






三种方式根据需要弄哈;增量的,我觉得实际业务中,除非没有update操作才适合使用JDBC这种增量方式,不然都是扯犊子,毕竟hdfs对随机写不是很友好。这是全量的,慢的很。没有sqoop快。
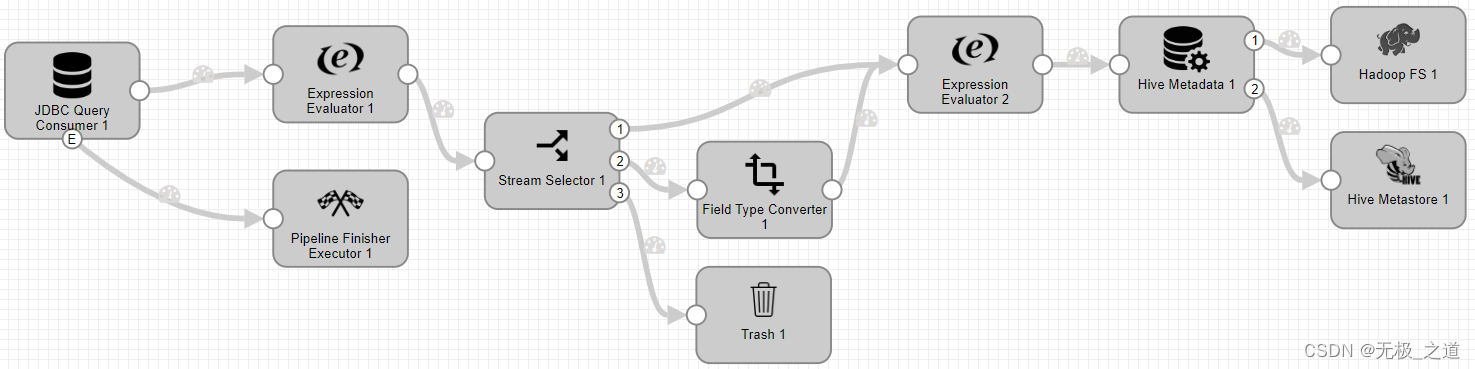
1、JDBC Query Consumer (单表全量)
配置:
JDBC Query Consumer 配置:每天全量同步 不设置offset,SQL Query 写自己的sql 就行。
有时区问题的话,可以
Pipeline Finisher Executor配置:Preconditions ${record:eventType() == 'no-more-data'} ResetOrigin 勾上,全量同步需要重置源。这个组件的作用是,同步完成后关闭pipeline。
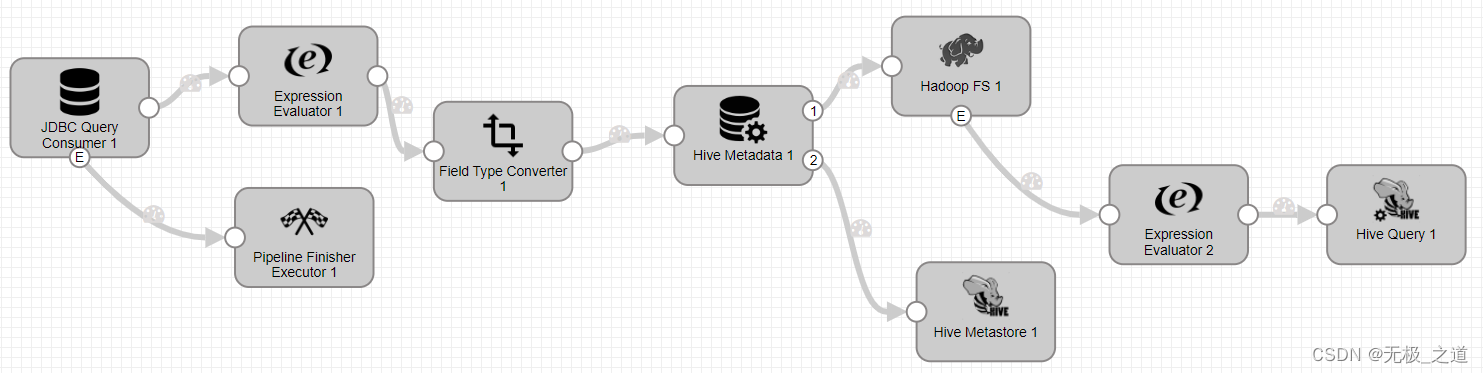
Expression Evaluator 配置:这个组件的作用是,添加value里面的字段或者Header 里面的字段。如果遇到源字段名称和hive表字段名称不一致,可以采用这个,或者添加新的字段,比如hive库的名称,后面可以用。
Field Type Converter 配置:这个是根据字段名更改字段的属性,或者根据属性更改属性。

