









在上一篇博客中,我总结了使用Airflow过程中踩过的坑.和一些解决方案,
链接如下:
Airflow2.1.1实战中踩过的坑总结!!
篇幅所限,把该博客的第11个问题单独整理出来
11. 分布式部署场景下,dag执行失败,日志无法正常查看的问题
文章目录
一. 问题详细表现
1.1 Airflow必要环境信息
Airflow版本:2.1.1
部署方式: 分布式(worker部署在多台虚拟机下)
python版本:3.7.5
executor :celery
dag执行状态: failed
1.2 报错表现
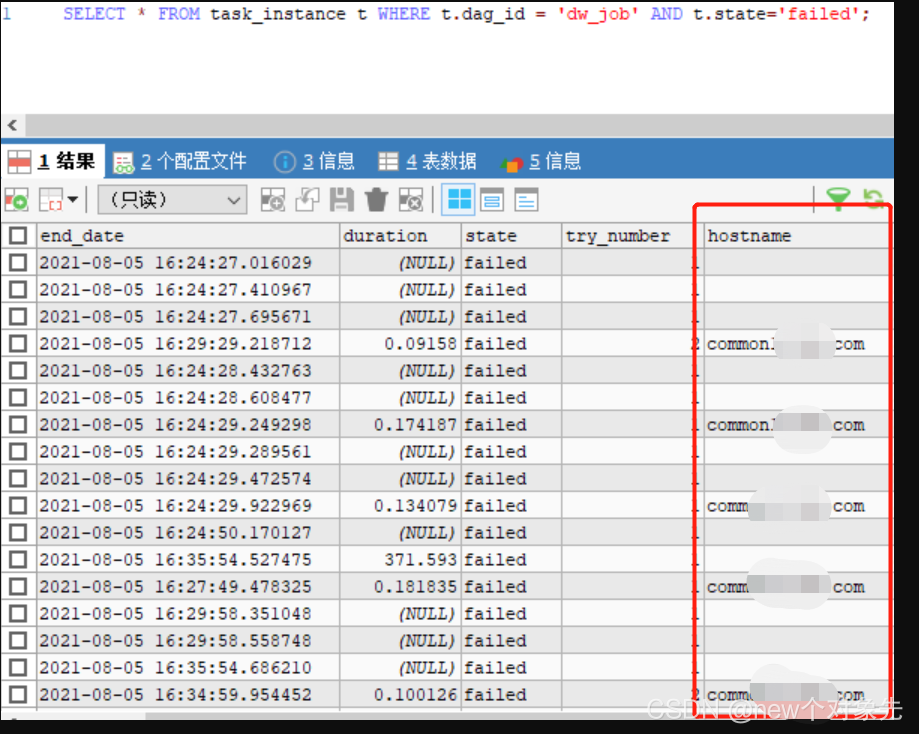
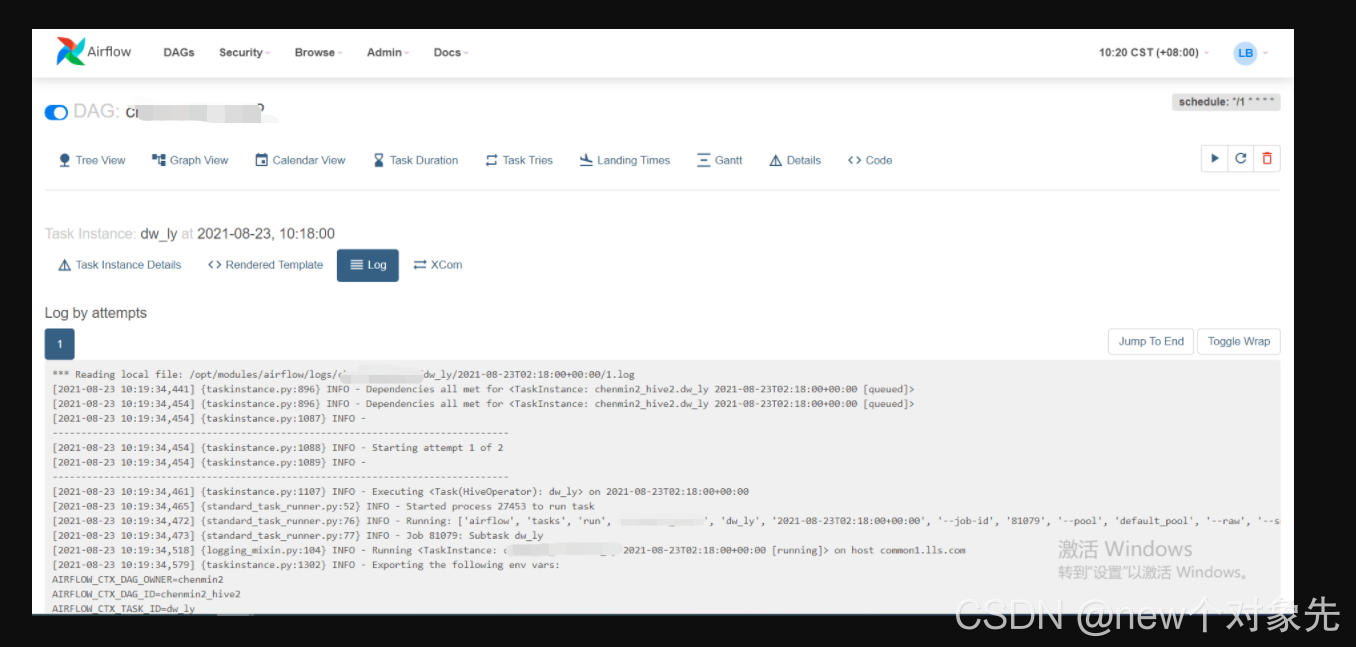
当dag执行失败时,部分失败dag日志报错如下
以下图dag举例,可以看到:,执行状态为failed
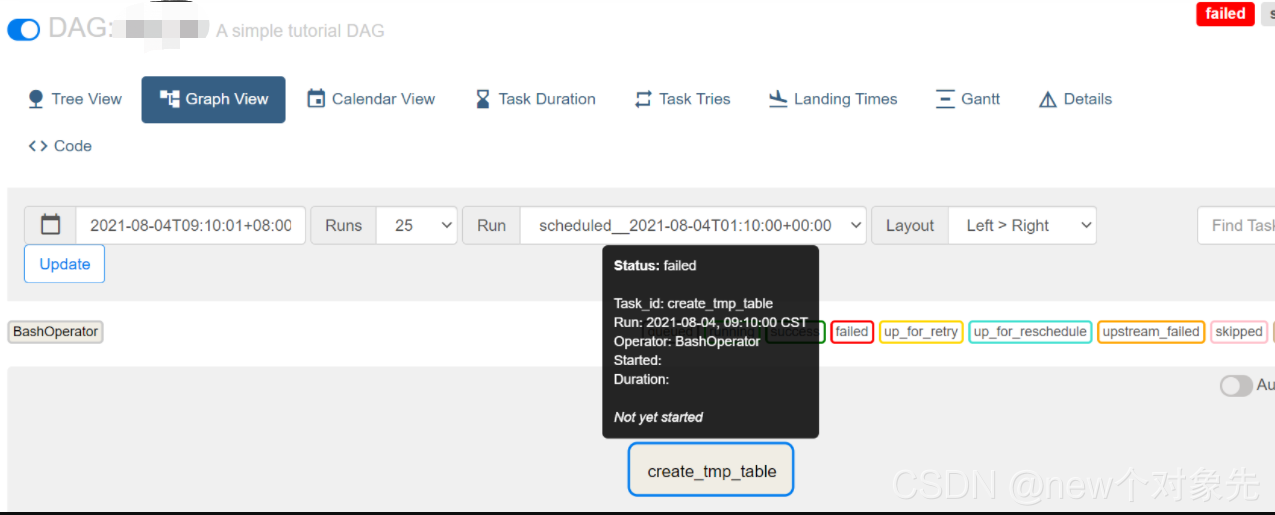
通过webui查看报错信息如下:
*** Log file does not exist: /opt/modules/airflow/logs/***/***/2021-08-04T01:10:00+00:00/1.log
