







一、表的加法 union
两个查询结果的上下拼接,只要求两个查询结果有相同的列数。
/*表的加法*/
-- 重合的数据保留一个 union
select 课程号,课程名称 from course
union
select * from course1;
-- 只要有相同的列数,列不对应也能简单粗暴地拼接在一起。
select 课程名称,课程号 from course
union
select * from course1;
-- 重合的数据全部保留 union all
select 课程号,课程名称 from course
union all
select * from course1;

二、表的联结 join
1.交叉连接(笛卡儿积)
查询结果是两张表行数的乘积
/*表的联结*/
-- 笛卡尔连接
select student.姓名,course.课程名称 from student,course;
#select 姓名,课程名称 from student,course;
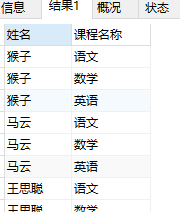
案例
temp表如下

1).简单笛卡尔积
-- 取fuid、cate两个字段,自连接成笛卡尔积
-- 结果是个乘积 m*m:不同人和项目,各种两两匹配
select * from
(select fuid,cate from temp group by fuid,cate) a,
(select fuid,cate from temp group by fuid,cate) b
--同义写法(Oracle等数据库不支持这种写法)
select * from
(select fuid,cate from temp group by fuid,cate) a
join
(select fuid,cate from temp group by fuid,cate) b

2).添加条件
-- 添加条件,只取同一个人的匹配关系
select * from
(select fuid,cate from temp group by fuid,cate) a,
(select fuid,cate from temp group by fuid,cate) b
where a.fuid=b.fuid
--同义写法
select * from
(select fuid,cate from temp group by fuid,cate) a
join
(select fuid,cate from temp group by fuid,cate) b
on/where a.fuid=b.fuid

3).筛选过滤
-- 指定一项为互动一项游乐
-- 以下得到的是消费过一种为互动,另一种为游乐的人
select * from
(select fuid,cate from temp group by fuid,cate) a,
(select fuid,cate from temp group by fuid,cate) b
where a.fuid=b.fuid and a.cate='互动' and b.cate='游乐' --a和b的位置可以互换
--同义写法
select * from
(select fuid,cate from temp group by fuid,cate) a
join
(select fuid,cate from temp group by fuid,cate) b
on/where a.fuid=b.fuid and a.cate='互动' and b.cate='游乐'
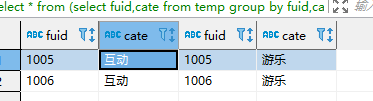
4).添加集合条件
-- 添加条件:消费品类数是2种的人
select * from
(select fuid,cate from temp group by fuid,cate) a,
(select fuid,cate from temp group by fuid,cate) b,
(select fuid from temp group by fuid having count(distinct cate)=2) c --消费2种品类的人
where a.fuid=b.fuid and a.cate='互动' and b.cate='游乐' --a和b的位置可以互换
and a.fuid=c.fuid
--同义写法1
select * from
(select fuid,cate from temp group by fuid,cate) a
join
(select fuid,cate from temp group by fuid,cate) b
on a.fuid=b.fuid and a.cate='互动' and b.cate='游乐'
join
(select fuid from temp group by fuid having count(distinct cate)=2) c
on a.fuid=c.fuid
--同义写法2
select * from
(select fuid,cate from temp group by fuid,cate) a
join
(select fuid,cate from temp group by fuid,cate) b
join
(select fuid from temp group by fuid having count(distinct cate)=2) c
where a.fuid=b.fuid and a.cate='互动' and b.cate='游乐' and a.fuid=c.fuid
2.内联结 inner join … on
两张表有共同的字段,这个字段使者两张表产生联系,内联结只取两张表都有的数据。
-- 内联结
#找到两张表的联结字段-学号
select student.*,score.* from student
inner join
score
ON
student.学号=score.学号;
# 使用别名
#一旦定义了别名,其他地方,直到select部分也要使用别名
# 如st.*,sc.*,st.学号=sc.学号,如果仍然使用原表名则会报错
select st.*,sc.* from student as st
inner join
score as sc
ON
st.学号=sc.学号;
3.左联结 left join…on
两张表有共同的字段,这个字段使者两张表产生联系,左联结保留左表的所有数据,右表缺失的数据以Null填充。
-- 左连接 left join
select student.*,score.* from student
left join
score
ON
student.学号=score.学号;
#只查询左表有右表无数据
select st.*,sc.* from student as st
left join
score as sc
ON
st.学号=sc.学号
where sc.学号 IS NULL;

4.右联结
两张表有共同的字段,这个字段使者两张表产生联系,右联结保留左表的所有数据,左表缺失的数据以Null填充。
原理同左联结
5.全联结
两张表有共同的字段,这个字段使者两张表产生联系,全联结保留左表和右表的所有数据,两外一张表缺失的数据以Null填充
MySQL不支持全联结,但是可以用 【左联结】 union 【右联结】实现
6.总结

7.运行顺序
- 子查询
- from --> on --> join --> where --> group by --> having
- order by -->limit
- select
8.复杂关联
关联的原理是找到关联的条件,但一个条件不能满足关联时,可以使用多个条件


