









Hadoop之MapReduce
分布式运算程序,可以说HDFS负责存储,YARN负责资源的调度,那么MapReduce就负责计算
特点:
- 良好扩展性
- 高容错性
- PB级以上的离线处理
缺点:
- 不擅长实时计算
- 不擅长流式计算
- 不擅长DAG(有向无环图)计算
一、MapReduce进程
- MrAppMaster:负责整个程序的过程调度及状态调度
- MapTask:负责Map阶段的整个数据处理流程
- ReduceTask:负责Reduce阶段的整个数据处理流程
二、WordCount程序例子
三、序列化
序列化: 将对象写入到IO流中
反序列化: 从IO流中恢复对象
意义: 序列化机制允许将实现序列化的Java对象转换位字节序列,这些字节序列可以保存在磁盘上,或通过网络传输,以达到以后恢复成原来的对象。序列化机制使得对象可以脱离程序的运行而独立存在。
基于Hadoop的分布式存储,不同的节点在不同的机器上,每个机器都有其JVM虚拟机,序列化能更好的让数据对象与不同机器上的进程进行交互。
序列化实操,自定义Bean对象。
。。。略
四、MapReduce 框架原理
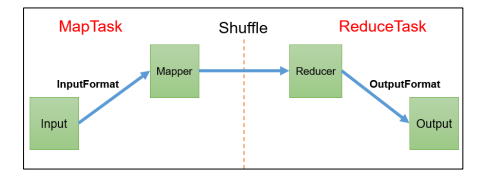
4.1 InputFormat数据输入
1、切片与MapTask并行度
数据块: HDFS上的物理数据块,存储单位。
数据切片:MapRedece程序计算的逻辑块,输入数据的单位
一个一片对应着一个MapTask,切片大小默认是BlockSize(块大小)。
2、FileInputFormat的切片机制
(1)简单的按照文件的内容长度进行切片。
(2)切片大小,默认等于Block大小。
(3)切片时不考虑数据集整体,而是逐个针对每一个文件单独切片。
(4)切片剩余部分是否大于块的1.1倍,不大于1.1倍就划分为一块切片。
3、FileInputFormat的实现类
TextInputFormat、KeyValueTextInputFormat、NLineInputFormat、CombineTextInputFormat和自定义InputFormat等
对应着不同的输入数据类型。
TextInputFormat















 2928
2928











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









