






两个消息。
一好一“坏”。
好消息,由谷歌最新的 Gemini 2.5 Pro 模型提供支持的 Deep Research(深度研究)正式发布!
坏消息,目前仅 Gemini Advanced 付费会员可体验。

4 月 9 日凌晨,谷歌 AI Studio 产品负责人 Logan Kilpatrick 发帖官宣了这一更新:Gemini App 中的深度研究现已由 Gemini 2.5 Pro 提供支持。
并且,Logan 自豪地表示:相比于某些“其他产品”,用户更喜欢谷歌牌深度研究。
虽然 Logan 并没有直说这个“其他产品”是什么,但明眼人用脚都能猜到,是 OpenAI 的 Deep Research,深度研究。没错,连名字都一模一样。
随后,Gemini 官方账号也跟进了这一更新。
消息一出,立刻得到了广大网友的拍手叫好,一致好评。
帖子下方的画风是这样的。
这是我们一直期盼的!
终于不需要再花 200 美元开通 ChatGPT Pro 了!
谷歌家的 Deep Research(深度研究)绝对值得期待一下。
为什么?
很简单,因为谷歌是第一家推出 深度研究 功能的 AI 厂商。
OpenAI、Perplexity、xAI 都只能划作后来的模仿者。
当然,就 深度研究 功能本身而言,OpenAI 无疑“青出于蓝而胜于蓝”了,效果确实好。
这次集成了 Gemini 2.5 Pro 的深度研究无疑让谷歌和 OpenAI 有了一战之力。
附上谷歌官方给出的 Gemini 深度研究 和 OpenAI 深度研究基准测试对比。
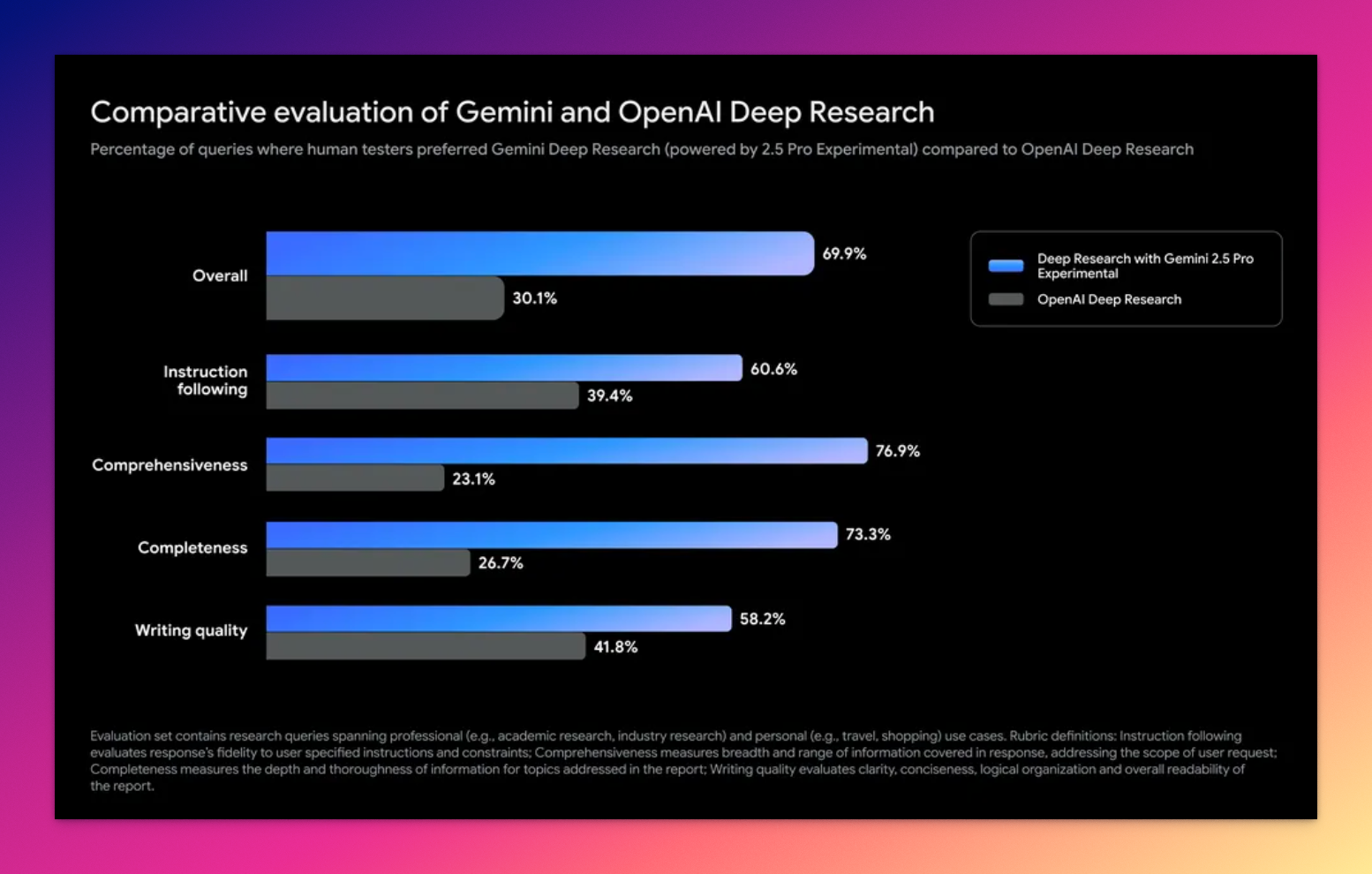
毕竟,Gemini 2.5 Pro 可是制霸各个 AI 模型排行榜单的模型,直到现在依旧是。
LMSYS。

