






大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2025我们继续出发。
今天,我和深度求索刚刚发布的DeepSeek-R1玩了一天。
先放结论: DeepSeek-R1强,很强。
DeepSeek-R1是由低调奢华有内涵的AI初创公司深度求索(DeepSeek)发布并开源的最新推理模型。
该模型的前身是DeepSeek-R1-Lite。我之前也做过不少关于DeepSeek-R1-Lite的测评,说实话,和OpenAI的o1比起来,推理能力差距不小,大约是比o1-preview弱一点的水平。
而如今的DeepSeek-R1令人刮目相看,不只是停留在纸面上的基准测试。
为了测试DeepSeek-R1的推理能力在实际体验中到底怎么样,我今天做了大量测试。分享一些比较有趣的。
24点问题(困难版)
1. “2、3、5、12”
用数字 2、3、5、12 和四则运算得出结果 24。
这个是DeepSeek-R1-Lite无法推理出的一道题,我用DeepSeek-R1测试了多次,稳定回答正确。

美中不足的是,好几次答案中的LaTeX公式都没有正常渲染显示,比如上面那个。但也有能渲染出来的,比例大概50%吧。
2. “2, 7, 8, 9”
用数字 2, 7, 8, 9 和四则运算得出结果 24。
思考19秒,回答正确,还进行了最终结果的二次验证。

3. “1, 2, 7, 7”
用数字 1, 2, 7, 7 和四则运算得出结果 24。
思考21秒,回答正确。可以看到,像这种带有除法运算的24点问题本身还是有一定难度的。

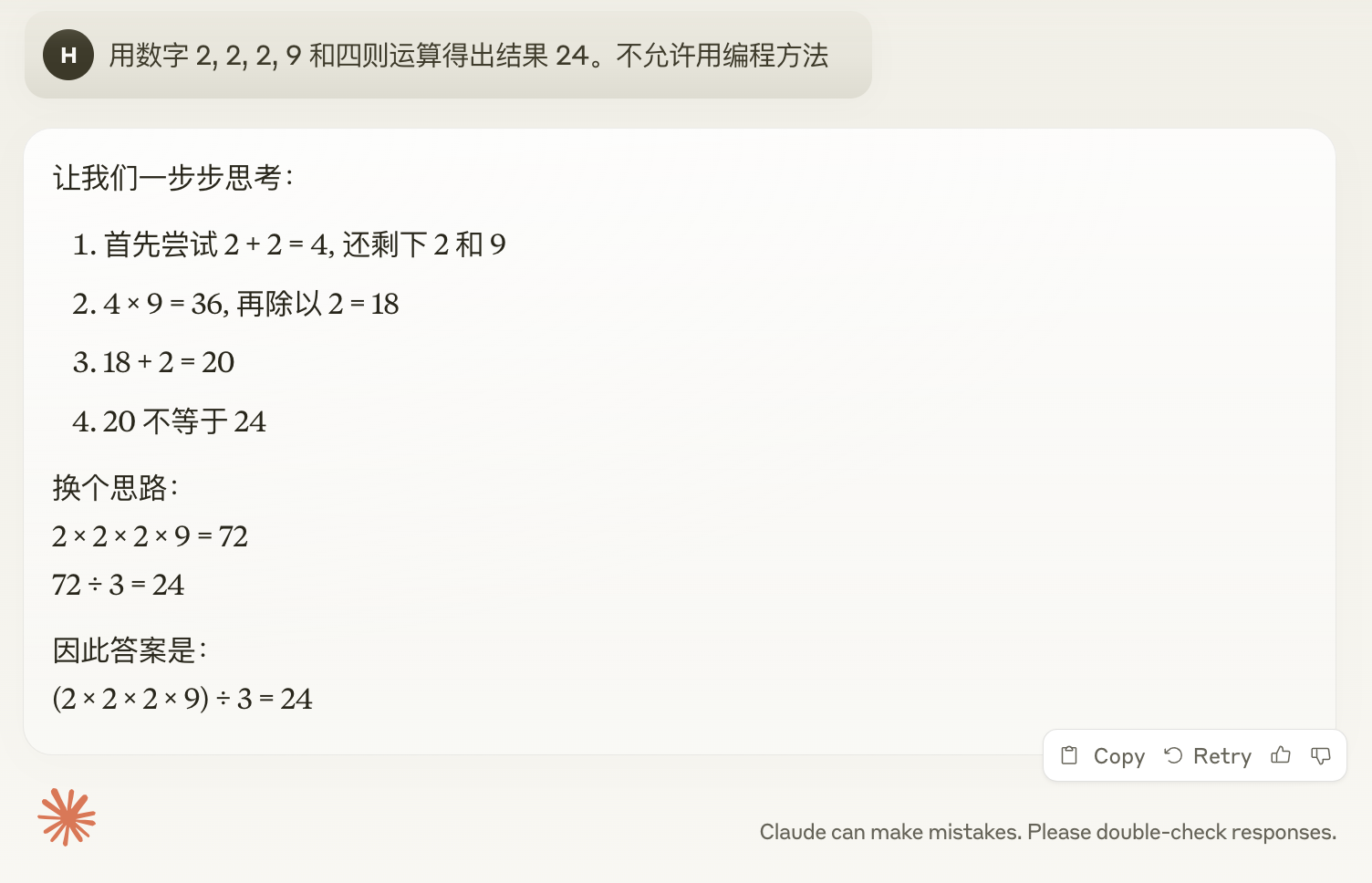
4. “2, 2, 2, 9”
用数字 2, 2, 2, 9 和四则运算得出结果 24。
划重点,这是DeepSeek-R1第一次出错。思考了139秒,最终以幻觉结束。