*** Fetching from: http://:8793/log/dw_job/create_tmp_table/2021-08-04T01:10:00+00:00/1.log
*** Failed to fetch log file from worker. The request to ':///' is missing either an 'http://' or 'https://' protocol.
二. 问题排查与处理
2.1 初步分析源码,大致定位问题
出现问题之后,就是漫长的问题排查与处理过程:
首先根据报错关键信息Failed to fetch log file from worker,定位到源码airflow/utils/log/file_task_handler.py 文件_read方法
通过阅读源码分析到:
大致是由于ti(task_instance 的一个对象实例)的hostname属性无法拿到,导致
response的时候抛出异常,然后抛出以上报错
该部分核心代码见下图:
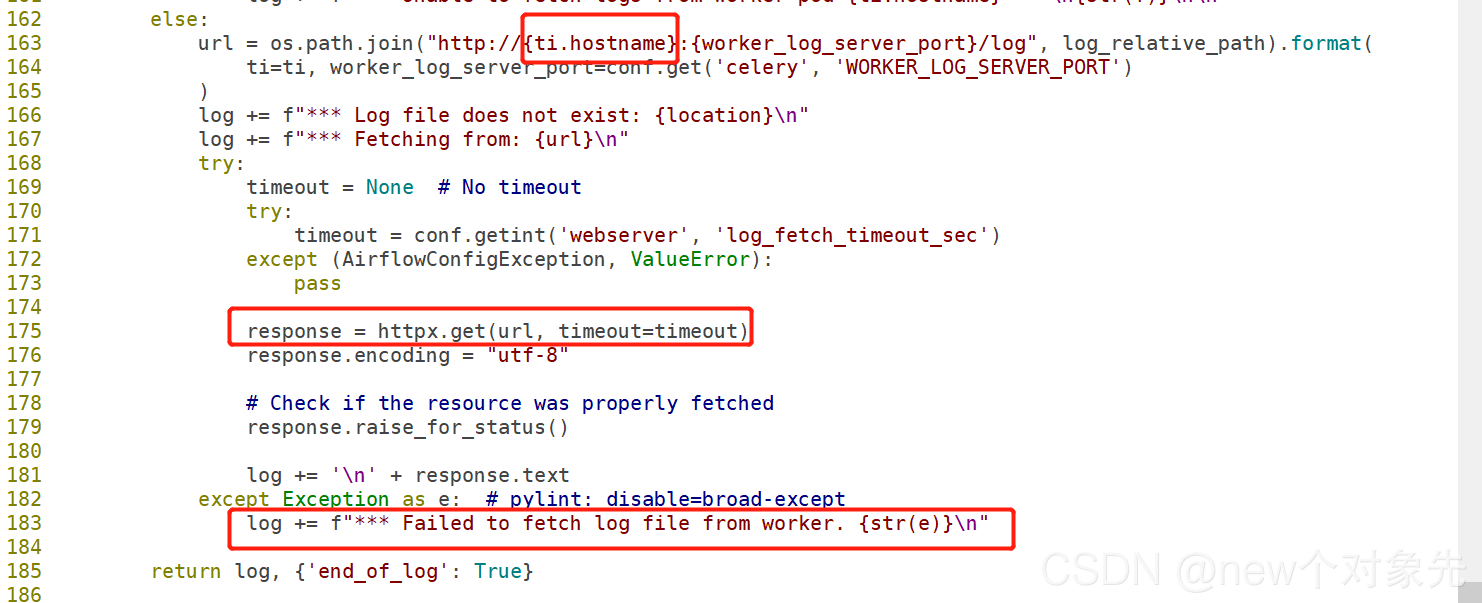
