







学习曲线

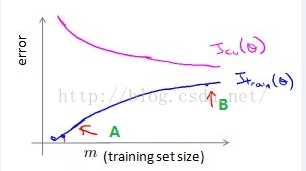
两种都是对的,前者是误差率,后者是准确率。
训练集小时,模型过拟合,随着训练集规模变大,训练集上误差率上升,而测试集误差率降低。
测试集的误差率总是大于等于训练集的误差率(模型通过梯度下降最小化训练集样本的误差函数,从而确定模型的参数)。
模型的误差分为训练误差和泛化误差两类。前者指模型在训练数据集上表现出的误差,后者指模型在任意一个测试数据样本上表现出的误差的期望,并常常通过测试数据集上的误差来近似(通常用交叉验证来估计泛化误差)。模型选择要关注泛化误差。
可以由学习曲线判断过拟合和欠拟合。
模型复杂度
除了训练集的大小外,模型复杂度也有很大的影响。

训练轮数
正常

欠拟合

过拟合
















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