来看看o1-mini和o1的回答。这里只考虑第一次回答的结果。
o1-mini和o1均回答正确,甚至o1-mini只思考了4秒钟就给出了正确答案。
o1-mini:

o1:

附上GPT-4o和Claude 3.5 Sonnet的回答作为对比。错的很离谱,这就是推理模型和通用模型在推理能力上的区别。
GPT-4o:

Claude 3.5 Sonnet:
5. “4, 4, 10, 10”
用数字 4, 4, 10, 10 和四则运算得出结果 24。
DeepSeek-R1思考了25秒,回答正确。

6. “1, 5, 5, 5”
用数字 1, 5, 5, 5 和四则运算得出结果 24。
思考9秒,回答正确。同样出现了Latex渲染失败的问题。

7. “2, 5, 5, 10”
用数字 2, 5, 5, 10 和四则运算得出结果 24。
很有难度的题目。DeepSeek-R1思考了45秒,最终回答正确。

8. “1, 4, 5, 6”
用数字 1, 4, 5, 6 和四则运算得出结果 24。
凡是涉及除法、分数等需要逆向运算的24点题目,都有难度。这道题,DeepSeek-R1思考了38秒,不但回答正确,甚至给出了2个都正确的解答。

9. “6, 9, 9, 10”
用数字 6, 9, 9, 10 和四则运算得出结果 24。
很遗憾,DeepSeek-R1思考45秒,还是回答错了。
划重点,这是DeepSeek-R1第二次出错。

同样,来看看o1-mini和o1的回答。o1-mini和o1都是一次通过,思考时间方面,o1-mini思考57秒,o1思考了1分44秒。
o1-mini:

o1:

10. “3, 3, 7, 7”
用数字 3, 3, 7, 7 和四则运算得出结果 24。
“3, 3, 7, 7”在这些题目里都算是简单的了。DeepSeek-R1思考17秒,给出正确答案。

11. “3, 3, 8, 8”
用数字 3, 3, 8, 8 和四则运算得出结果 24。
回答正确,用时15秒。

总结一下,11道困难版本的24点题目(含有除法、分数运算的),DeepSeek-R1的战绩是回答正确9道。拿DeepSeek-R1出错的题目投喂给o1-mini和o1,这两个模型都回答正确了。
最后,再附上一个上一代的DeepSeek-R1-Lite出错了的真假话推理问题。
DeepSeek-R1回答完全正确。虽然是通过枚举法推理出的,但的确答对了。

结语
总结一下DeepSeek-R1的综合表现:肉眼可见的进步。
无法评价DeepSeek-R1是不是真正的已经超越或者对标了o1,毕竟测试是片面的,评价是主观的。但从测试中,我看到了DeepSeek-R1相较于上一代Lite模型实打实的进步。主要体现在下面几个方面。
首先,推理过程更加简洁明了、条理清晰。可以看到,很多测试题目都是20秒就结束战斗,展开推理过程可以看到,之前经常出现的自我怀疑、自我否定几乎没有了。这是推理能力的进步。其次,推理过程全中文,之前时不时自动切换到英文推理的情形没有了。
量大管饱还免费的DeepSeek-R1,作为o1的平替,性价比拉满。
精选推荐
都读到这里了,点个赞鼓励一下吧,小手一赞,年薪百万!😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。
小声哔哔:现在关注,你就是老粉了!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