从该方法源码来看,在单机或者该task恰好由和webserver部署在同一个虚拟机或者容器下的worker执行和executor为KubernetesExecutor不会发生该问题
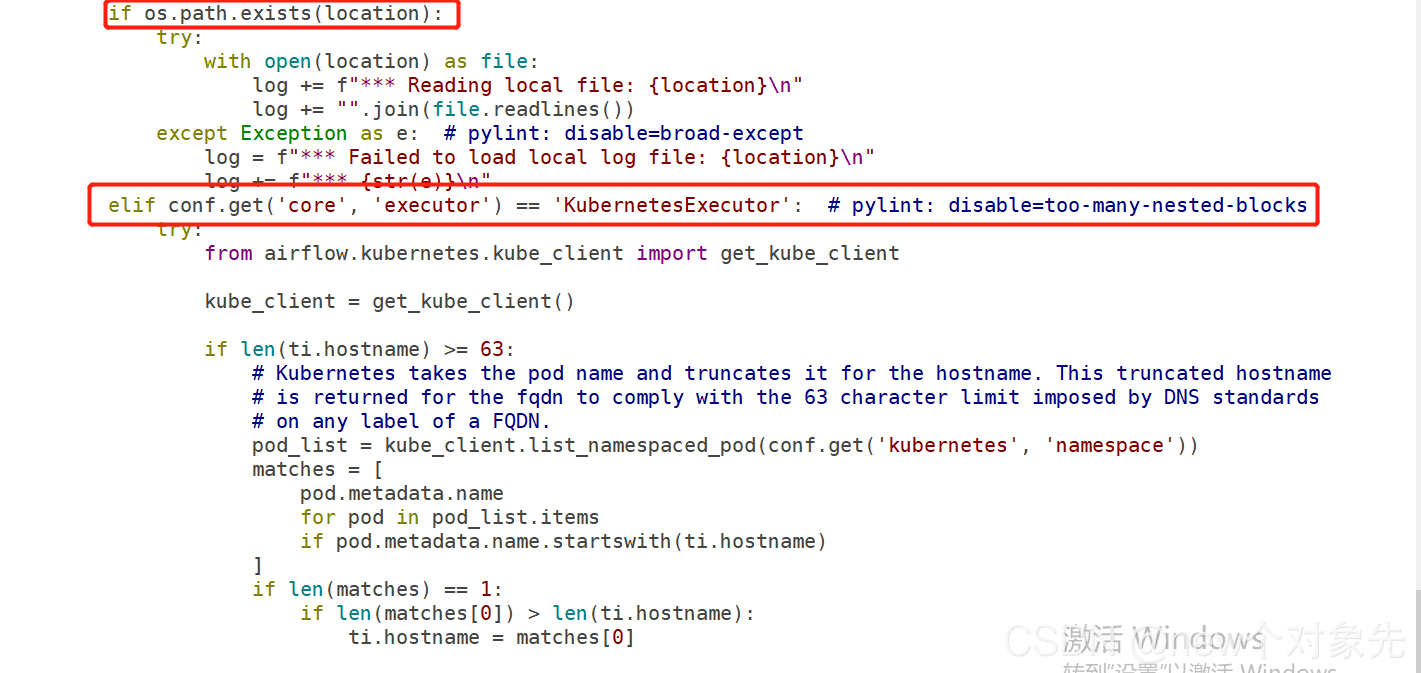
原因如下:
下一步,继续分析,为什么ti的hostname属性获取不到,
顺着_read的调用一层一层的查看源码,这里细节不在赘述,最终定位到
airflow/api_connexion/endpoints/log_endpoint.py文件get_log
在这里,我们能够找到task_instance实例ti的最初来源
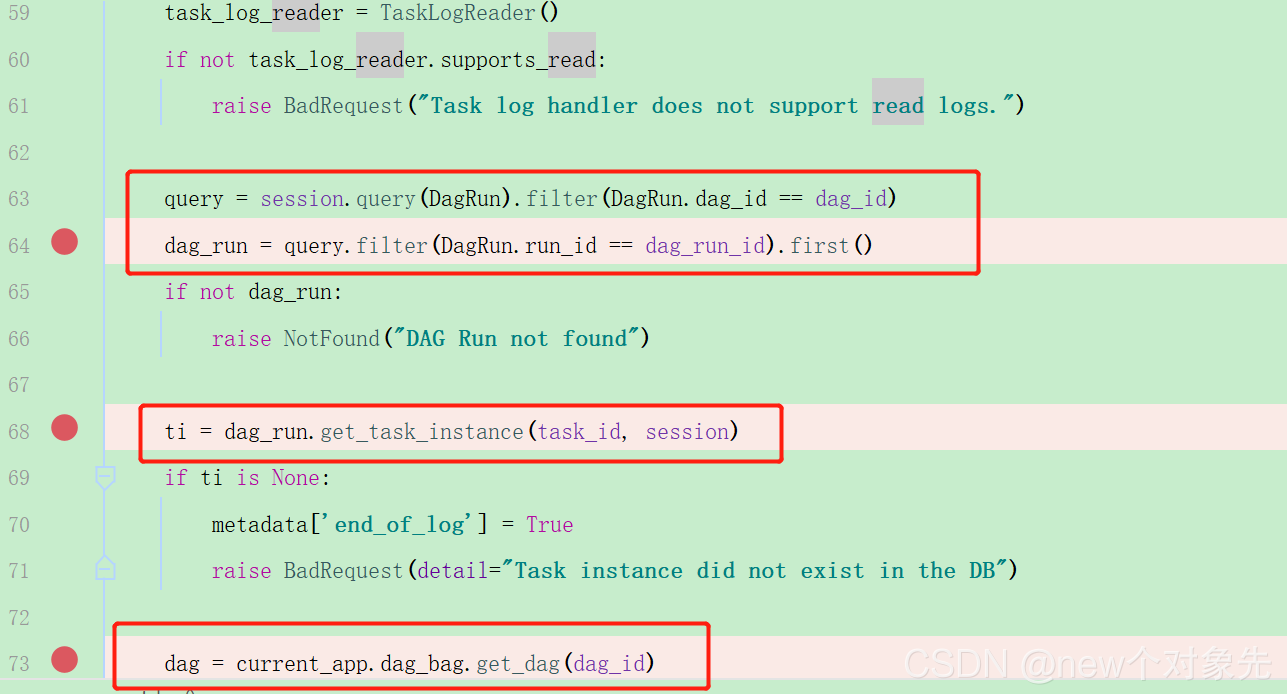
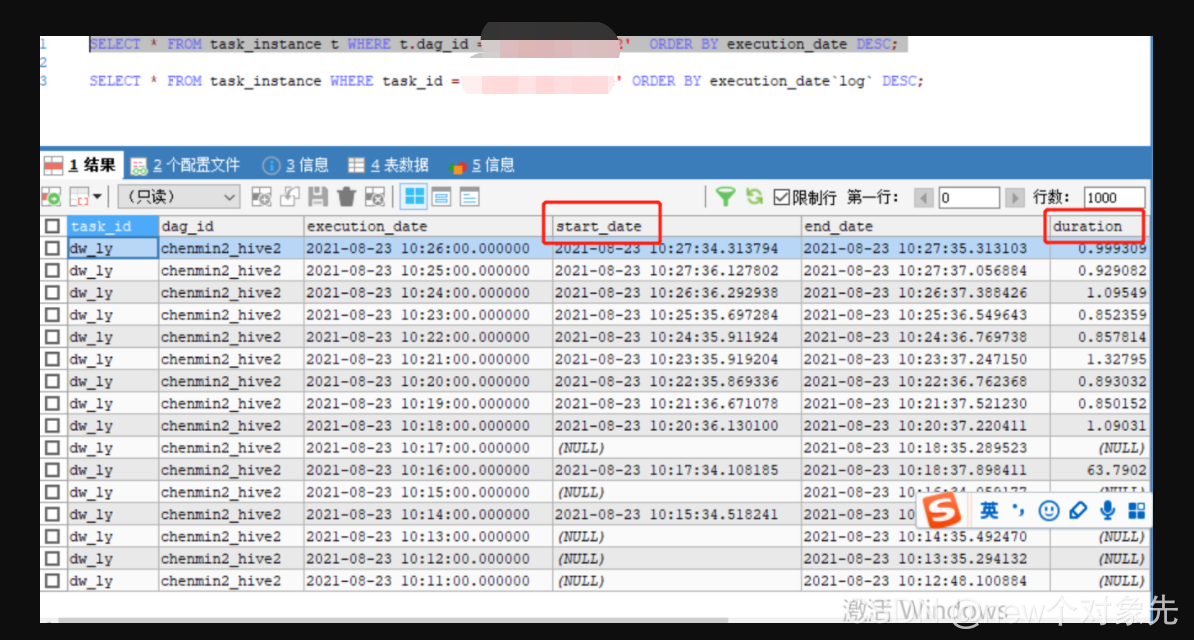
是通过数据库拿到的. 去数据库对应表查看相关数据,
发现只有dag在webserver所在节点执行时,数据库有存储主机名信息
数据库信息如下图:
这证明了,在最初将数据写入ti这张表的时候,就缺失了部分必要信息
进一步阅读源码,得到了这样的结论
目前Airflow在任务完成后而不是之前或期间将主机名提交到后端数据库。
如果任务中途发生严重崩溃或以其他方式中断,则数据库永远不会获取主机名并且我们无法获取日志。
