









环境介绍
| 组件 | 版本 |
|---|---|
| Ambari | 2.6.0 |
| HDP | 2.6.3 |
| Hadoop | 2.7.3 |
| Scala | 2.11 |
| Spark2(升级之前) | 2.2.0 |
| Spark2(升级之后) | 2.4.8 |
升级原因:
Apache Spark部分版本中存在远程代码执行漏洞.
黑客可以利用该漏洞发送恶意指令,获取目标服务器权限,实现远程代码执行,给服务器安全带来极大威胁。
该漏洞在2.4.6及之后的版本得到修复.
漏洞详情可参考官方文档:
Reporting security issues
为了修复该漏洞,计划将spark2版本升级到官方最新稳定版2.4.8
零. 方案选择
方案一:
在集群搭建一套spark2.4.8环境,配置环境变量,后续使用新的环境提交spark任务
优点: 操作简单
缺点: Spark不再受Ambari管控,后续维护困难
方案二
升级现有的spark2.2.0环境到2.4.8
缺点:操作相对复杂,容易出现和现有环境不兼容的场景
优点: 受ambari管理,后续维护方便
考虑日后的运维成本,决定采用方案二来解决spark版本系统漏洞问题
一. 2.4.8版本安装
gz包选择: 适配hadoop2.7的spark-2.4.8-bin-hadoop2.7.tgz
安装包下载: 清华大学开源镜像站
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-2.4.8/spark-2.4.8-bin-hadoop2.7.tgz
tar -zxvf spark-2.4.8-bin-hadoop2.7.tgz
对比开源spark2.4.8和hdp自带的spark2目录
发现: spark2.4.8多了kubernetes目录,其余的目录结构是相同的
因此,决定采用替换除conf外,全部目录和文件的方式
# 将每个子目录打成gz包,供下一步使用
cd spark-2.4.8-bin-hadoop2.7
tar -czvf bin.tar.gz bin/
tar -czvf data.tar.gz data/
tar -czvf examples.tar.gz examples/
tar -czvf jars.tar.gz jars/
tar -czvf kubernetes.tar.gz kubernetes/
tar -czvf licenses.tar.gz licenses/
tar -czvf python.tar.gz python/
tar -czvf R.tar.gz R/
tar -czvf sbin.tar.gz sbin/
tar -czvf yarn.tar.gz yarn/
二. spark2版本升级
2.0 升级前提
升级通过脚本来完成.
成功执行脚本需要:
- 将spark2.4.8高版本相关包和jackson高版本jar包放置文件服务器下:
文件服务器可采用以下方式搭建:
yum install -y httpd >/dev/null 2>&1
service httpd restart >/dev/null 2>&1
chkconfig httpd on
按照该方式搭建结束后,
需要将spark-2.4.8-bin-hadoop2.7目录整体拷贝到/var/www/html目录下
此时,可通过http://ip地址/spark-2.4.8-bin-hadoop2.7/的方式访问spark,如下:

