









阅读时间:2023-12-25
1 介绍
年份:2017
作者:尹在弘,北卡罗来纳大学教堂山分校博士后;杨恩浩,韩国科学技术院
期刊: 未发表
引用量:1232
代码:https://github.com/jaehong31/DEN
Yoon J, Yang E, Lee J, et al. Lifelong learning with dynamically expandable networks[J]. arXiv preprint arXiv:1708.01547, 2017.
提出了一种动态可扩展网络网络(Dynamically Expandable Network,DEN)DEN是一种有效的终身学习深度神经网络,能够在学习新任务的同时保持对旧任务的记忆,并且能够动态地调整自身的网络容量以适应新知识。DEN可以根据新任务的需求,通过增加或分裂/复制单元并进行时间戳标记来动态扩展网络容量。当现有网络不足以解释新任务时,DEN能够动态地增加网络容量,仅添加必要的单元数量。通过单元分裂/复制和时间戳标记,DEN有效防止了语义漂移(semantic drift),即网络在训练过程中逐渐偏离初始配置,导致对早期任务的性能下降。
2 创新点
- 动态可扩展网络架构(DEN):一种新型的深度学习架构,能够根据任务序列动态调整网络容量,以适应不同任务的需求。
- 选择性重训练机制:DEN通过选择性地重训练网络中与新任务相关的部分,而不是整个网络,从而提高了学习效率并减少了计算开销。
- 动态网络容量调整:根据新任务与旧任务的相关性,DEN能够决定是否需要扩展网络容量,以及需要添加多少神经元,这通过群组稀疏正则化来实现。
- 防止语义漂移的策略:通过单元分裂/复制和时间戳标记,DEN有效避免了在连续学习过程中对旧任务性能的负面影响,即所谓的“灾难性遗忘”。
- 在线学习与批量学习的比较:论文中的实验表明,DEN在终身学习场景下,即使使用较少的参数,也能与批量训练模型达到相似的性能水平,并且在所有任务上进一步微调后,性能甚至超过了批量模型。
- 跨数据集验证:作者在多个公共数据集上验证了DEN的有效性,包括MNIST-Variation、CIFAR-100和AWA数据集,证明了模型的泛化能力和适应性。
- 结构化稀疏性的应用:在初始训练阶段,通过应用L1正则化来促进权重的稀疏性,使得每个神经元只与下一层的少数神经元连接,这有助于在后续任务中更有效地选择性重训练。
- 时间戳推理机制:在推理过程中,DEN使用时间戳来确定每个任务应该使用的网络参数,这进一步确保了旧任务不会因为新加入的单元而受到语义漂移的影响。
3 相关研究
- 终身学习 (Lifelong learning):
- Thrun, S. (1995). A lifelong learning perspective for mobile robot control.
- 在线终身学习框架 (Online lifelong learning framework):
- Eaton, E., & Ruvolo, P. (2013). ELLA: An efficient lifelong learning algorithm.
- 深度学习中的终身学习 (Lifelong learning in deep learning frameworks):
- Rusu, A. A., et al. (2016). Progressive neural networks.
- Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks.
- Zenke, F., et al. (2017). Continual learning through synaptic intelligence.
- Lee, S.-W., et al. (2017). Overcoming catastrophic forgetting by incremental moment matching.
- 防止灾难性遗忘 (Preventing catastrophic forgetting):
- Kirkpatrick, J., et al. (2017). Overcoming catastrophic forgetting in neural networks.
- Zenke, F., et al. (2017). Continual learning through synaptic intelligence.
- Rusu, A. A., et al. (2016). Progressive neural networks.
- 动态网络扩展 (Dynamic network expansion):
- Zhou, G., et al. (2012). Online incremental feature learning with denoising autoencoders.
- Philipp, G., & Carbonell, J. G. (2017). Nonparametric neural networks.
- Cortes, C., et al. (2016). Adanet: Adaptive structural learning of artificial neural networks.
- Xiao, T., et al. (2014). Error-driven incremental learning in deep convolutional neural network for large-scale image classification.