因此, 解决这个问题的本质上就变成了,即使任务崩溃或以其他方式中断,我们也能够查看日志
2.2 确定解决方向
从上面的分析中, 我认为解决该问题有两个思路:
- 更改
airflow提交数据到后端数据库的逻辑,改为在任务完成前或者期间提交,看了下源码,发现这种方式变动会比较大,可能会影响到其它逻辑 - 尝试通过其它方式获取主机名
从成本和能力两方面的角度考虑,我选择了通过第二种方式去验证,
即:更改主机名的获取逻辑
于是,开始对airflow数据库的表进行分析,发现了log表在extra这个json串里,在某种条件下有存储hostname信息
经过各种sql语句的调试,确定了如下关联关系:
log.dag_id == ti.dag_id,
log.task_id == ti.task_id,
log.execution_date == ti.execution_date,
log.event == 'cli_task_run'
通过此方式,能够正确拿到有正确hostname信息的数据库数据
在这个阶段,发现github上面,有关于该问题的讨论,很多airflow使用者都碰到了
[AIRFLOW-4922]Fix task get log by Web UI #6722
同时,里面有开发者尝试针对该问题进行解决,我看了下代码,和我的思路是一致的.
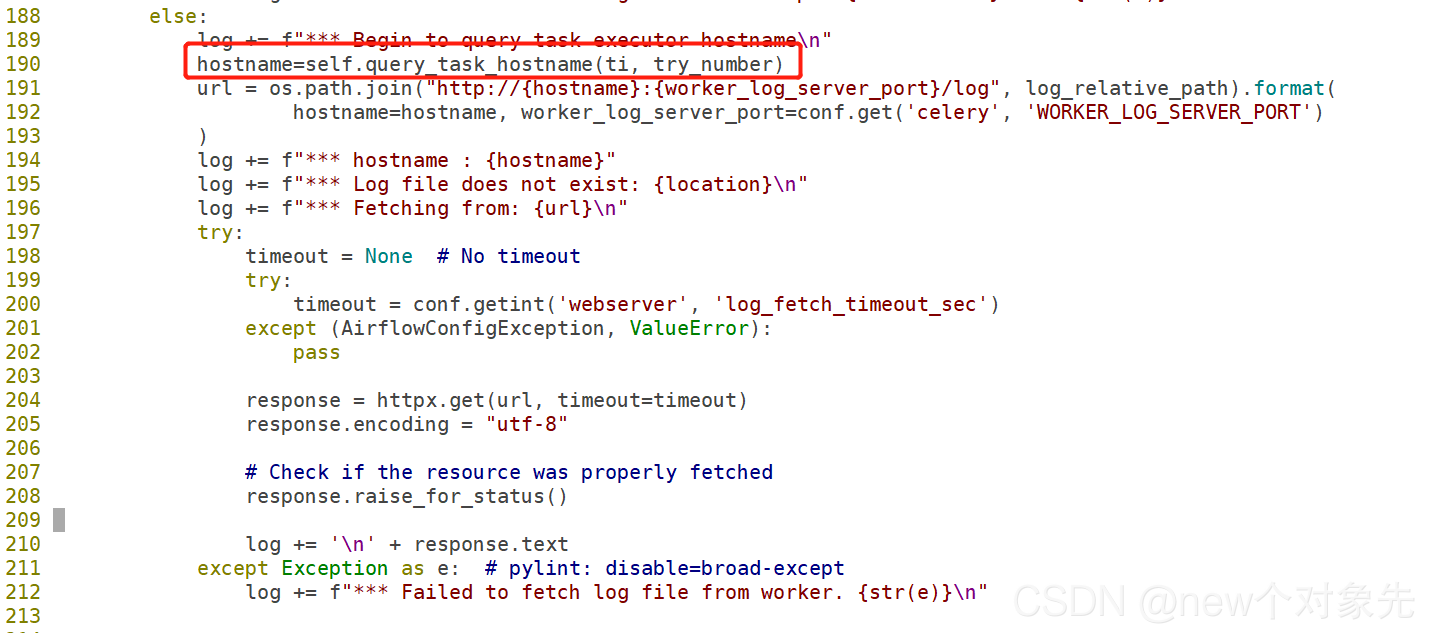
于是,参考他的代码,在airflow/utils/log/file_task_handler.py文件里添加了如下方法:query_task_hostname,代码如下:
@provide_session
def query_task_hostname(self, ti, try_number, session=None):
"""
Get task log hostname by log table and try_number
:param ti: task instance record
:param try_number: current try_number to read log from
:param session: database session
:type session: sqlalchemy.orm.session.Session
:return: log message hostname
"""
from airflow import models
res_log = session.query(models.Log).filter(
