






好消息,DeepSeek 发布新模型了!
坏消息,不是小可爱们心心念念的 DeepSeek-R2 和 DeepSeek-V4。
而是一个专注于数学证明和复杂推理的模型:DeepSeek-Prover-V2-671B。

此次新模型的发布并开源延续了 DeepSeek 一如既往的低调。
没有任何预热和宣传,Hugging Face 上的 DeepSeek 开源社区悄然上线了这个名为 DeepSeek-Prover-V2-671B 的新模型。
而时间,正好是五一假期的前一刻。
那么,这个新模型是什么来头?
首先划重点,DeepSeek-Prover-V2-671B 不是给你用来聊天、或者运行一般任务的 AI 模型。
实际上,DeepSeek-Prover-V2 可以看作是上一代 Prover-V1.5 的升级版 —— 参数量从 70 亿一下跃升到 6710 亿,重点还是放在 Lean 4 语言下的形式化数学定理证明任务上。
这次升级的一个核心变化,是引入了一个比较特别的冷启动训练流程:用 DeepSeek-V3 作为“引导者”,先把复杂的问题拆解成一个个子目标,再逐步构建对应的证明思路。这个过程中形成的“推理链条”,既包含了问题的分解过程,也保留了完整的数学逻辑路径,最终为大模型提供了一套兼顾非形式化与形式化的训练语料。
不出意外,DeepSeek-Prover-V2 是目前全球最大规模的数学定理证明模型,当然性能也是遥遥领先。
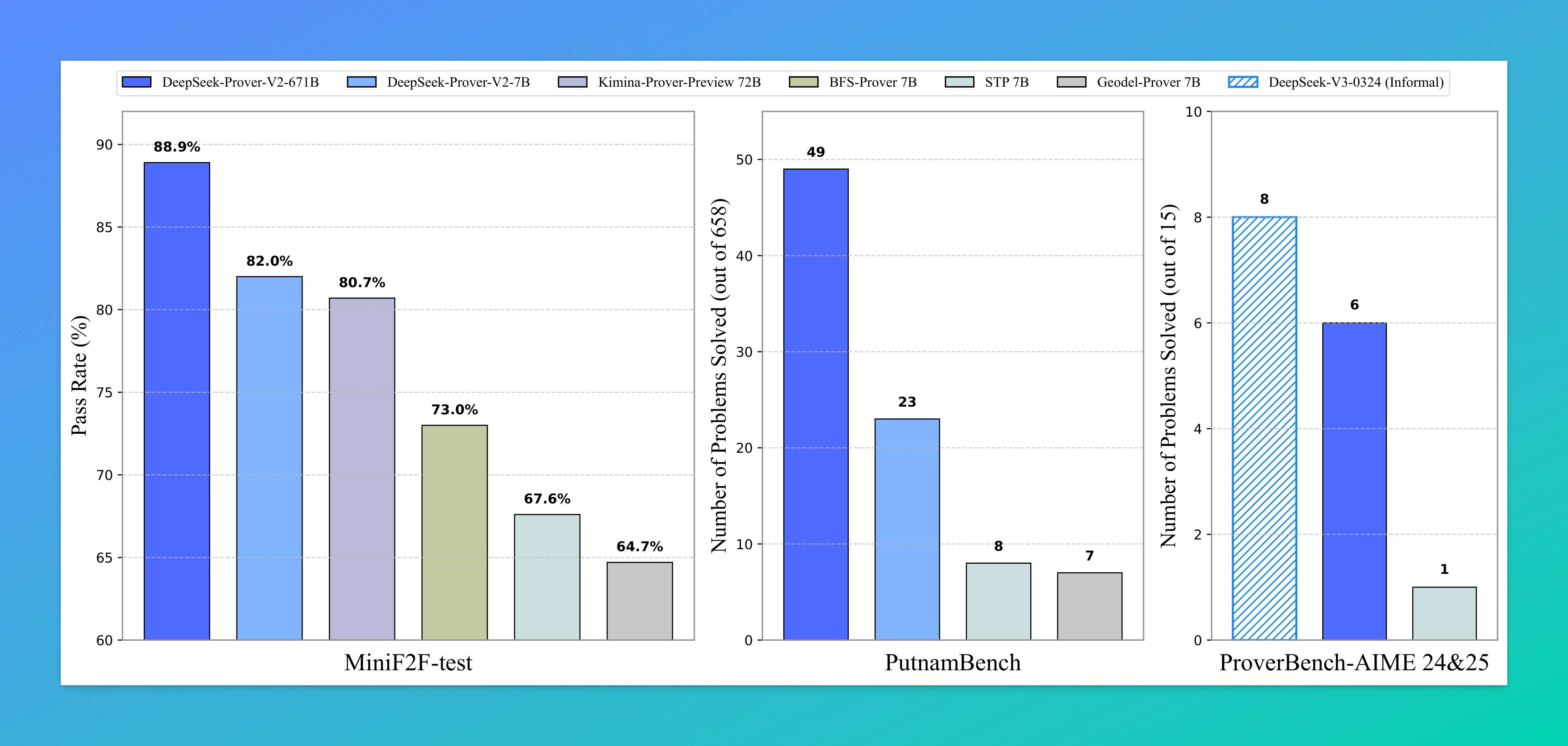
从上面这张对比图可以看出,DeepSeek-Prover-V2 在多个数学评测数据集上都做到了“降维打击”。
不论是针对形式化数学的 MiniF2F-test,还是涵盖北美数学竞赛难题的 PutnamBench,亦或是面向高中竞赛题的 ProverBench-AIME,这个新模型几乎都是碾压式的存在。
简单说几组数字感受一下:
-
MiniF2F-test:88.9% 通过率,远高于同类模型的 70~82%;
-
PutnamBench:一次性解决 49 道题,而前一代 7B 才解出 23 题;
-
AIME 竞赛题子集也能搞定 6 道,仅次于非形式化大模型
DeepSeek-V3的表现。
DeepSeek-Prover-V2 值得关注吗?
如果你是普通用户,大概率不会也不应该直接用它。
但如果你是对数学 AI 感兴趣的开发者或研究者,它的潜力非常具体:
-
对数学论文进行形式化验证,尤其是那些长达数十页、细节繁杂的证明;
-
辅助教材开发:把传统题目变成可验证、可推演的 Lean 格式代码,有助于数学教育;
-
数学研究助理:在探索过程中给出结构合理的“子问题分解 + 初步猜想”。
这里附上 DeepSeek-Prover-V2 模型的 Hugging Face 链接。
https://huggingface.co/deepseek-ai/DeepSeek-Prover-V2-671B
此外,OpenRouter 这个大模型集散地也第一时间上线了免费可用的 DeepSeek-Prover-V2 模型 API 服务。
有需要的小伙伴可以自行“食用”。

结语
虽然不是大家期待的 R2 和 V4,但 DeepSeek 每一次出手,依然让人忍不住多看几眼。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。

















 1946
1946

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









