









不说环境了,都到了元数据管理,基本的需要的java、maven肯定是不可少的。
编译:
- 官网下载apache-atlas-2.2.0-sources.tar.gz
- 解压 tar -zxvf apache-atlas-2.2.0-sources.tar.gz
- 编译,进入目录 mvn clean -DskipTests package -Pdist
- 编译好了之后进入apache-atlas-sources-2.2.0/distro/target
里面apache-atlas-2.2.0-bin.tar.gz 主包,其他*-hook.tar.gz 是根据需要自己解压使用。
安装配置:
- 解压tar -zxvf apache-atlas-2.2.0-bin.tar.gz 到指定的文件夹。
- 修改配置文件:atlas-env.sh
export JAVA_HOME=/usr/java/jdk1.8.0_181-cloudera
export HBASE_CONF_DIR=/mnt/datadisk0/apps/apache-atlas-2.2.0/conf/hbase/
export MANAGE_LOCAL_HBASE=false
export MANAGE_LOCAL_SOLR=false3.修改配置文件:atlas-application.properties
atlas.graph.storage.backend=hbase2
atlas.graph.storage.hbase.table=apache_atlas_janus
atlas.graph.storage.hostname=master1:2181,master2:2181,master3:2181
atlas.graph.index.search.solr.zookeeper-url=master1:2181/solr,master2:2181/solr,master3:2181/solr
atlas.graph.index.search.solr.http-urls=http://data1:8984/solr
atlas.kafka.zookeeper.connect=master1:2181,master2:2181,master3:2181
atlas.kafka.bootstrap.servers=master1:9092,master2:9092,master3:9092
atlas.audit.hbase.zookeeper.quorum=master1:2181,master2:2181,master3:21814.进到conf/hbase ln -s /etc/hbase/conf conf
5.进入apache-atlas-sources-2.2.0/distro/target 解压
tar -zxvf apache-atlas-2.2.0-hbase-hook.tar.gz
tar -zxvf apache-atlas-2.2.0-hive-hook.tar.gz
tar -zxvf apache-atlas-2.2.0-impala-hook.tar.gz
tar -zxvf apache-atlas-2.2.0-kafka-hook.tar.gz将解压出来的 hook 下级目录 cp 到 /mnt/datadisk0/apps/apache-atlas-2.2.0/hook
6.进conf 文件执行
zip -u /mnt/datadisk0/apps/apache-atlas-2.2.0/hook/hive/atlas-plugin-classloader-2.2.0.jar atlas-application.properties
将atlas-plugin-classloader-2.2.0.jar 复制到每台hveserver2服务器的hive lib 下 /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hive/lib/
7.将conf 下的solr目录拷贝到每台solr节点,并更换目录名称
scp -r /mnt/datadisk0/apps/apache-atlas-2.2.0/conf/solr data1:/opt/cloudera/parcels/CDH/lib/solr/
cd /opt/cloudera/parcels/CDH/lib/solr/
mv solr/ atlas-solr8、创建solr index 和kafka topic
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c vertex_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas-solr -shards 4 -replicationFactor 2 -force
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c edge_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas-solr -shards 4 -replicationFactor 2 -force
/opt/cloudera/parcels/CDH/lib/solr/bin/solr create -c fulltext_index -d /opt/cloudera/parcels/CDH/lib/solr/atlas-solr -shards 4 -replicationFactor 2 -force
./kafka-topics.sh --zookeeper master1:2181,master2:2181,master3:2181 --create --replication-factor 3 --partitions 3 --topic _HOATLASOK
./kafka-topics.sh --zookeeper master1:2181,master2:2181,master3:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_ENTITIES
./kafka-topics.sh --zookeeper master1:2181,master2:2181,master3:2181 --create --replication-factor 3 --partitions 3 --topic ATLAS_HOOK至此,基本配置完成,接下来配置CDH 的 hive.