models.Log.dag_id == ti.dag_id,
models.Log.task_id == ti.task_id,
models.Log.execution_date == ti.execution_date,
models.Log.event == 'cli_task_run'
).order_by(models.Log.id).limit(1).first()
if res_log is not None:
hostname = json.loads(res_log.extra)["host_name"]
else:
hostname = ti.hostname
return hostname
同时,修改了_read方法关于hostname的获取方式,
代码见下图,我这里为了调试,额外添加了一些日志打印
源码修改完成后,重airflow,发现能够正确获取到主机名,但任务失败的时候仍然没有日志,
如下图:
从圈出来的地方可以看到,主机名是被正确获取的:
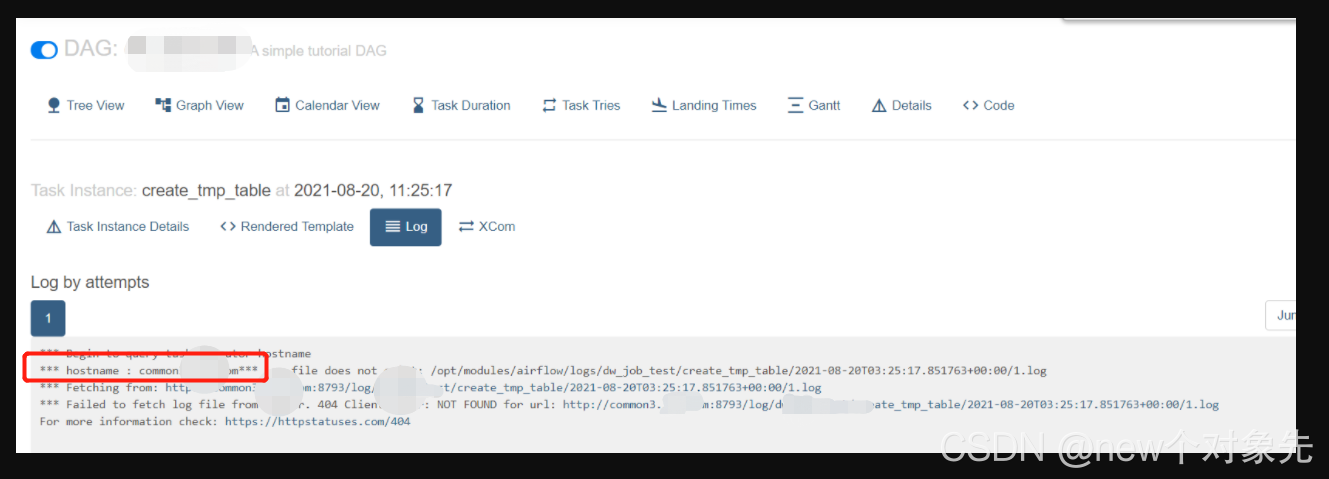
但和我们的预期不同
此时,去各节点后天查询,发现均无日志目录
证明节点日志并没有落盘.
