









1. hive创建外部表
创建外部表的好处:
hive创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变.
删除表的时候,外部表只删除元数据,不删除数据
所以总结起来就是 : 外部表相对安全,数据组织更加灵活,方便共享源数据
建表语法
CREATE EXTERNAL TABLE IF NOT EXISTS 表名
(
列名1 数据类型,
.
.
.
.
列名n 数据类型
)
PARTITIONED BY (分区依据 数据类型)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t' -- 指定数据之间的分隔符
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n' -- 指定换行符
LOCATION 'hdfs数据目录'; -- 加载的hdfs数据目录
举例 :
CREATE EXTERNAL TABLE IF NOT EXISTS outhighsampleTest1115xmr
(
Column_1 SMALLINT,
.
.
.
.
-- 列数太多,中间的列省略掉
Column_111 STRING
)
PARTITIONED BY (hour_p int)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY '\002'
MAP KEYS TERMINATED BY '\003'
LINES TERMINATED BY '\n'
LOCATION '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/';
2. 为外部表添加分区
为什么需要分区?
举例 : 一个表里存储了一天的数据,但是很多时候,我们只想查询其中的一个小时
而为了这一个小时的数据取扫描全表,是相当耗时的操作
因此,我们建表的时候指定partition
就可以在后续的应用的过程中为表格添加合适的分区
分区语法
alter table 表名 add partition (分区依据='分区名') location 'hdfs路径';
-- 注意 : 这里的分区依据要和建表时指定的分区依据保持一致
举例 :
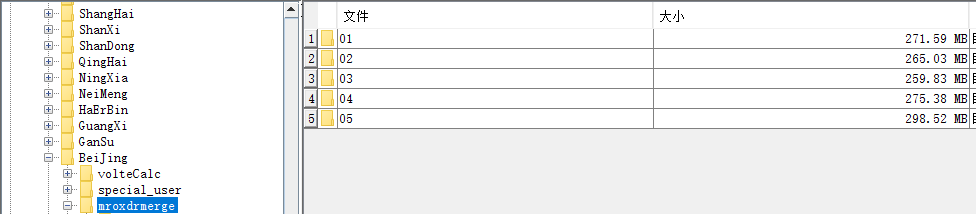
在我之前建表引入的hdfs目录下,有5个子目录,我就以这5个子目录来创建分区
语句如下:
alter table outhighsampleTest1115xmr add partition (hour_p='01') location '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/01';
alter table outhighsampleTest1115xmr add partition (hour_p='02') location '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/02';
alter table outhighsampleTest1115xmr add partition (hour_p='03') location '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/03';
alter table outhighsampleTest1115xmr add partition (hour_p='04') location '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/04';
alter table outhighsampleTest1115xmr add partition (hour_p='05') location '/mt_wlyh/Data/BeiJing/mroxdrmerge/mro_loc/data_01_180125_bak/tb_mr_outsample_high_dd_180125/05';
3. 通过分区进行查询
首先查询分区表的分区状态
语法 : show partitions 表名;
举例 : show partitions outhighsampleTest1115xmr;
查询
分区表进行查询和普通的hql 没什么区别的!
如下图所示 :
支持通过分区进行的
=, != , > < , in, 以及组合查询!!
能有效的提高查询效率
4.几个坑
1.建表时报错
2. 为表格添加分区失败
报错信息 : Error while compiling statement: FAILED: ValidationFailureSemanticException
table is not partitioned but partition spec exists: {hour_p=05}

