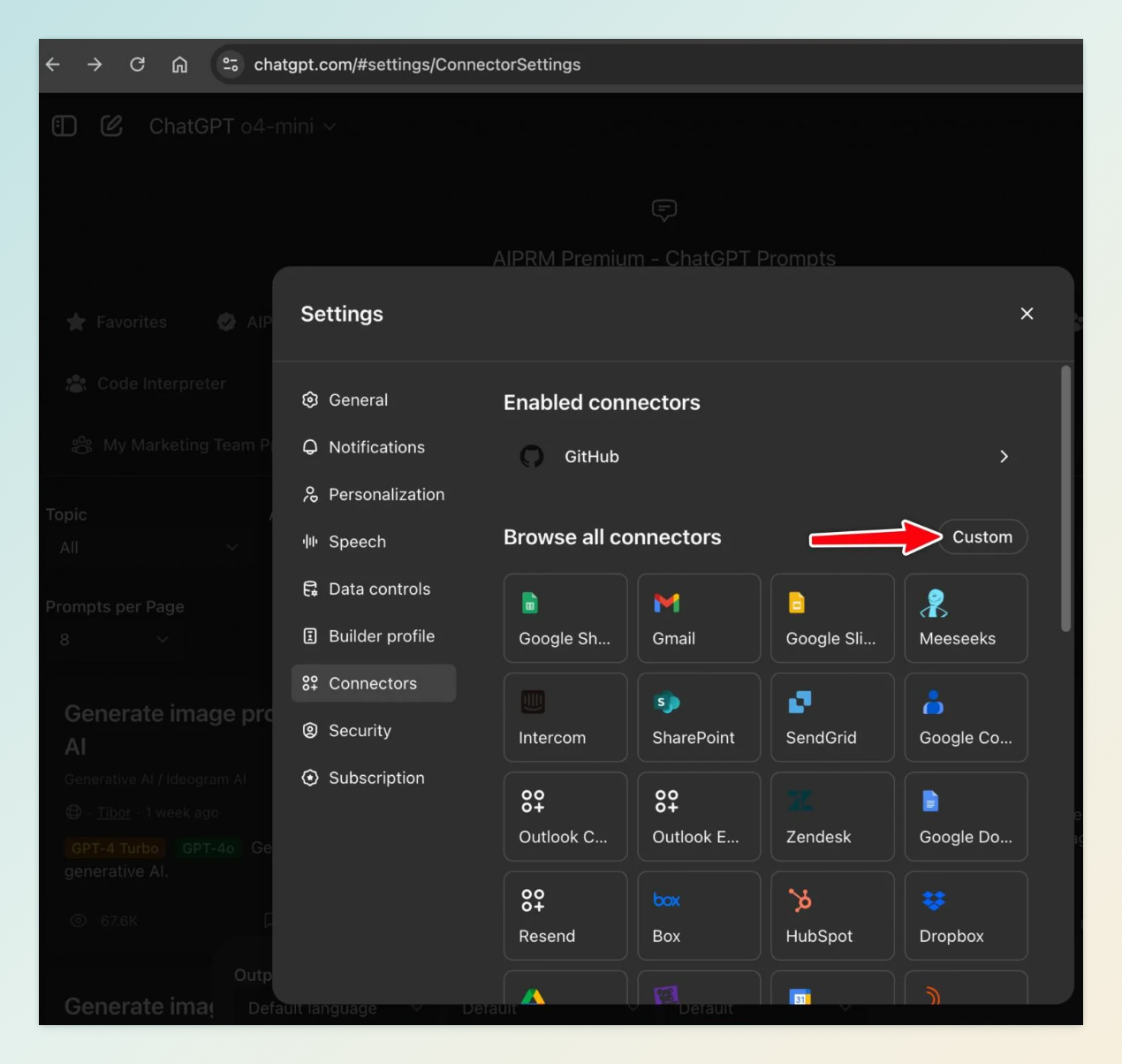
MCP 是由 Anthropic 于 2024 年推出的开源标准,旨在简化 AI 模型与外部工具、数据源的集成流程。通过 MCP,开发者无需为每个数据源编写专属代码,只需一次集成,即可让 AI 系统与多种服务无缝连接。目前,包括 Replit、Codeium 和 Sourcegraph 在内的多家企业已在其 AI 工具中采用 MCP,提升了 AI 系统互操作性。
ChatGPT 对 MCP 的支持功能目前仍处于内部测试阶段,预计 OpenAI 将在未来几天或几周内正式公布。
8. 爆料:OpenAI 计划推出 ChatGPT “Record” 功能
5 月 14 日,X 用户 @M1Astra 发现,OpenAI 正在为 ChatGPT 开发一项名为 “Record” 的新功能,旨在实现实时会议录音、转录和总结。该功能可能会作为 ChatGPT 移动应用中的一项内置工具,允许用户在会议、头脑风暴或想法记录过程中,直接通过应用进行录音,并自动生成文字记录和摘要。
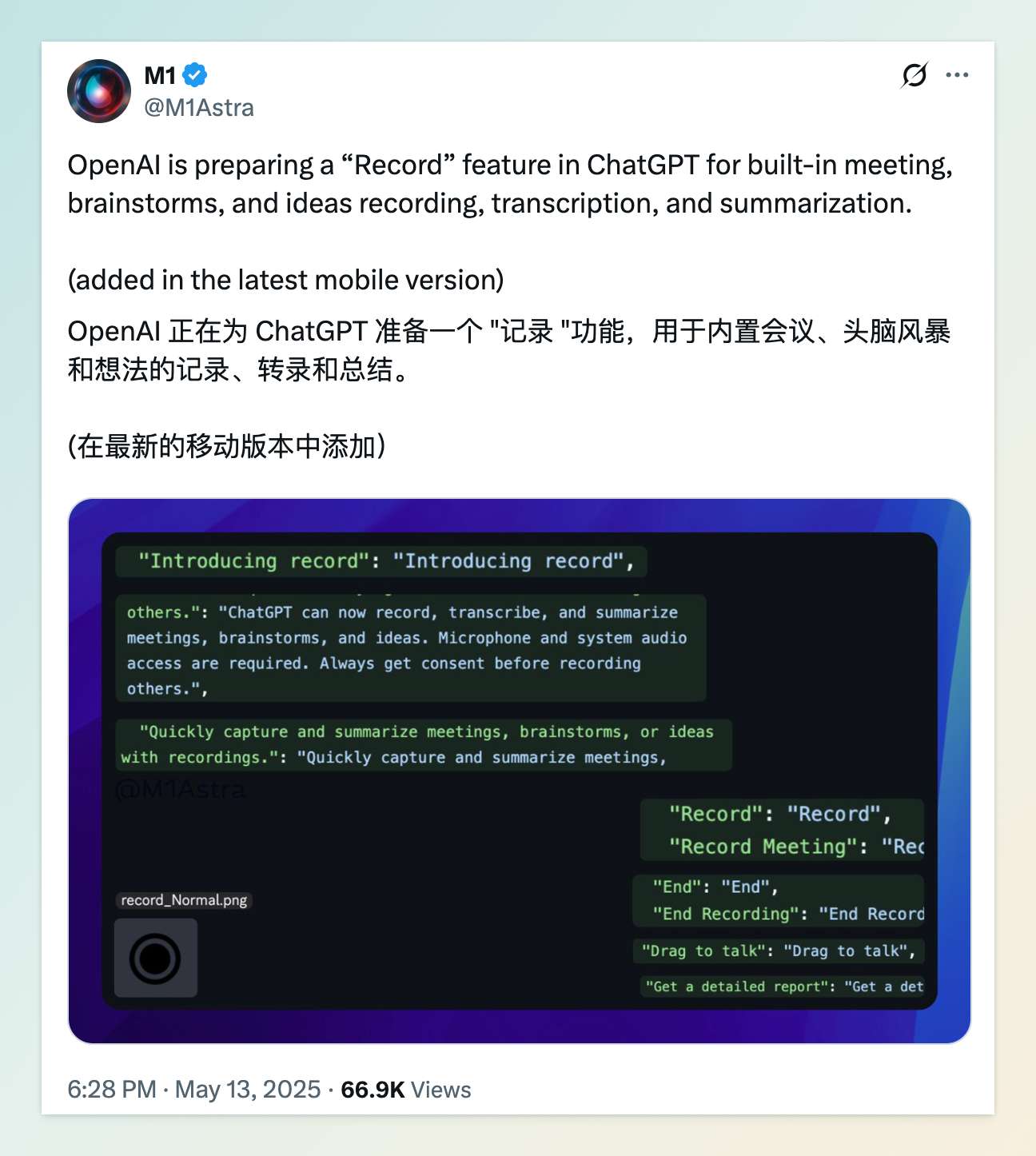
根据泄露的信息,“Record” 功能将包括以下主要特性:
-
实时录音与转录:用户可以在 ChatGPT 应用中启动录音,系统将实时将语音转换为文本。
-
暂停与恢复录音:录音过程中,用户可以随时暂停或恢复录音,确保灵活性。
-
生成详细报告和摘要:录音结束后,ChatGPT 将利用其自然语言处理能力,生成会议的详细报告和简洁摘要,帮助用户快速了解会议要点。
-
用户隐私提示:在录音开始前,应用将请求用户授权访问麦克风和系统音频,并提醒用户在录音前获得其他参与者的同意,以确保隐私合规。
目前,微软 Teams 的 Copilot 已经提供了类似的会议记录和总结功能,但主要面向 Microsoft 365 订阅用户。OpenAI 的“Record”功能如果成功推出,可能会为更广泛的用户群体提供类似的服务,降低使用门槛,尤其对中小企业和个人用户具有吸引力。
目前,OpenAI 尚未正式宣布 “Record” 功能的发布时间和具体细节。
9. Windsurf 发布 SWE-1 系列软件工程模型