在没有落盘的场景下, 无论怎么拉取都是拉取不到的,这证明了我们最初的推测可能存在问题,需要进行更多的测试来验证
2.3 单节点和分布式执行对比
首先,产生疑问:
上述出现问题发现,日志根本没有落盘,那么既然日志没有写入,逻辑上来讲,不管采用哪种读取方式,都是拉取不到的
因此,需要用控制变量法,用本地和分布式执行做对比
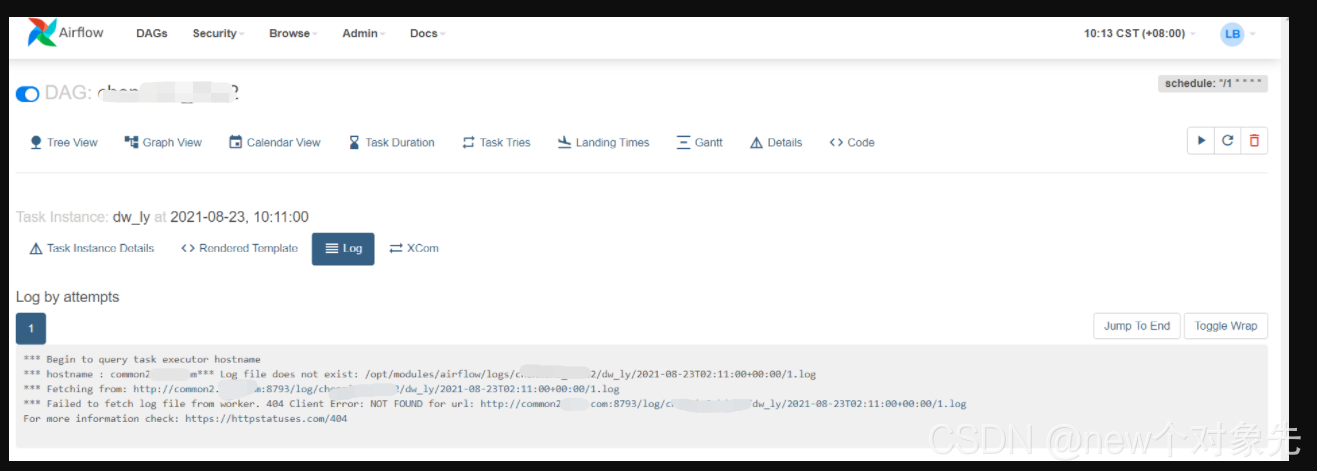
分布式执行结果:
特征:
1. worker部署在多节点
2. dag调度失败
3. 日志无法正常获取
单节点执行结果:
特征:
1. worker和webserver,scheduler部署在同一个节点
2. dag调度失败
3. 日志可以正常获取
对比数据库数据发现,task_instance这张表少了start_time,duration,hostname,pid等关键信息
基于很多人在github上面反馈这个问题,我坚信他是airflow一个悬而未决的bug
而且,通过目前的表现,从代码的层面来讲,需要让日志无论在任何情况下都能正常落盘
可想而知,这个改动是巨大的
那么,再思考一下,有没有其他的方式来规避这个问题?
一个可以考虑的做法是,既然本地存储失败,那么远程存储会不会出现这个问题呢?
于是想到了利用s3配置远程存储,这个不是此博客的重点.
配置方法可以参考stackoverflow下面的这个回答
setting up s3 for logs in airflow
远程存储配置成功后,重新启动airflow执行dag,发现仍然无法获取到失败dag的日志!
这个时候已经有点难顶…
大批量修改源码是条艰苦卓绝的路,除了实现之外,更要考虑到你的改动对现有功能的影响,
很可能解决了一个bug,引发了无数个bug,这个成本偏高.
三. 进一步排查测试
开始分析scheduler的调度日志,发现了如下信息:
[^[[34m2021-08-25 09:26:47,686^[[0m] {^[[34mscheduler_job.py:^[[0m1258} ERROR^[[0m - Executor reports task instance <TaskInstance: ***.****
2021-08-25 01:25:49.429359+00:00 [queued]> finished (failed) although the task says its queued. (Info: None) Was the task killed externally?^[[0m
怎么看怎么像是任务都没有被调度就已经失败了,如果是这种场景,从逻辑上来说,应该是合理的呀?
难道不是airflow的bug?我开始怀疑人生了…
于是,我找了一些相对复杂的dag在单节点,多节点反复调试…
发现了奇怪的现象:
- 在单节点能够执行成功的dag,在多节点执行失败
- 在多节点场景下,每次dag调度失败的地方不一致
这说明了以下问题:
1 dag本身的代码是没问题的,因为单节点可以执行成功
2 如果每次失败的地方不一致,那只能说明各个节点上的环境不是完全一致的?
难道是因为这个原因?
顺着这个方向,果然发现出错的部分落在同一台节点上!!!
该节点信息如下:
- 没有同步webserver节点的dag
- 部分
log子目录是root用户权限的,而任务调度的时候使用的airflow用户,没有权限
修改了这两个问题之后,重启airflow,惊喜的发现,dag执行失败的场景,也能正确获取到日志了!!!
如下图:
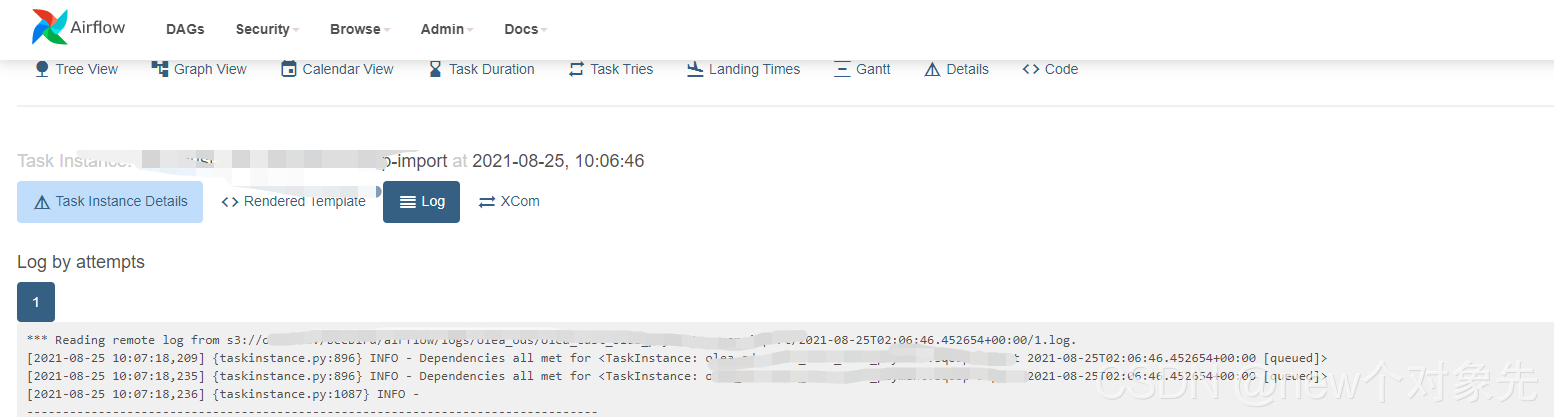

上面两张图片的task是失败状态,但是失败日志完完整整的拿到了!