LiveBench。

Aider。
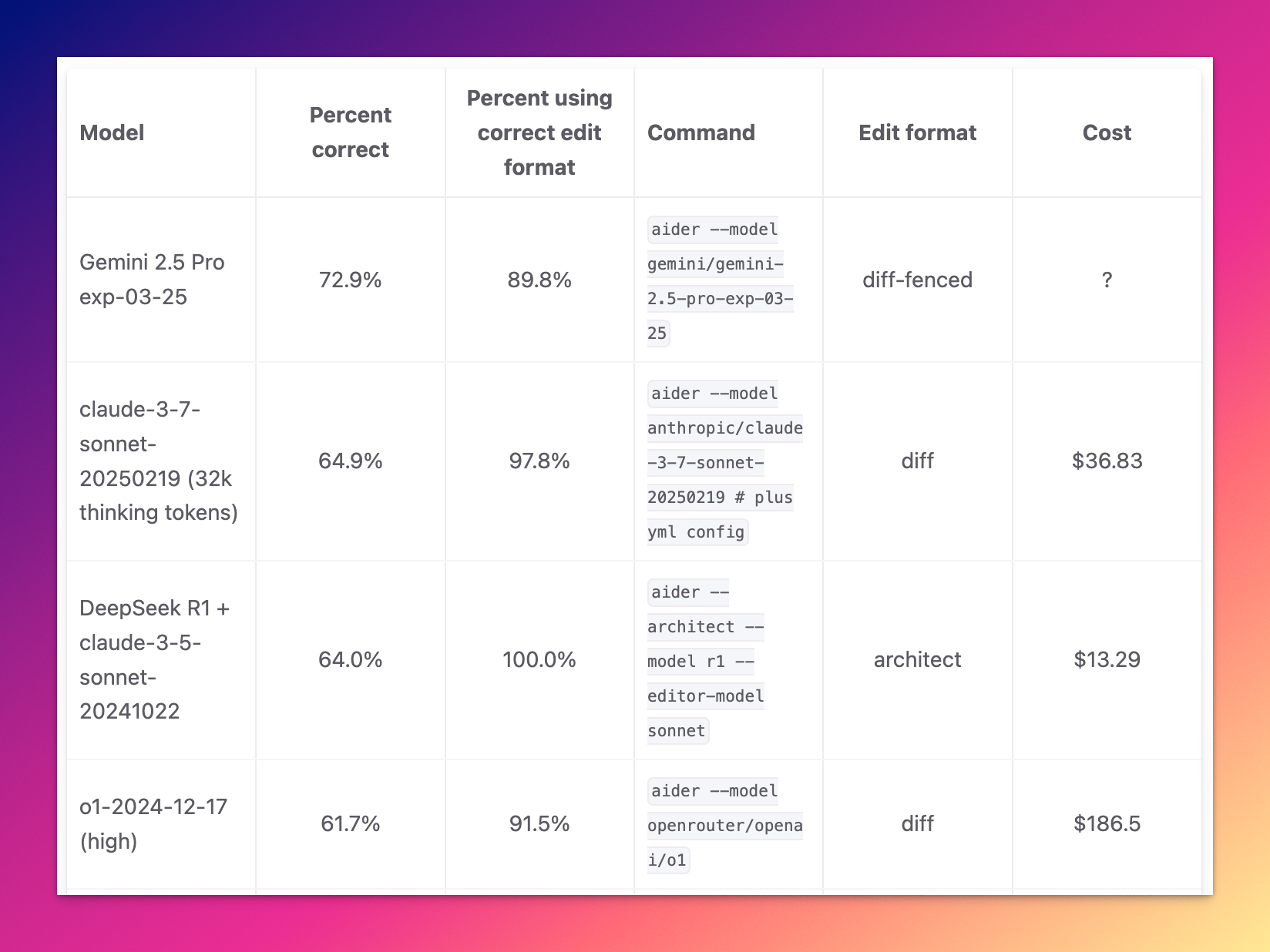
一个第一可能是运气,但全部第一只可能是实力使然了。
再次强调,目前只有开通了 Gemini Advanced 会员的用户可以体验 Gemini 2.5 Pro 版本的深度研究。
并且,Gemini Advanced 会员每天有 20 次深度研究的次数,这一点比起 OpenAI 可以说是非常良心了。因为 ChatGPT Plus 每月只有 10 次深度研究的次数。

