







一.Pip 安装 mlxtend
-
m -> machine(机器) l -> language(学习) ,xtend(扩展) 。 大致理解为机器学习扩展库,mlxtend 主要用来处理数据科学 相关的任务
-
用 pip install mlxtend 安装好 mlxtend
二.写 python 代码
备注:这里采用直接在命令行输入python 进入python cmd编辑环境,运行python代码。
- 从网上导入数据集 并 显示出来
import pandas as pd #导入数据分析包
from mlxtend.frequent_patterns import apriori #导入 apriori 算法
from mlxtend.frequent_patterns import association_rules #导入关联规则
df=pd.read_excel('http://archive.ics.uci.edu/ml/machine-learning-databases/00352/Online%20Retail.xlsx') #获取excel 数据
df.head() #获得数据前几行数据1-1.可能回出现 no moudle name xlrd , 因为 pandas读取excel 需要 xlrd,用命令: pip install xlrd 即可。

1-2.这里是显示了前几行的数据集

- 数据预处理–删除无效值
df['Description'] = df['Description'].str.strip() #选取Description字段去除首尾空格
df.dropna(axis=0, subset=['InvoiceNo'], inplace=True) #删除发票ID"InvoiceNo"为空的数据记录
df['InvoiceNo'] = df['InvoiceNo'].astype('str') #将发票ID"InvoiceNo"字段转为字符型
df = df[~df['InvoiceNo'].str.contains('C')] #删除发票ID"InvoiceNo"包含“C”的记录2-1:我们来看看一共删除了多少 InvoiceNo 字段 包含c的记录
刚开始的数据行数:
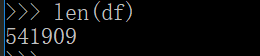
删除 包含c 之后的行数:

3. 数据清理完成后,我们需要将每个产品进行one-hot编码。为了保持数据集小,我选择只是看法国的销售记录
import numpy as np
basket = df[df['Country'] =="France"].pivot_table(columns = "Description",index="InvoiceNo",values="Quantity",aggfunc=np.sum).fillna(0)
basket.head() 4.数据预处理–将购物数量转为0/1变量
0:此订单未购买包含列名
1:此订单购买了列名商品
def encode_units(x):
if x <= 0:
return 0
if x >= 1:
return 14-1.使用dataframe的applymap函数,将encode_units在basket中的每个单元格执行并返回、删除购物篮中的邮费项(POSTAGE)
basket_sets = basket.applymap(encode_units)
basket_sets.drop('POSTAGE', inplace=True, axis=1)5.使用apriori进行关联规则运算
#我们可以生成支持度大于0.07%的频繁项集(选择此数字以便我可以获得足够的有用示例):
frequent_itemsets = apriori(basket_sets, min_support=0.07, use_colnames=True)
#最后一步是生成规则及其相应的suport,confidence和lift
rules = association_rules(frequent_itemsets, metric="lift", min_threshold=1)
rules.head()
5.1:这是最后分析的结果
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