问题解决!!
四.经验与教训
这个从踩坑测试到解决,前前后后用了我一个周的时间,
这一个周,吃的不香,睡得不好…
最后,居然是这么一个简单的事情…
回想起来,主要有以下几个问题:
思维固化
主要有以下几个表现:
- 当时查看数据库表结构时,发现
dag的代码是序列化存储在dag_code这张表里面的,
因此,就认为,只需要在webserver节点下面的dags目录下上传dag就OK了,不需要传递到其它节点
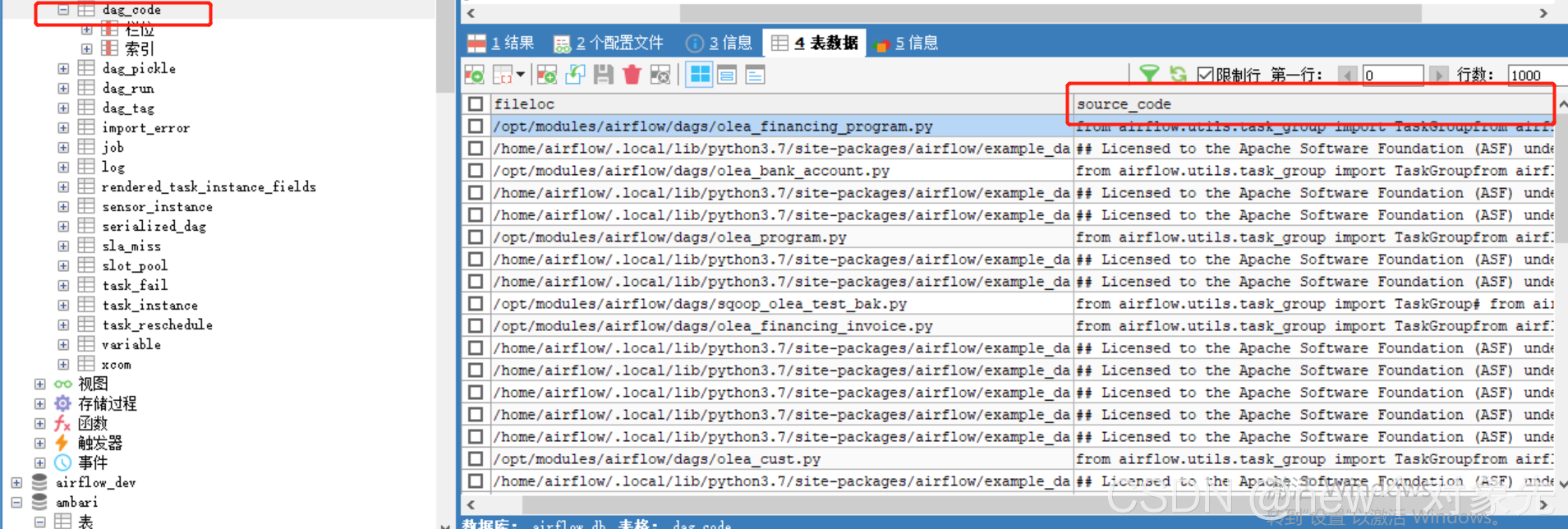
- 当时在
github上查到了这个issue,看到了很多人反馈这个问题,包括很多实用2.*版本的,
就坚定的认为,这么多人都遇到了,肯定是官方的bug.就没有过于关注自己使用上的问题
不够细心
主要体现在以下方面:
- 当时通过scp将数据同步到各个节点,却忘记了设置其中一台节点的权限,导致
airflow用户写日志的时候没有权限 - 排查错误日志的时候不够细心,漏掉了一些关键的信息,导致问题没有及时发现
工作不细心,自己两行泪啊!!!
五. 吐槽
最后再吐槽一下airflow官方文档,写的真叫一个简单!
基本上只有简单介绍,连个demo都没有
全是文字描述,没有截图!!
对我这种不够聪明的人来说,无疑是增大了学习成本,很容易走弯路
同时,国内社区有关airflow优质的内容并不多…
大家都抄来抄去的,甚至连排版,错误这些最基本的东西都不注意.感觉这种影响也蛮差的
还是希望大家能把自己的心得体会,多多分享,共同进步! 共同创建和谐的社区环境~

















 933
933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









