







网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
三、常用的ETL工具
下面小编将介绍几类ETL工具(sqoop,DataX,Kettle,canal,StreamSets)。
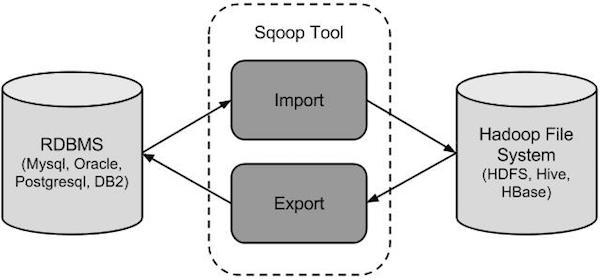
3.1 sqoop
-
是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。
-
可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
-
sqoop命令的本质是转化为MapReduce程序。
-
sqoop分为导入(import)和导出(export),
-
策略分为table和query
-
模式分为增量和全量。

3.2 DataX
-
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台
-
实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。


3.3 Kettle
- 一款国外免费开源的、可视化的、功能强大的ETL工具,纯java编写,可以在Windows、Linux、Unix上运行,数据抽取高效稳定。
3.4 canal
- canal是阿里巴巴旗下的一款开源项目,纯Java开发。基于数据库增量日志解析,提供增量数据实时订阅和消费,目前主要支持了MySQL,也支持mariaDB。

3.5 StreamSets
-
是大数据实时采集ETL工具,可以实现不写一行代码完成数据的采集和流转。通过拖拽式的可视化界面,实现数据管道(Pipelines)的设计和定时任务调度。
-
创建一个Pipelines管道需要配置数据源(Origins)、操作(Processors)、目的地(Destinations)三部分。
四、ETL加载策略
4.1 增量
-
有些表巨大,我们需要选择增量策略,新增delta数据需要和存量数据merge合并。
-
两种方法:
-
merge(一)

-
merge(二)
-
只有新增(full join。能拿更新表就拿更新表)

-
新增+删除
-
history-table Left join delet-table where delect-table.value is null == 表a
-
表a full join update-table (能拿update就拿update)

4.2 全量
每天一个全量表,也可一个hive天分区一个全量。
4.3 流式
使用kafka,消费mysql binlog日志到目标库,源表和目标库是1:1的镜像。
小编有话
无论是全量还是增量的方式,都会浪费多余的存储或通过计算去重,得到最新的全量数据。为解决这一问题,墙裂建议kafka的数据同步方案,源表变化一条,目标表消费一条,目标表数据始终是一份最新全量数据,且为实时同步的。
ps.极端情况下可能会丢数,需要写几个监控监本(详见数据质量篇)和补数脚本即可~
数仓系列传送门:https://blog.csdn.net/weixin_39032019/category_8871528.html

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新















 6092
6092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









