






- 梯度下降法
- SGD
- BGD
- 牛顿法
- 基本牛顿法
- 全局牛顿法
- 拟牛顿法
- DFP
- BFGS
- L-BFGS
- 共轭梯度
- 启发式
- *解决约束优化问题:拉格朗日乘数法
1. 梯度下降法
过程
梯度下降法是一个最优化算法,通常也称为最速下降法。最速下降法是求解无约束优化问题最简单和最古老的方法之一,虽然现已不具有实用性,但是许多有效算法都是以它为基础进行改进和修正而得到的。最速下降法是用负梯度方向为搜索方向的。可以用于求解非线性方程组。
梯度:对于可微的数量场
举一个非常简单的例子,如求函数 ![]() 的最小值。利用梯度下降的方法解题步骤如下:
的最小值。利用梯度下降的方法解题步骤如下:
- 求梯度,

- 向梯度相反的方向移动
 ,如下
,如下
- 循环迭代步骤2,直到
 的值变化到使得
的值变化到使得 在两次迭代之间的差值足够小,比如0.00000001,也就是说,直到两次迭代计算出来的 基本没有变化,则说明此时 已经达到局部最小值了。
在两次迭代之间的差值足够小,比如0.00000001,也就是说,直到两次迭代计算出来的 基本没有变化,则说明此时 已经达到局部最小值了。 - 此时,输出
 这个 就是使得函数 最小时的的取值 。
这个 就是使得函数 最小时的的取值 。
其中,
优缺点
- 靠近极小值时收敛速度减慢。
- 直线搜索时可能会产生一些问题。
- 可能会“之字形”地下降。
批量梯度下降BGD
在训练时会有一个代价函数。常见形式为所有特征损失的和除以样本数得到均值。如果要对参数求偏导,那么就要用到训练集的所有数据。u 过样本数很大,那么迭代的次数会相当大并且速度很慢。假设批量梯度的样本个数为m,特征维度为n,则需要计算m*n^2次。
最小化所有训练样本的损失函数,使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小,但是对于大规模样本问题效率低下。
随机梯度下降SGD
随机梯度下降通过每个样本来迭代更新一次。可以不用遍历所有的样本。但是噪音比BGD多,并且下降方向不一定是最优的。
最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近,适用于大规模训练样本情况。
====================================================================================================================================
当选取step size  时,算法在期望的意义下收敛。注意到在靠近极小值点
时,算法在期望的意义下收敛。注意到在靠近极小值点 时,
时,,这导致随机梯度下降法精度低。由于方差的存在,要使得算法收敛,就需要
 随
随 逐渐减小。因此导致函数即使在强凸且光滑的条件下,收敛速度也只有
逐渐减小。因此导致函数即使在强凸且光滑的条件下,收敛速度也只有 . 后来提出的变种SAG,SVRG,SDCA都是在降方差,为了保证在
. 后来提出的变种SAG,SVRG,SDCA都是在降方差,为了保证在 时,方差趋于0。以上提到的几种变种都能达到线性收敛速度。
时,方差趋于0。以上提到的几种变种都能达到线性收敛速度。
作者:Qi Qi
链接:https://www.zhihu.com/question/28728418/answer/45334538
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2. 牛顿法
牛顿法的基本思想是利用迭代点基本牛顿法

1阶导数是梯度,二阶导数是Hessian矩阵,必须
保持正定。
全局(阻尼)牛顿法
基本牛顿法的初始点的选择如果没有靠近极小值点,有可能使算法不能够收敛。但是全局牛顿法是可以的。这是一种
精确搜索。

但是A准则条件下,有可能使得极小值点不在判决的区间里面,所以有了Wolfe-Powell准则。A准则的两条都是关于限制fx的值的,但是W准则的第二条是限制梯度的:
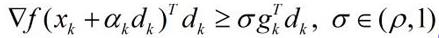
有时,会有一个更强的约束:
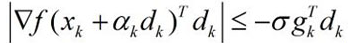
这样区间内的梯度不会太大,更逼近极值点。
优缺点
牛顿法是二阶收敛,梯度下降是一阶收敛,所以牛顿法就更快。如果更通俗地说的话,比如你想找一条最短的路径走到一个盆地的最底部,梯度下降法每次只从你当前所处位置选一个坡度最大的方向走一步,牛顿法在选择方向时,不仅会考虑坡度是否够大,还会考虑你走了一步之后,坡度是否会变得更大。所以,可以说牛顿法比梯度下降法看得更远一点,能更快地走到最底部。
根据wiki上的解释,从几何上说,牛顿法就是用一个二次曲面去拟合你当前所处位置的局部曲面,而梯度下降法是用一个平面去拟合当前的局部曲面,通常情况下,二次曲面的拟合会比平面更好,所以牛顿法选择的下降路径会更符合真实的最优下降路径。
作者:知乎用户
链接:https://www.zhihu.com/question/19723347/answer/14636244
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
但是,1. 对目标函数有严格的要求,必须有连续的一、二阶偏导数,海森矩阵必须正定。2. 计算相当复杂,除了计算梯度,还需要计算二阶偏导数矩阵以及逆矩阵。计算量/存储量均很大,且均以维数N的平方比增加。
3. 拟牛顿法
拟牛顿条件:

DFP算法
用迭代的方法对海森矩阵的逆做近似。一般初始近似矩阵为单位矩阵。
BFGS算法
不是逼近矩阵的逆,而是直接逼近海森矩阵















 2532
2532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