4 算法
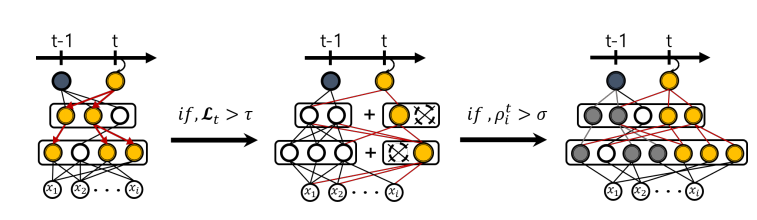
4.1 初始化和选择性重训练
- 目标:在新任务到来时,只重训练与新任务相关的网络部分。通过稀疏化和挑选节点,只保留最重要最简单的网络结构。
- 过程:
- 使用L1正则化初始化网络,促进权重稀疏性,使得每个神经元只与少数下层神经元连接。
- 当新任务到达时,首先在最顶层建立稀疏连接,训练后就可以确定稀疏连接。
- 一旦建立了稀疏连接,使用BFS从输出单元开始,向前传播以识别所有对新任务有影响的单元。BFS会遍历网络,从选定的输出单元开始,逐步向上层扩展,直到第一层。通过BFS,可以构建一个包含所有相关单元和权重的子网络图。这个子网络S包含了对新任务有直接影响的单元。
- 只对选定的子网络S的权重进行重训练。
4.2 动态网络扩展
- 目标:当现有网络不足以学习新任务时,动态地增加网络容量。
- 过程:
- 如果选择性重训练后的损失超过预设阈值,则触发网络扩展。网络扩展决定在网络的哪些层上添加新的神经元,可以是所有层,或者是特定层。
- 在每一层添加固定数量的神经元k,并通过群组稀疏正则化,即对新添加的神经元的权重施加组稀疏正则化。包括对每个新神经元的权重向量执行L1正则化和L2正则化。
- 训练完成后,评估每个新添加的神经元的贡献。如果一个神经元的权重在训练过程中被正则化至接近零(即组稀疏正则化中的L1项导致该组的权重和很小),则认为这个神经元对当前任务贡献不大。删除这些不必要的神经元,以保持网络的效率和防止过拟合。
- 如果删除后网络性能仍然不满足要求,算法可能会返回到步骤2,并在更多的层上或以不同的数量尝试扩展。
4.3 网络分裂/复制
- 目标:防止语义漂移,确保网络对早期任务的表示不会因新任务的学习而退化。
- 过程:
- 测量每个隐藏单元训练前后的语义漂移量,即L2距离。
- 如果漂移量超过阈值σ,则将该单元分裂为两个副本,创建新的单元以保持对早期任务的学习能力,为新任务保留原始特征的同时引入新特征。
- 分裂后,重新训练网络权重以适应新的网络结构。
4.4 时间戳推理
- 目标:在推理时,确保每个任务只使用到其训练阶段为止的网络参数。
- 过程:
- 为新添加的每个单元设置时间戳,记录其被添加到网络的阶段。
- 在推理时,根据时间戳选择参数,确保旧任务不会受到新添加单元的影响。
5 实验分析
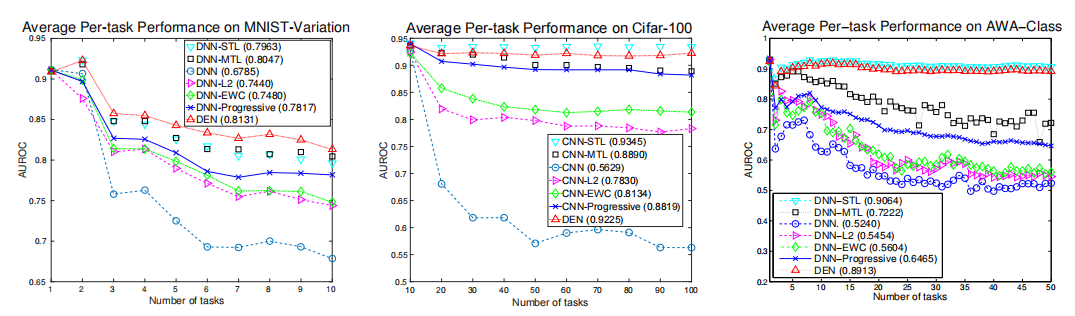
(1)平均任务性能与任务数量的关系
(2)准确率与网络容量的关系