5 月 15 日,AI 初创公司 Windsurf(前身为 Codeium)正式发布其首个自研 AI 模型系列 SWE-1,该系列专为软件工程全流程设计,涵盖代码生成、调试、测试、文档生成等多个环节,旨在将开发效率提升至 99%。

SWE-1 系列包括三款模型,分别针对不同的开发场景和用户需求:
-
SWE-1:旗舰模型,具备高级推理和工具调用能力,性能接近Claude 3.5 Sonnet,运行成本更低,现阶段对付费用户开放无限使用。 -
SWE-1-lite:中型模型,替代原有的Cascade Base,性能更优,所有用户(包括免费用户)均可无限次使用。 -
SWE-1-mini:轻量级模型,专为 Windsurf Tab 的被动代码预测功能设计,响应速度快,适合快速场景,同样对所有用户开放。
根据内部评测,SWE-1 在编程任务中的表现与 GPT-4.1 和 Gemini 2.5 Pro 相当,尤其在复杂的多轮任务和工具调用方面表现突出。
目前,开发者可通过 Windsurf Editor 体验 SWE-1 系列模型。
值得一提的是,此前 OpenAI 已与 Windsurf 达成协议,将以约 30 亿美元收购 Windsurf。
10. 爆料:Anthropic 新模型 Claude Neptune 即将发布
5 月 14 日,科技媒体 TestingCatalog News 爆料:Anthropic 正在为其下一代大型语言模型 Claude Neptune 进行最后的内部安全测试,预计将于 5 月 18 日完成红队演练,随后可能在 5 月底或 6 月初正式发布。
Claude Neptune 的红队测试重点在于评估其对越狱攻击的抵抗能力,特别是对 Anthropic 独有的宪法式 AI 安全框架的稳健性进行验证。初步测试结果显示,该模型在处理潜在有害请求时表现出更高的敏感度和防御能力。
在架构方面,Claude Neptune 预计将引入以下关键升级:
-
增强的推理能力,可能在
Claude 3.7的基础上进一步优化“延展思维”功能。 -
更强大的代码生成能力,延续 Claude 系列在开发者社区中的优势。
-
改进的多模态处理能力,提升对图像和文本等复杂输入的理解。
-
可能扩展上下文窗口,超越当前的 200K token 限制。