Gemini 免费用户的深度研究功能依然由之前的 Gemini 2.0 Flash Thinking 提供支持,次数限制为每月 10 次。
接下来我们实战一波。
测试题目为最近闹得沸沸扬扬的“关税事件”。
中文提示词:请生成一份关于“2025 年 4 月初中美新一轮关税冲突”的深度研究报告。内容请包括:双方政府最新发布的政策公告;此次冲突升级的直接诱因;受影响最显著的行业;国际社会的回应;以及对中短期全球经济可能产生的影响。同时,请分析此次事件对普通消费者、跨境电商从业者、投资者等个人层面的潜在影响,并提出可能的应对建议。报告需结构清晰,并尽可能引用信息来源。
英文提示词:Generate a deep research report on the U.S.-China tariff conflict that escalated in early April 2025. Include the latest policy announcements from both governments, key triggers behind the escalation, impacted industries, international reactions, and projected economic consequences. Also analyze the potential impact on individuals, such as consumers, cross-border e-commerce workers, and investors. Provide practical suggestions on how to respond. Structure the report clearly and cite available sources.
理论上说,中英文提示都可以,但为了让 Gemini 以中文输出结果,便于小可爱们阅读这份报告,测试里我用的是中文提示。
照例,Gemini 会先复述一遍需求。

正在研究 56 个网站。

接着,下一部分的研究数量达到了 101 个网站。
Gemini 真是背靠 “谷歌搜索” 这棵大树好乘凉。

最终,一份名为《2025 年 4 月中美关税冲突升级深度分析》的分析报告出来了。
总字数 15000 字。
共耗时 14 分钟。

总体来看,报告的详尽程度自不必多说,1 万 5 千字不是个摆设。
Gemini 先分析客观事实,整理出了详尽的中美关税摩擦相关的时间线、最终的税率表。
然后分析了中、美以及全球其他国家最受影响的行业、供应链,甚至给出了量化的影响率。
接着是对全球经济、金融市场的影响,包括宏观和微观层面。
最后给出了具体的应对建议和具体措施。
整体文章太长,全部放到文章里不现实,附上这份 34 页的谷歌文档链接,感兴趣的小可爱可以下载查看详情。
https://docs.google.com/document/d/1IXXLbDnVtgVLGr3aWzlt7V-HgbzCtLzu_brihiR7eSs/edit?usp=sharing
结语
这个网友的评论我觉得很有意思,也很赞同。
我是木易,一个专注AI领域的技术产品经理,国内Top2本科+美国Top10 CS硕士。
相信AI是普通人的“外挂”,致力于分享AI全维度知识。这里有最新的AI科普、工具测评、效率秘籍与行业洞察。
欢迎关注“AI信息Gap”,用AI为你的未来加速。

















 1979
1979

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









