







一 operator使用
1 SparkSqlOperator
from airflow.operators.spark_sql_operator import SparkSqlOperator
# 额外参数
num_executors = 10
extral_spark_conf = """"
spark.dynamicAllocation.enabled=false,
spark.executor.memoryOverhead=2G,
spark.speculation=true,
spark.speculation.interval=50000,
spark.speculation.quantile=0.95,
spark.speculation.multiplier=1.5,
spark.sql.broadcastTimeout=-1,
spark.default.parallelism=partitions_var,
spark.sql.shuffle.partitions=partitions_var
""".replace('\n', '').replace(' ', '').replace('"', '').replace('partitions_var', str(num_executors*4))
## 创建SparkSqlOperator任务
spark_task = SparkSqlOperator(
task_id = table_name + '_task',
name = 'flag#' + table_name,
master = 'yarn',
yarn_queue = 'default',
num_executors = num_executors,
executor_cores = 2,
executor_memory = '12G',
driver_memory = '1G',
sql = spark_sql.replace('partitions_var', str(num_executors*4)),
conf = extral_spark_conf,
queue = '',
dag = main_dag
)
注意:
1) extral_spark_conf参数中要去掉换行、空格和两端的双引号;
三、高级用法
1 airflow分支
Airflow的BranchPythonOperator如何工作?
四、注意事项
1 上线注意
1 暂时关闭SLA, 避免误报警;
2 暂时关闭catchup=True, 避免跑大量历史任务;
3 调试完成后, 打开以上通能;
五、性能优化
1. 节点越多延时越大,去掉无用的节点;
六、 配置全局变量
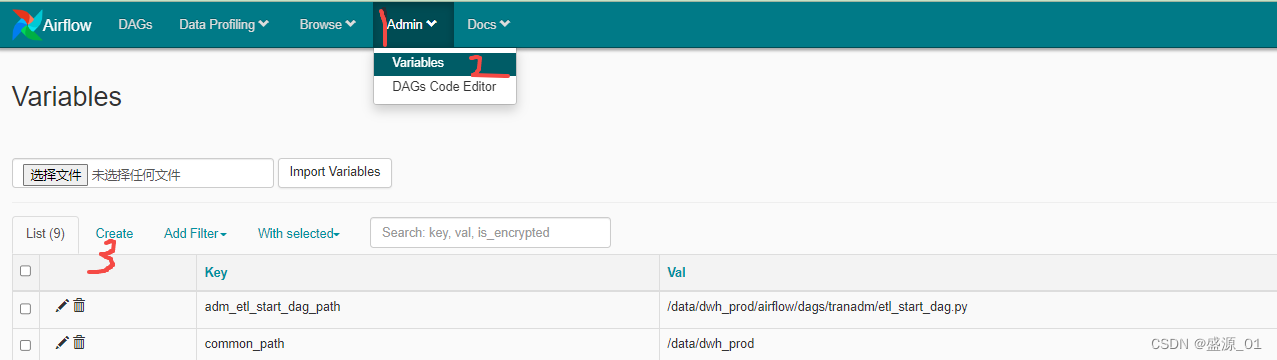
#读取airflow的配置的变量
from airflow.models import Variable
foo = Variable.get("name")
print(foo)二十、待整理
依赖历史设置打开,如果是动态生成的任务的DAG,对于新增任务无法启动,可以把该设置只放在静态任务上;
SLA设置打开,如果是动态生成的任务的DAG,对于新增任务会误报警,可以把该设置只放在静态任务上;















 2897
2897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









