









 本文介绍了华为诺亚方舟实验室的SP-NAS研究,该研究直接在目标检测数据集上搜索最优的检测backbone,避免了传统方法依赖预训练的限制。SP-NAS采用了串行-并行搜索策略,首先在每个stage找到最优的串行block,然后组合成并行结构以融合不同层次的特征。这一方法允许backbone大小的动态增长,提供更大的搜索空间。实验表明,这种方法能在保持效率的同时提高检测性能。
本文介绍了华为诺亚方舟实验室的SP-NAS研究,该研究直接在目标检测数据集上搜索最优的检测backbone,避免了传统方法依赖预训练的限制。SP-NAS采用了串行-并行搜索策略,首先在每个stage找到最优的串行block,然后组合成并行结构以融合不同层次的特征。这一方法允许backbone大小的动态增长,提供更大的搜索空间。实验表明,这种方法能在保持效率的同时提高检测性能。
目录
前言
最近学NAS+目标检测相关的内容,找到这篇华为诺亚方舟实验室的SP-NAS。
收录于2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
一、Introduction
之前就有提出,传统的检测任务backbone就是直接移植在分类任务上表现优秀的backbone,如resnet。但这必然不是最优的,就给网络搜索留下了可行空间。
大多数NAS工作不直接搜索检测的backbone,因为一旦backbone结构变化就需要重新在imagenet预训练。(训练supernet的方式应该对此有帮助,比如DetNAS)
之前看过NAS-FPN和DetNAS,本文创新点在:
1)直接在detection dataset上搜索backbone(还是得imagenet pretrain的)
2 ) backbone大小可增长,搜索空间更大更灵活
3 ) 不像DetNAS这种指定4个block并搜索block内部模式,而是搜索整个backbone架构
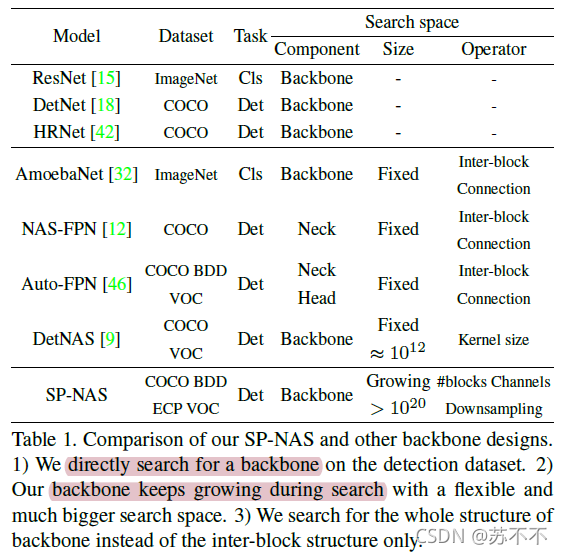
【作者提出的serial-to-parallel搜索策略】
1)串行搜索阶段:在每个stage找到分辨率、接受域和输出通道最优的串行block
2 ) 并行搜索阶段:几个搜索的串行block组装成一个更强大的并行结构主干,更好地融合高级和低级特征
二、Method
1. Serial-level Search
- 之前手工设计的检测网络如DetNet,FishNet主要在于利用高分辨率的空间信息、融合不同尺度的feature。本文的搜索空间也基于这些概念设计。
- 输入图像会先经过两个3*3,s=2的卷积,分辨率降到1/4。
- 之后接如图backbone,包含若干个stage,stage中有若干block,其中每个block的输入输出维度是相同的。搜索空间的候选block见table. 2。block数量8~60,stage数量5~7,以步长2降采样。同时也搜索何时double channel size(并不是每次降采样都double了)。