11. 马斯克:Grok 3.5 仍太粗糙,预计一周内发布
5 月 12 日,埃隆・马斯克在 X 平台上回应网友关于 Grok 3.5、o3 pro 和 GTA 6 哪个将最先发布的提问时表示:“3.5 还是有点太粗糙了。还需要一周左右的时间。

Grok 3.5 是马斯克旗下 xAI 公司开发的下一代大型语言模型,旨在提升 AI 的推理能力和技术问题解答能力。 据马斯克介绍,该模型能够准确回答关于火箭发动机和电化学等复杂技术问题,采用“第一性原理”进行推理,提供不依赖互联网现有内容的原创答案。
Grok 3.5 的测试版预计将在未来一周内向 SuperGrok 订阅用户开放。 此前,Grok 3 于 2025 年 2 月发布,采用了 xAI 的 Colossus 超级计算平台进行训练,具备图像编辑、语音模式和高级推理等功能。
12. Meta 推迟发布 Behemoth 模型
据《华尔街日报》5 月 15 日报道,Meta 公司已将其旗舰 AI 模型 Behemoth 的发布计划推迟至今年秋季或更晚,原因是内部对模型性能的担忧。该模型原定于 4 月在 Meta 首届 AI 开发者大会上亮相,后延期至 6 月,但目前尚未确定具体发布日期。

Behemoth 是 Llama 4 系列中的核心模型,采用混合专家(MoE)架构,拥有约两万亿参数,旨在处理多模态输入。然而,内部工程师在训练过程中遇到技术瓶颈,模型在稳定性和输出一致性方面未达预期,引发了对其发布时机和竞争力的质疑。
此次延期也反映出大型科技公司在 AI 模型开发中面临的共同挑战。例如,OpenAI 的 GPT-5 和 Anthropic 的 Claude 3.5 Opus 也因技术限制而推迟发布。此外,Meta 在 2025 年第一季度的资本支出已达 140 亿美元,全年预计将投入 500 至 580 亿美元用于 AI 基础设施建设,但目前尚未明确 AI 投资的商业化路径,这引发了投资者对其回报的担忧。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。

















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