可以看到,由于2个张三,单独使用姓名并不能定位到唯一的学生,数据会发生重复

这是需要两个条件:班级和姓名才能同时定位到准确的学生

三、联结的应用案例
1.步骤
a.翻译成大白话
b.写出分析思路
c.写出对应的sql语句
2.实例-两张表联结
问题:查询所有学生的学号、姓名、选课数、总成绩
- 分析1:先分组后联结
a.翻译
学号来自student表或者score表,并且是这两个表的联结键,姓名来自学生表,选课数是score表通过对学号分组后的计数结果,总成绩是score表对学号分组后成绩字段的求和汇总结果,因此将student表和汇总表左联结并去除需要的字段。
b.思路
-- 主语句
select [学号、姓名、选课数、总成绩]
from [student表]
join [子查询:score的分组汇总表]
on [student.学号=汇总表.学号]
where [无]
group by [无]
having [无]
order by [无]
limit [无]
-- 子查询:score的分组汇总表
select [学号、选课数、总成绩]
from [score表]
join [无]
on [无]
where [无]
group by [学号]
having [无]
order by [无]
limit [无]
c.语句
/*业务*/
select student.学号,student.姓名,groupscore.选课数,groupscore.总成绩
from student
join
(select 学号,count(*) as 选课数,sum(成绩) as 总成绩 from score group by 学号) as groupscore
on student.学号=groupscore.学号;
#括号里面的子查询必须要出现学号这个字段,因为需要它参与join on联结

- 分析2:先联结后分组
a.翻译:
字段最终来自student表和score表,先将这两张表联结成一个达标,里面涵盖所有数据,再将这张大表分组、运算,选出需要的字段。
b.思路
select [学号、姓名、选课数、总成绩]
from [student表]
join [score表]
on [student.学号=score.学号]
where [无]
group by [学号]
having [无]
order by [无]
limit [无]
c.语句
#count(score.*)会报错,这张大表形成后score.*不能被使用,应该使用score表的具体某个字段
select student.学号,student.姓名,/*count(score.*)*/count(score.学号),sum(score.成绩)
from student
left join
score
on
student.学号=score.学号
group BY
/*score.学号*/student.学号;
# 分组应该以student表的学号字段

3.练习
问题:查询平均成绩大于85的所有学生的学号、姓名和平均成绩
分析:方法与实例是一样的,不同之处在于修改汇总函数并添加条件。由于平均成绩>85是基于分组之后,所以条件一定要排在在分组之后。
#先分组后联结 条件放在where语句中
select student.学号,student.姓名,groupscore.平均成绩
from student
left join
(select 学号,avg(成绩) as 平均成绩 from score group by 学号) as groupscore
on student.学号=groupscore.学号
where groupscore.平均成绩>85;
#先联结后分组 条件放在having语句中
select student.学号,student.姓名,avg(score.成绩) as 平均成绩
from student
left join
score
on
student.学号=score.学号
group BY
student.学号
having 平均成绩>85;
4.实例-三表联结
问题:查询学生的选课情况-学号、姓名、课程号、课程名称
分析:学号、姓名来自student表,课程号、课程名称来自course表,但是两张表之间没有直接联系,因此需要一张中间表联结,而score既有课程号,又有学号,可以联结两张表。
select [学号、姓名、课程号、课程名称]
from [student表]
left join [score表]
on [student.学号=score.学号]
join [course表]
on [score.课程号=course.课程号]
where [无]
group by [学号]
having [无]
order by [无]
limit [无]
select student.学号,student.姓名,course.课程号,course.课程名称
from student
left join score
on student.学号=score.学号
left join course
on
score.`课程号`=course.`课程号`;

四、case表达式
1.简介和语法
case子句用于条件判断
case when <判断表达式> then <表达式>
when <判断表达式> then <表达式>
when <判断表达式> then <表达式>
...
else <表达式>
end
2.基础用法
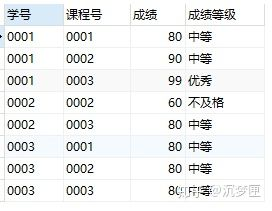
-- 添加一列,将成绩表区分等级
SELECT
*,
(
CASE
WHEN 成绩 < 70 THEN
'不及格'
WHEN 成绩 > 90 THEN
'优秀'
ELSE
'中等'
END
) AS 成绩等级
FROM
score;
3、结合汇总函数
构建新的字段
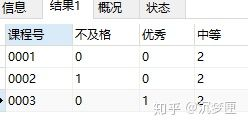
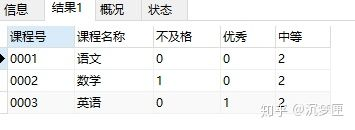
-- 查询每门课的每种成绩等级的人数
SELECT
课程号,
SUM(CASE WHEN 成绩 < 70 THEN 1
ELSE 0
END) as 不及格,
SUM(CASE WHEN 成绩 > 90 THEN 1
ELSE 0
END) as 优秀,
SUM(CASE WHEN 成绩 BETWEEN 70 and 90 THEN 1
ELSE 0
END) as 中等
FROM
score
group by 课程号;

4.注意事项
-
else可以不写
-
end一定要写
5.case子句结合联结使用
-- 按成绩定义分组,并且将每门课(显示课程号和课程名称)在各个分组下的人数统计出来
SELECT
score.课程号,course.`课程名称`,
SUM(CASE WHEN 成绩 < 70 THEN 1
ELSE 0
END) as '[< 70]',
SUM(CASE WHEN 成绩 > 90 THEN 1
ELSE 0
END) as '[> 90]',
SUM(CASE WHEN 成绩 BETWEEN 70 and 90 THEN 1
ELSE 0
END) as '[70-90]'
FROM
score
right join course on score.`课程号`=course.`课程号`
group by score.课程号,course.`课程名称`;
#group by多条件分组,由于课程号和课程名称是一一对应的, 因此不会产生新的分组















 5255
5255











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