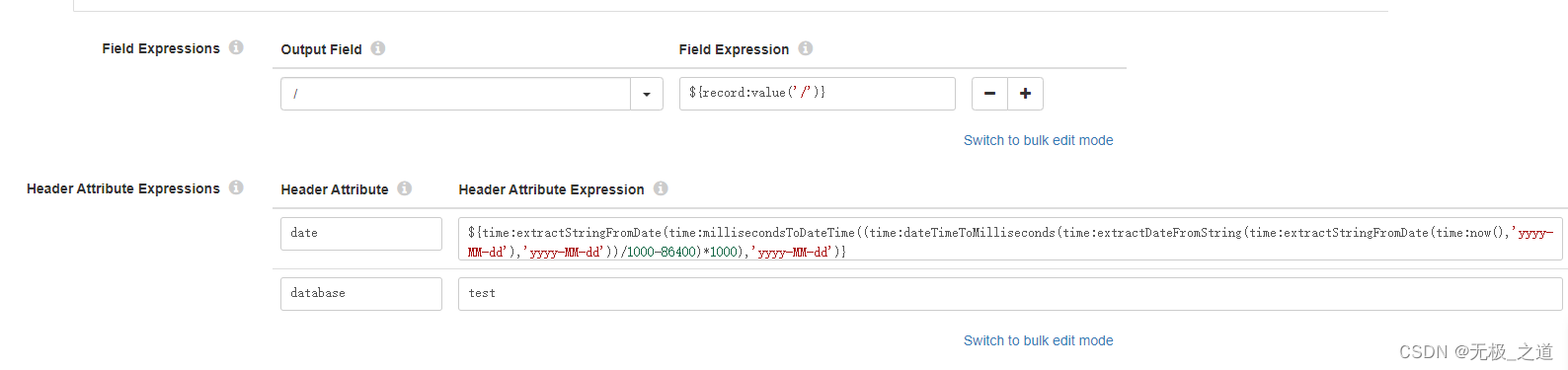
Hive Metadata 配置:入hive 表。配置三个地方,

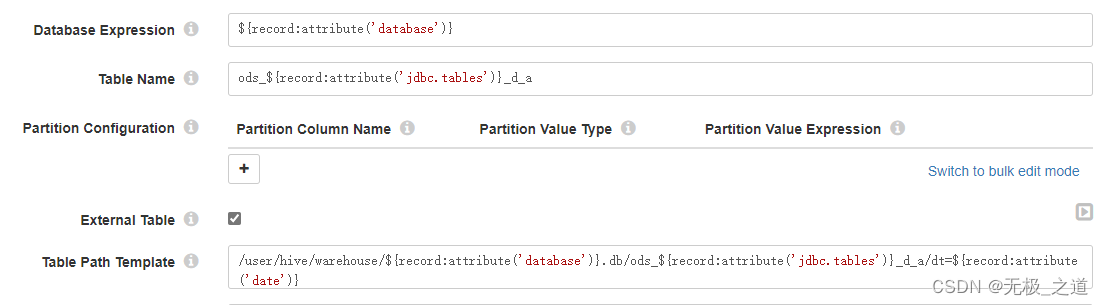
Data Format 设置之前,需要在hive里面创建相应存储方式的表。
Hadoop FS 配置:写hdfs。
Hive Metastore配置:写元数据
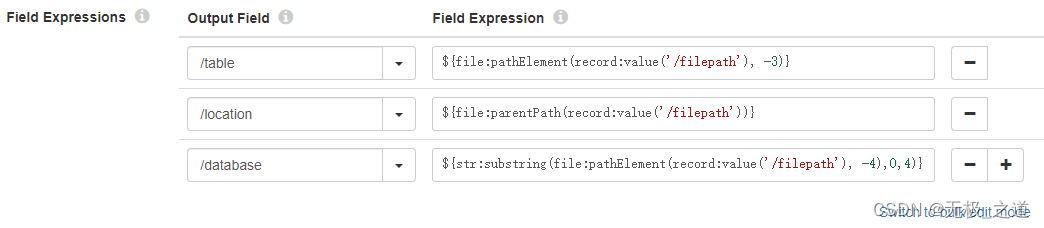
后面的Expression Evaluator 和 Hive Query 是做localtion处理,保证数据能刷进hive。

2、 JDBC Multitable Consumer (单库多表全量)

JDBC Multitable Consumer 配置:对于mysql,jdbc 连接代码写那个库,tables就只能配置那个库。
其他的配置都是差不多的。Hive Metadata配置有差异。

3、分区同步建议使用下面的 (单表分区)
增量分区使用JDBC Query Consumer 用sql语句查出需要的增量,全量分区使用JDBC Multitable Consumer
配置文件很简单。这里不说,有需要的小伙伴可以留言交流。















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