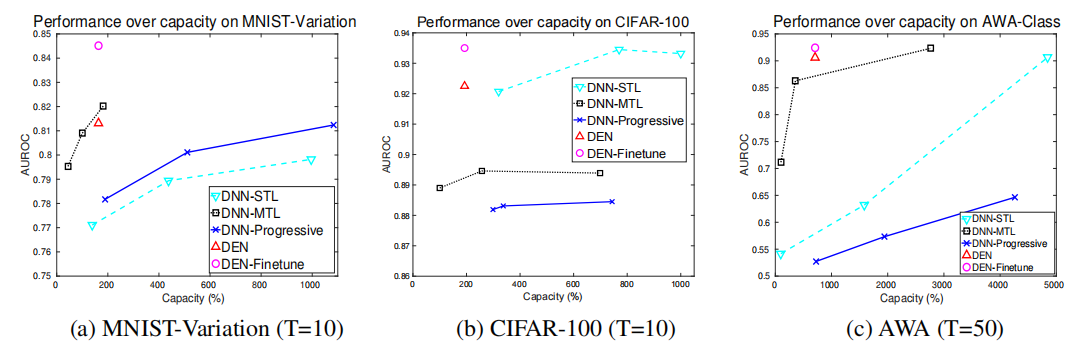
DEN模型在连续学习多个任务的过程中显示出良好的性能稳定性,即使面对不断增加的任务数量,也能保持较高的平均任务性能。
DEN模型能够高效地利用网络容量,在远低于传统多任务学习模型的参数量下实现相似或更好的性能,这表明DEN在网络参数使用上具有显著的优势。
DEN通过动态调整网络容量和选择性重训练,展示了良好的适应性,能够根据新任务的需求灵活调整网络结构。
(3)AUROC随实际训练时间的变化
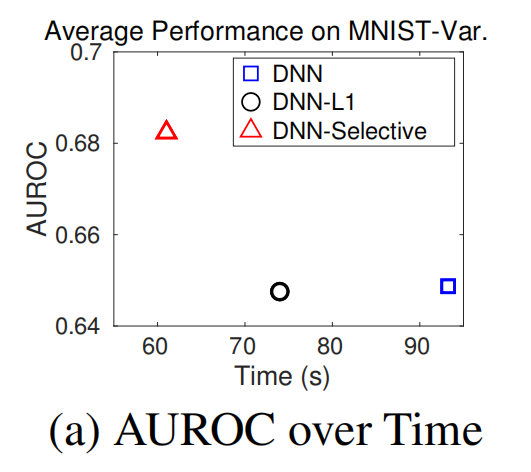
X轴表示实际训练时间,即GPU计算所花费的时间。Y轴表示AUROC(Area Under the Receiver Operating Characteristic curve),用于衡量模型的性能。选择性重训练(DNN-Selective)相比于完整网络重训练(DNN-L2)或稀疏权重网络重训练(DNN-L1)在较短的时间内达到了更高的AUROC,表明选择性重训练在效率上有显著提升。
(4)选择性重训练选择的神经元数量
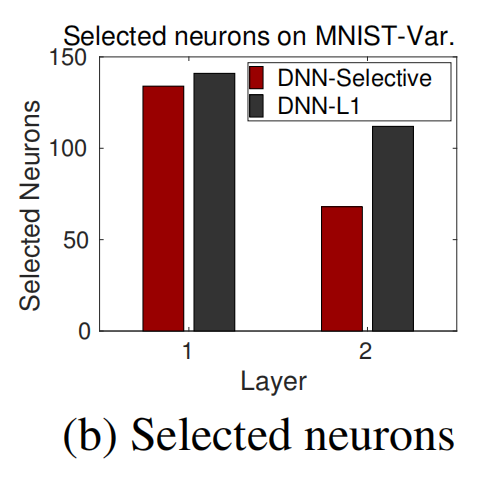
选择性重训练倾向于选择较少的神经元进行更新,这意味着只有与新任务高度相关的部分网络被激活和训练,从而减少了计算量。
(5)扩展性能

- DEN模型在扩展网络时能够保持较高的AUROC,同时只有适度的网络容量增加。
- DNN-Dynamic(动态扩展的网络)相比于固定数量扩展(DNN-Constant)在网络容量上更小,但性能上更好,这表明DEN的动态扩展策略在保持性能的同时有效控制了网络大小。
(6)语义漂移实验
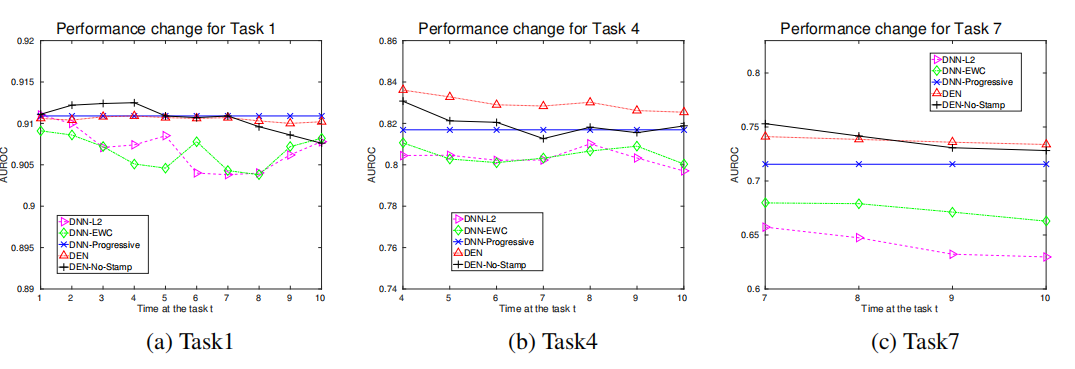
DEN-No-Stamp模型是DEN模型的一个变体,没有使用时间戳推理机制。尽管在后期任务上表现良好,但随着时间推移,对早期任务的性能有所下降。DEN模型通过选择性重训练、动态网络扩展和网络分裂/复制等机制,有效防止了语义漂移。在所有训练阶段,DEN显示出对早期任务的稳定性能,并且在后期任务上也有良好表现。DEN算法在处理连续学习任务时,如何有效地平衡新旧任务的学习,防止因学习新任务而导致对旧任务性能的负面影响,即灾难性遗忘。
(7)Permuted MNIST数据集上进行的连续学习实验
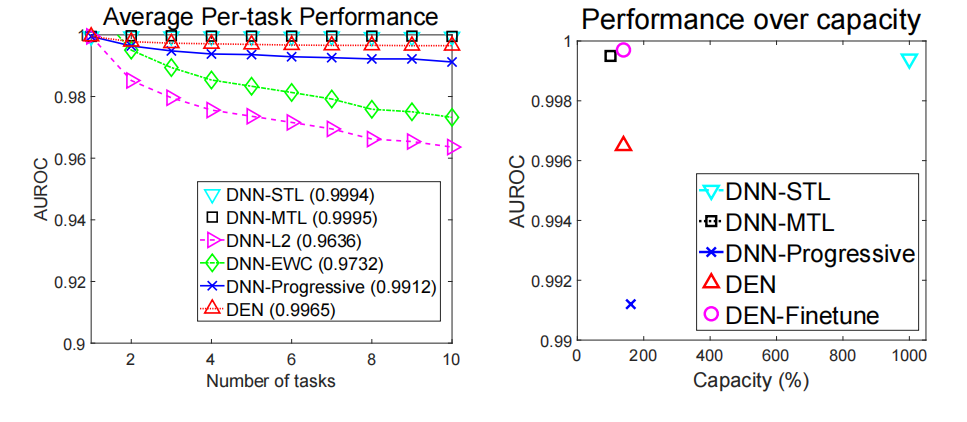