- 将jackson高版本jar包放置/var/www/html目录下
# 需要以下高版本jar包
jackson-databind-2.11.4.jar
jackson-core-2.11.4.jar
jackson-annotations-2.11.4.jar
ackson-module-jaxb-annotations-2.11.4.jar
jackson-module-paranamer-2.11.4.jar
jackson-module-scala_2.11-2.11.4.jar
jar包已经上传至百度网盘
jacckson jar包百度网盘链接
提取码: qhd5
2.1 版本升级相关脚本
版本升级脚本
升级操作通过以下三个脚本来完成
spark2_upgrade.sh #旧版本备份升级,以及jackson相关jar包升级到高版本,因为spark2.4.8版本自带的jaskson版本较低,同样有漏洞,因此需要将jackson版本升级
spark2_rollback.sh #版本回滚
spark2_upgrade.sh
#!/bin/bash
download_path=$1
spark_path=/usr/hdp/2.6.3.0-235/spark2
check_wget(){
wget --help >/dev/null 2>&1
if [ $? != 0 ]; then
sudo yum install -y wget >/dev/null 2>&1
check_wget
fi
}
backup() {
mkdir -p $spark_path/bak
mv $spark_path/bin $spark_path/bak/
mv $spark_path/licenses $spark_path/bak/
mv $spark_path/NOTICE $spark_path/bak/
mv $spark_path/README.md $spark_path/bak/
mv $spark_path/data $spark_path/bak/
mv $spark_path/examples $spark_path/bak/
mv $spark_path/jars $spark_path/bak/
mv $spark_path/kubernetes $spark_path/bak/
mv $spark_path/LICENSE $spark_path/bak/
mv $spark_path/python $spark_path/bak/
mv $spark_path/R $spark_path/bak/
mv $spark_path/sbin $spark_path/bak/
mv $spark_path/yarn $spark_path/bak/
mv $spark_path/RELEASE $spark_path/bak/
}
download_gz() {
download_spark_path=$download_path/spark-2.4.8-bin-hadoop2.7
wget -P $spark_path/ $download_spark_path/data.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/examples.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/jars.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/kubernetes.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/NOTICE >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/python.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/README.md >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/R.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/sbin.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/yarn.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/bin.tar.gz >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/LICENSE >/dev/null 2>&1
wget -P $spark_path/ $download_spark_path/RELEASE >/dev/null 2>&1
tar -zxvf $spark_path/data.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/examples.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/jars.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/kubernetes.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/python.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/R.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/sbin.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/yarn.tar.gz -C $spark_path/ >/dev/null 2>&1
tar -zxvf $spark_path/bin.tar.gz -C $spark_path/ >/dev/null 2>&1
chown -R root:root $spark_path
rm -rf $spark_path/*.tar.gz >/dev/null 2>&1
}
upgrade_jackson() {
hdp_path=/usr/hdp/2.6.3.0-235
databind_jar=jackson-databind-2.11.4.jar
core_jar=jackson-core-2.11.4.jar
annotations_jar=jackson-annotations-2.11.4.jar
jaxb_jar=jackson-module-jaxb-annotations-2.11.4.jar
paranamer_jar=jackson-module-paranamer-2.11.4.jar
scala_jar=jackson-module-scala_2.11-2.11.4.jar
wget -P /tmp/ $download_path/$databind_jar
wget -P /tmp/ $download_path/$core_jar
wget -P /tmp/ $download_path/$annotations_jar
wget -P /tmp/ $download_path/$jaxb_jar
wget -P /tmp/ $download_path/$paranamer_jar
wget -P /tmp/ $download_path/$scala_jar
mv $hdp_path/spark2/jars/jackson-databind-2.6.7.3.jar $hdp_path/spark2/jars/jackson-databind-2.6.7.3.jar_bak
mv $hdp_path/spark2/jars/jackson-annotations-2.6.7.jar $hdp_path/spark2/jars/jackson-annotations-2.6.7.jar_bak
mv $hdp_path/spark2/jars/jackson-core-2.6.7.jar $hdp_path/spark2/jars/jackson-core-2.6.7.jar_bak
mv $hdp_path/spark2/jars/jackson-module-scala_2.11-2.6.7.1.jar $hdp_path/spark2/jars/jackson-module-scala_2.11-2.6.7.1.jar_bak
mv $hdp_path/spark2/jars/jackson-module-paranamer-2.7.9.jar $hdp_path/spark2/jars/jackson-module-paranamer-2.7.9.jar_bak
mv $hdp_path/spark2/jars/jackson-module-jaxb-annotations-2.6.7.jar $hdp_path/spark2/jars/jackson-module-jaxb-annotations-2.6.7.jar_bak
cp /tmp/$databind_jar $hdp_path/spark2/jars/$databind_jarx
cp /tmp/$core_jar $hdp_path/spark2/jars/$core_jar
cp /tmp/$annotations_jar $hdp_path/spark2/jars/$annotations_jar
cp /tmp/$jaxb_jar $hdp_path/spark2/jars/$jaxb_jar
cp /tmp/$paranamer_jar $hdp_path/spark2/jars/$paranamer_jar
cp /tmp/$scala_jar $hdp_path/spark2/jars/$scala_jar
}
replace_jersey() {