- 网络结构的编码表达 BNB(11,1d1,111,1d11,11d1)。其中d表示channel double。
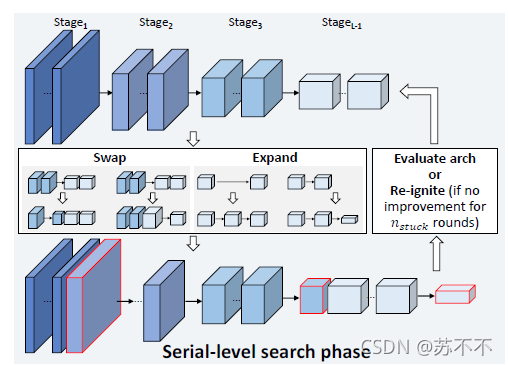
## 然后来看一下作者一直提到但是又看不太懂的Swap-Expand-Reignite搜索策略 =w=
- 主旨是为了充分利用imagenet预训练好的参数,毕竟大部分paper都表示直接在detection数据集上训练要么准确率低,要么极其耗时。
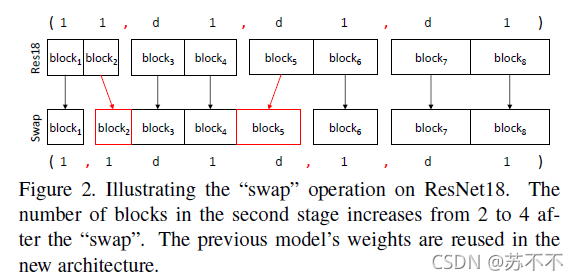
- swap:交换相邻block的步长,权重不变。(大概就是把一个block从一个stage并到另一个相邻stage,看图比较好懂)
- expand:任意两个block中加入一个新block,通道维度不变,权重初始化为单位矩阵
- reginite:经过一定的swap-expand得到的新网络会被小训练一下(比如 3 epochs),并在一堆新网络里选择性能最好的。但是当新结构偏离原结构太多,会进化不出更好的网络,此时要在imagenet上重新pre-train当前的最优结构,实现网络的“重启”。作者表示这种“重启” 1~2次即可。
2. Parallel-level Search
先上图
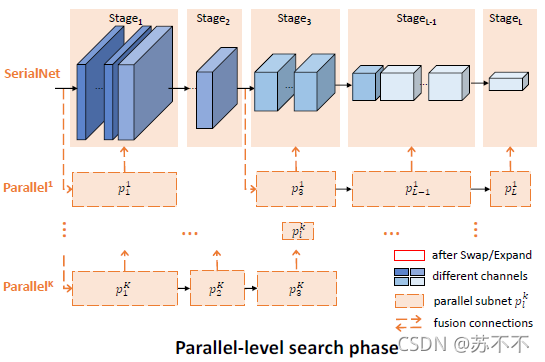
有点难懂,这边笔者只能简单理解一下。
- 为了横向扩展网络,增加了K个parallel层,原始的serialNet(上面搜出来的那个)某一stage的output循环迭代地输入pi(1)-pi(k) 。类似于一个自底向上的尺度融合。
- 重点:每层parallel对应的block都是serialNet复制过去的,包括参数。
- 具体搜索空间直接搬运文中的例子。假设SerialNet有4个stage,“(0,2,1,3)”表示每个stage的paralle subnet数量K,例如“0”表示在这个阶段没有额外的paralle subnet。“3”意味着我们复制最后一个stage3次。
- 这个阶段搜索空间比较小,(K+1)^L,文中K=3,L=4~6。采用的随机搜索,但是并不均等采样,增加subnet的概率与FLOPS反相关。
三、 实验细节
- serial阶段的小训练+推理要96个GPU day in coco,16个GPU day in VOC(如果我没算错的话)。整体给出在VOC上的search time 26GPU day。
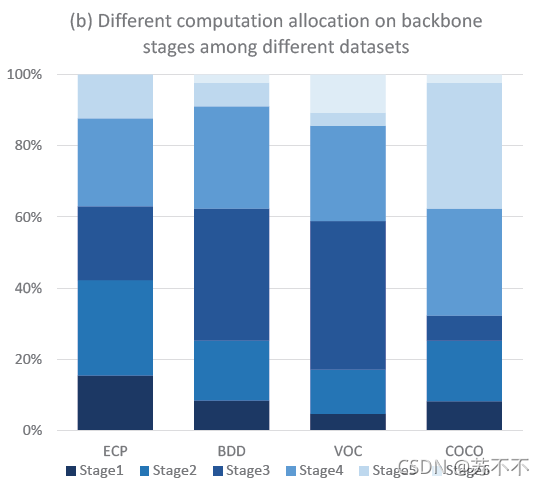
- 作者给了在不同数据集上得到的网络,每个stage的计算资源分布。不同数据集的差别还是挺大的,看起来检测任务并没有特别倾向于哪个层次的特征(也或许和不同数据集的目标物体不同有关?),总之也比较有意思。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