报错信息含义 : 创建分区失败,表格并不是一个分区表
解决方法 : 在建表时指定表格为分区表
指定方式建表语句加上 PARTITIONED BY (分区依据 数据类型)
即可为该表创建分区!
5. 软件安利
Aginity Workbench for Hadoop
用该软件来操作hdfs和hive简直不要太方便!
举例 : 我想建立一个hdfs上文件到hive的外部表映射,但是这个hdfs文件里面有很多列,敲起来累死人, 而且语法也记不住怎么办?
没关系,该软件帮你轻松解决!!
点击Tools–>FileShells–>Hdfs File Explorer
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PInMl79y-1601032761144)(https://i.loli.net/2018/11/15/5bed66e284bbe.png)]
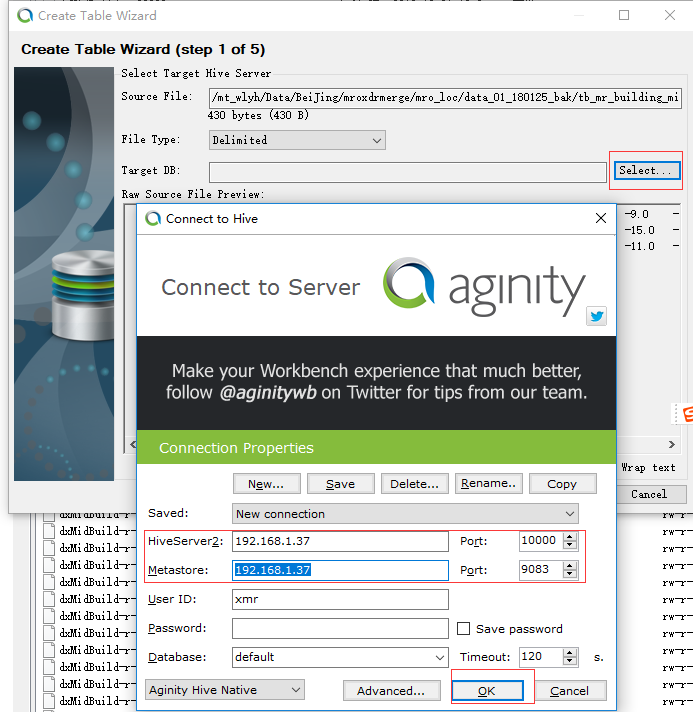
设置好hdfs连接,选择好文件点击Create Hive Table
点击select-->设置好hive连接和端口号--> OK
接下来,点击next进行设置, 在修改下表名什么的,就OK啦
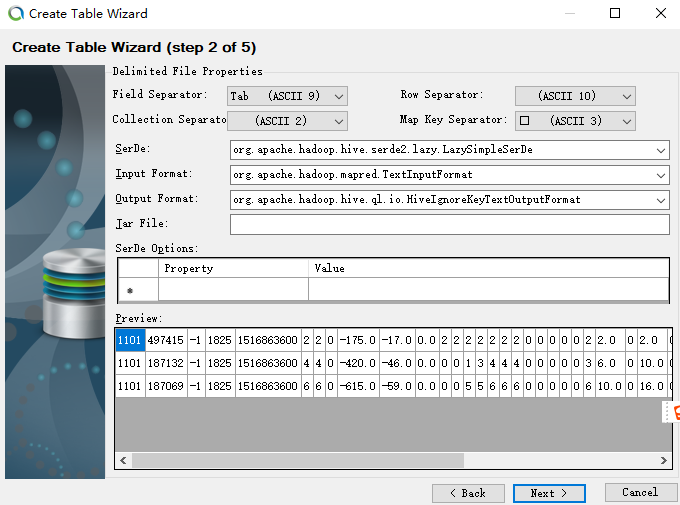
.... 最后,这个语句会出现在窗口里,点击下execute执行就创建成功了!!! 操作熟练后只是点几下鼠标,我们想要的表就出来了
当然,这只是这款软件的一个小功能而已,还有更多很好的,实用的功能,用过的都说好~~~















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-AQAJxEFC-1601032761137)(https://i.loli.net/2018/11/15/5bed6212a1148.png)]](https://i.loli.net/2018/11/15/5bed6212a1148.png){kind=link}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dgWhyQgw-1601032761141)(https://i.loli.net/2018/11/15/5bed62e43130a.png)]](https://i.loli.net/2018/11/15/5bed62e43130a.png){kind=link}
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kyzUr3H0-1601032761148)(https://i.loli.net/2018/11/15/5bed67c58d921.png)]](https://i.loli.net/2018/11/15/5bed67c58d921.png){kind=link}