1.Hive 辅助 JAR 目录 /mnt/datadisk0/apps/apache-atlas-2.2.0/hook/hive
2.hive-site.xml 的 Hive 服务高级配置代码段(安全阀)
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook,org.apache.hadoop.hive.ql.hooks.LineageLogger</value></property>3.hive-site.xml 的 Hive 客户端高级配置代码段
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook,org.apache.hadoop.hive.ql.hooks.LineageLogger</value></property>4.hive-site.xml 的 HiveServer2 高级配置代码段(安全阀)
<property><name>hive.exec.post.hooks</name><value>org.apache.atlas.hive.hook.HiveHook,org.apache.hadoop.hive.ql.hooks.LineageLogger</value></property><property><name>hive.reloadable.aux.jars.path</name><value>/mnt/datadisk0/apps/apache-atlas-2.2.0/hook/hive</value></property>5.HiveServer2 环境高级配置代码段(安全阀)
HIVE_AUX_JARS_PATH=/mnt/datadisk0/apps/apache-atlas-2.2.0/hook/hive配置完成后,重启hive服务,这里需要注意一下,CDH6.2.0 中可以有两个hiveserver2 服务,那么两台服务器都要放置1-8配置好的apache-atlas-2.2.0,文件位置要一致。
配置好了之后,启动atlas ./bin/atlas_start.py
需要手动去加载一下元数据到atals:
/mnt/datadisk0/apps/apache-atlas-2.2.0/bin/import-hive.sh
/mnt/datadisk0/apps/apache-atlas-2.2.0/hook-bin/import-hbase.sh
/mnt/datadisk0/apps/apache-atlas-2.2.0/hook-bin/import-kafka.sh这一步,根据提示解决执行中遇到的问题。因为是使用了一个月后才写的博客,错误都没有保留记录。
登录:hostname:21000 admin/admin
展示一个简单的图:
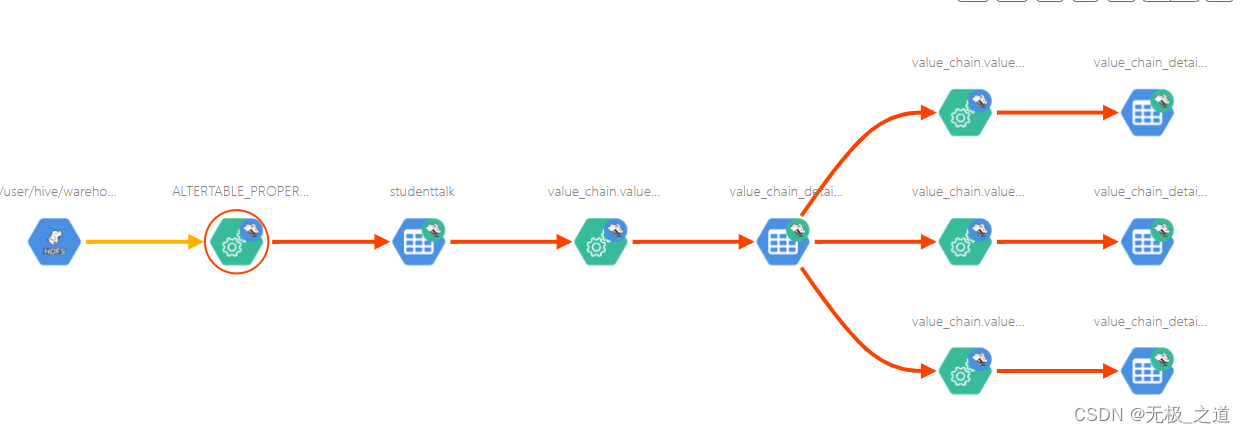
接下来,说一下使用过程中的问题:
1、不知道是我配置不对还是怎么的,需要使用create table a as select * from b 这种方式建表,才会出现血缘关系。直接建表再insert 貌似不会记录(只能代表我个人的使用,很可能配置不对)。
2、hdfs_path 记录一旦录入,即使删除了hdfs上的原始文件,也不会消除,并且使用url方式也删除不了。
3、表删除后,血缘关系不会同时被删除,可以在Deleted 中看到。也可以通过url的方式删除掉。
curl -i -X PUT -H 'Content-Type: application/json' -H 'Accept: application/json' -u admin:admin 'http://master2:21000/api/atlas/admin/purge/' -d '["7fc8fe7a-1fe0-4cb2-94d5-afad467efe1a"]'














 707
707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