Permuted MNIST数据集的实验结果进一步证实了DEN在控制语义漂移方面的有效性,即使在面对连续变化的任务时,DEN也能够保持对早期任务的高性能。如果对DEN模型在所有任务上进行微调(DEN-Finetune),它能够进一步改善性能,甚至超过了单独针对每个任务训练的模型(DNN-STL)和MTL模型,这表明DEN在结构估计方面的优势。
6 思考
(1)DEN相比较于DNN-Progressive(传统的PNN)做了哪些改进?
- 动态容量调整:DNN-Progressive通过为每个新任务添加固定容量的子网络来扩展模型,而DEN能够根据新任务的需求动态地调整网络容量。这意味着DEN可以更精确地为每个任务分配所需的资源,而不是预先设定一个固定的扩展量。
- 选择性重训练:DEN执行选择性重训练,只更新与新任务相关的网络部分,而DNN-Progressive通常不对旧网络进行更新,只是简单地添加新的部分。这使得DEN在保持旧任务性能的同时,更有效地适应新任务。
- 防止语义漂移:为了解决语义漂移或灾难性遗忘的问题,DEN采用了单元分裂/复制机制和时间戳推理,而DNN-Progressive通常依赖于网络的固定部分来保持旧任务的知识。DEN的这种方法可以更有效地保持对早期任务的记忆。
(2)DEN相比较于DNN-Progressive(传统的PNN)有哪些优点?
- 计算效率高:由于DEN只重训练与新任务相关的网络部分,因此它在计算上更为高效,减少了不必要的计算开销。相比之下,DNN-Progressive可能需要更多的计算资源来处理不断增长的网络。
- 优化了网络结构:DEN通过群组稀疏正则化来优化网络结构,自动删除不必要的单元,而DNN-Progressive通常不会对已添加的网络部分进行优化。
- 灵活性和适应性:DEN的设计允许它在面对不同难度和复杂性的任务时,具有更好的适应性和灵活性。DNN-Progressive虽然通过分阶段扩展网络来适应多任务,但可能不如DEN那样灵活地处理任务间的差异。
- 性能得到了提升:在多个数据集上的实验结果表明,DEN在终身学习场景中通常能够显著优于DNN-Progressive,尤其是在参数数量较少的情况下,这表明DEN在网络结构和参数使用上更为高效。
- 结构估计:DEN不仅可以用于终身学习,还可以用于在所有任务都已知的情况下进行网络结构估计,以获得最优的性能,这是DNN-Progressive不具备的能力。



















 850
850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