yarn_path=/usr/hdp/2.6.3.0-235/hadoop-yarn/lib
mv $spark_path/jars/jersey-client-2.22.2.jar $spark_path/jars/jersey-client-2.22.2.jar_bak
cp $yarn_path/jersey-core-1.9.jar $spark_path/jars/
cp $yarn_path/jersey-client-1.9.jar $spark_path/jars/
}
sed_version() {
hdp_version="\${hdp.version}"
sed -i "s/$hdp_version/2.6.3.0-235/g" /etc/hadoop/2.6.3.0-235/0/mapred-site.xml
}
main() {
check_wget
backup
download_gz
upgrade_jackson
replace_jersey
sed_version
}
main $@
spark2_rollback.sh
#!/bin/bash
spark_path=/usr/hdp/2.6.3.0-235/spark2
rollback() {
rm -rf $spark_path/rollback
mkdir -p $spark_path/rollback
mv $spark_path/bin $spark_path/rollback/
mv $spark_path/licenses $spark_path/rollback/
mv $spark_path/RELEASE $spark_path/rollback/
mv $spark_path/NOTICE $spark_path/rollback/
mv $spark_path/README.md $spark_path/rollback/
mv $spark_path/data $spark_path/rollback/
mv $spark_path/examples $spark_path/rollback/
mv $spark_path/jars $spark_path/rollback/
mv $spark_path/kubernetes $spark_path/rollback/
mv $spark_path/LICENSE $spark_path/rollback/
mv $spark_path/python $spark_path/rollback/
mv $spark_path/R $spark_path/rollback/
mv $spark_path/sbin $spark_path/rollback/
mv $spark_path/yarn $spark_path/rollback/
mv $spark_path/bak/bin $spark_path/
mv $spark_path/bak/licenses $spark_path/
mv $spark_path/bak/NOTICE $spark_path/
mv $spark_path/bak/README.md $spark_path/
mv $spark_path/bak/examples $spark_path/
mv $spark_path/bak/jars $spark_path/
mv $spark_path/bak/kubernetes $spark_path/
mv $spark_path/bak/LICENSE $spark_path/
mv $spark_path/bak/python $spark_path/
mv $spark_path/bak/R $spark_path/
mv $spark_path/bak/sbin $spark_path/
mv $spark_path/bak/yarn $spark_path/
mv $spark_path/bak/data $spark_path/
mv $spark_path/bak/RELEASE $spark_path/
}
main() {
rollback
}
main $@
版本升级
# download_path为文件服务器地址, http://ip地址
# sh -x spark2_upgrade.sh $download_path
版本回滚
sh -x spark2_rollback.sh
三. spark2升级后遇到的问题及解决方案
问题一: NoClassDefFoundError: com/sun/jersey/api/client/config/ClientConfig
# 提交spark on yarn示例任务
cd /usr/hdp/2.6.3.0-235/spark2
./bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster --driver-memory 4g --executor-memory 2g --executor-cores 1 --queue default examples/jars/spark-examples*.jar 10
报错如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ItZgYaEL-1638413606486)(/tfl/pictures/202111/tapd_51752851_1638261905_60.png)]](https://img-blog.csdnimg.cn/3b4f89a683d64a8298fbf29a061659c9.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbmV35Liq5a-56LGh5YWI,size_20,color_FFFFFF,t_70,g_se,x_16)
报错原因:
集群hadoop-yarn的jersey依赖包版本低于spark的对应的包版本,导致jar包冲突
解决方案:
将spark的高版本jar包jersey-client-2.22.2.jar备份
将yarn的低版本jar包/usr/hdp/2.6.3.0-235/hadoop-yarn/lib/jersey-core-1.9.jar, jersey-client-1.9.jar拷贝到jar包目录下.
并将该部分操作添加到升级脚本中
问题二: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found
21/12/01 11:10:23 INFO AbstractService: Service org.apache.hadoop.yarn.client.api.impl.YarnClientImpl failed in state STARTED; cause: java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2227)
at org.apache.hadoop.yarn.client.RMProxy.createRMFailoverProxyProvider(RMProxy.java:161)
at org.apache.hadoop.yarn.client.RMProxy.createRMProxy(RMProxy.java:94)
at org.apache.hadoop.yarn.client.ClientRMProxy.createRMProxy(ClientRMProxy.java:72)
at org.apache.hadoop.yarn.client.api.impl.YarnClientImpl.serviceStart(YarnClientImpl.java:187)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.spark.deploy.yarn.Client.submitApplication(Client.scala:162)
at org.apache.spark.deploy.yarn.Client.run(Client.scala:1135)
at org.apache.spark.deploy.yarn.YarnClusterApplication.start(Client.scala:1530)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:855)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:930)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:939)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: java.lang.RuntimeException: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2195)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2219)
... 15 more
Caused by: java.lang.ClassNotFoundException: Class org.apache.hadoop.yarn.client.RequestHedgingRMFailoverProxyProvider not found
at org.apache.hadoop.conf.Configuration.getClassByName(Configuration.java:2101)
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2193)
... 16 more
解决方案:
将yarn-site.xml中yarn.client.failover-proxy-provider的值修改为:org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider
如下图所示:

