






17 ClickHouse为什么快
ClickHouse起源


核心特征
ClickHouse 被称为数据库管理系统,提供了一套功能和接口,它允许在运行时创建表和数据库、加载数据和运行查询,让用户能够方便地对数据库进行管理和操作。
ClickHouse 号称能够得到每秒几亿行的吞吐能力,远超像 HBase、Cassandra 等数据库所说的每秒数十万的吞吐能力。当然,在我看来这个对比确实不在同一个标准,因为 HBase 这类数据库更适合在实时随机存取场景,ClickHouse 适合在批量导入与分析场景
列式存储
不同于 HBase 的宽列存储,StarRocks 的列式存储加混合存储,ClickHouse 是纯列式存储


向量化执行
向量化执行,可以认为是一个将需要多次执行的循环,用一次并行执行完成的优化。想想在列式存储场景中,比如需要做两个字段求和的统计分析,是不是之前需要逐行求和,用了向量化执行后,批量的“披萨原料”也就是数据已经现成准备好,然后一起批量烤制,是不是速度也快了,吞吐量也上来了。

灵活的表引擎
合并树(MergeTree)家族、日志引擎系列、集成表引擎、其他特殊表引擎 4 大类,这 4 大类下面一共有几十种表引擎。每一个表引擎都有自己的特点,适合不同的业务场景。

索引支持

分布式架构

18 ClickHouse如何选用表引擎
MergeTree



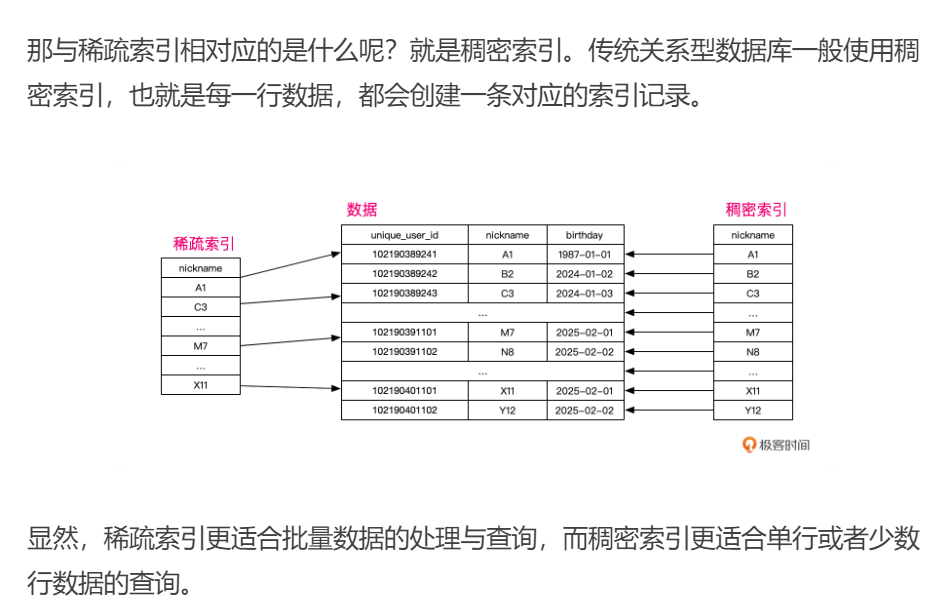
ClickHouse 的稀疏索引默认每 8192 行数据创建一个索引标记,你也可以通过建表参数 index_granularity 修改这个默认值。
ReplacingMergeTree















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