问题三: bad substitution
解决问题二之后,重新提交spark on yarn 任务
登录spark jobhistory,查看该任务日志,发现如下报错:
/usr/hdp/${hdp.version}/hadoop/lib/hadoop-lzo-0.6.0.${hdp.version}.jar:/etc/hadoop/conf/secure:/usr/hdp/current/ext/hadoop/*:$PWD/__spark_conf__/__hadoop_conf__: bad substitution
从日志可以看到,hdp.version并未按照预期获取到
因此,需要把hdp.version的值替换成如下

hdp_version=\${hdp.version}
sed -i 's/$hdp_version/2.6.3.0-235/g' /etc/hadoop/2.6.3.0-235/0/mapred-site.xml
将该部分操作添加到升级脚本中
解决完该问题之后,重新提交spark on yarn任务,这次执行正常

访问spark history 界面,发现已经更新为新版本
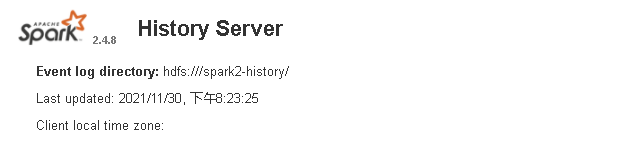
问题四: thrift server启动后马上挂掉
查看thrift server对应日志,发现如下报错:
Exception in thread "main" java.lang.ExceptionInInitializerError
at org.apache.spark.scheduler.EventLoggingListener$.initEventLog(EventLoggingListener.scala:307)
at org.apache.spark.scheduler.EventLoggingListener.start(EventLoggingListener.scala:126)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:523)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2526)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:930)
at org.apache.spark.sql.SparkSession$Builder$$anonfun$7.apply(SparkSession.scala:921)
at scala.Option.getOrElse(Option.scala:121)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:921)
at org.apache.spark.sql.hive.thriftserver.SparkSQLEnv$.init(SparkSQLEnv.scala:48)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2$.main(HiveThriftServer2.scala:79)
at org.apache.spark.sql.hive.thriftserver.HiveThriftServer2.main(HiveThriftServer2.scala)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.spark.deploy.JavaMainApplication.start(SparkApplication.scala:52)
at org.apache.spark.deploy.SparkSubmit.org$apache$spark$deploy$SparkSubmit$$runMain(SparkSubmit.scala:855)
at org.apache.spark.deploy.SparkSubmit.doRunMain$1(SparkSubmit.scala:161)
at org.apache.spark.deploy.SparkSubmit.submit(SparkSubmit.scala:184)
at org.apache.spark.deploy.SparkSubmit.doSubmit(SparkSubmit.scala:86)
at org.apache.spark.deploy.SparkSubmit$$anon$2.doSubmit(SparkSubmit.scala:930)
at org.apache.spark.deploy.SparkSubmit$.main(SparkSubmit.scala:939)
at org.apache.spark.deploy.SparkSubmit.main(SparkSubmit.scala)
Caused by: com.fasterxml.jackson.databind.JsonMappingException: Incompatible Jackson version: 2.11.4
at com.fasterxml.jackson.module.scala.JacksonModule$class.setupModule(JacksonModule.scala:64)
at com.fasterxml.jackson.module.scala.DefaultScalaModule.setupModule(DefaultScalaModule.scala:19)
at com.fasterxml.jackson.databind.ObjectMapper.registerModule(ObjectMapper.java:819)
at org.apache.spark.util.JsonProtocol$.<init>(JsonProtocol.scala:59)
at org.apache.spark.util.JsonProtocol$.<clinit>(JsonProtocol.scala)
... 23 more
报错原因: jackson相关jar包升级不够充分导致jar包冲突
解决方案: jackson相关jar包全部升级,并将升级部分操作集成到脚本
除了替换的常规的三个jar包
jackson-databind-*.jar
jackson-core-*.jar
jackson-annotations-*.jar
还应该替换如下jar包
jackson-module-scala_2.11-*.jar
jackson-module-paranamer-*.jar
jackson-module-jaxb-annotations-*.jar
jar包替换完成后,使用beeline命令
beeline -u jdbc:hive2://${thrift_server_host}:10016 -n hive
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZB5Lg4D7-1638413606496)(/tfl/pictures/202112/tapd_51752851_1638343773_59.png)]](https://img-blog.csdnimg.cn/43ed00dab94e40e88e740b69972b0bf7.png)
四. 通过ambari进行管理
之前介绍过,这种方案最大的好处,是兼容ambari管理,如下图:

通过Amabri Quick Links链接跳转显示正常!

通过可视化界面启停正常,兼容性OK!














 2001
2001











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









