






别催啦,我的脑子快炸啦!
—— 某天某服务器过载时发言
服务挂了,数据库崩了,宕机了这些令人谈其色变的词语,在谈及系统的稳定性时总是永远绕不开。许多服务平时跑着问题不大,一旦并发上来后总是有各种性能瓶颈。
为了分析服务的性能瓶颈,评估系统的容量以及预算,线上压测能力成为了公司必不可少的一个能力。此前,我有幸参与到了公司的全链路压测的建设当中,负责部门下单链路的压测改造。此篇文章,我也将结合我的经验,以及自己的一些想法,欢迎大家评论区讨论。
下单的链路,往往是最重要且复杂的。交易中台为了承接各个业务方向的售卖需求,往往将服务节点拆分得特别细。我们来看下图的一张售卖链路。
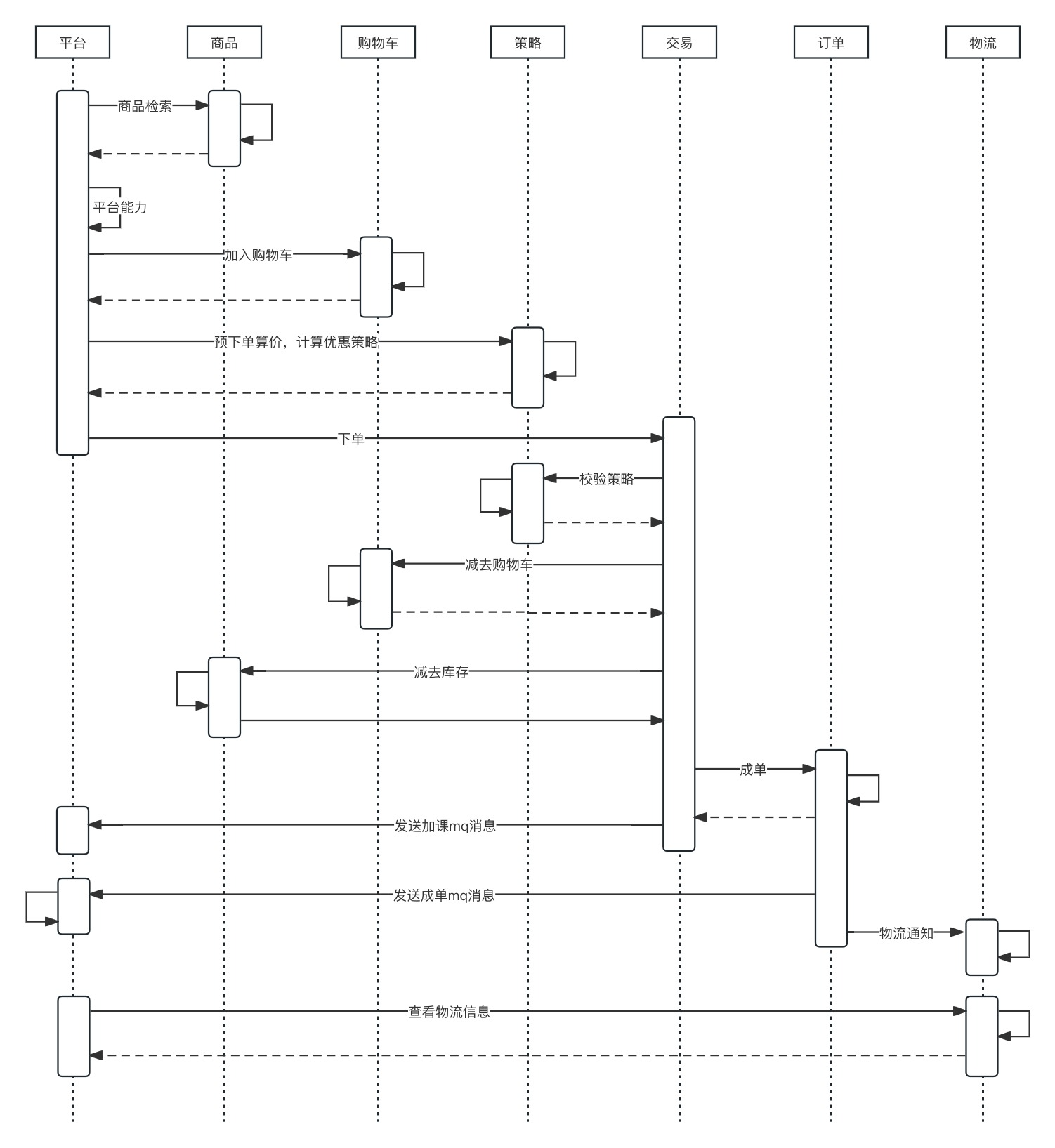
一条压测链路,涉及到的部门非常多,同时参与进来的人员包括研发、测试和运维。项目还未启动就有着各种问题,各部门之间的协调统筹,各个服务技术栈的调研等(当然这不是我的工作)。想要做好全链路测试,还需要从这三个问题出发:
- 需要哪些团队参与?
- 全链路压测的目标?
- 技术方案如何制定?
需要哪些团队参与
全链路压测涉及之广,一开始就需要得到老大的支持。在老大的牵头下,参与进的人员至少就需要包括:研发、测试和运维。研发负责制定全链路压测的方案和实施,如果团队有架构组,或是dba,可以协助定制压测方案,或是参与方案的验收。测试负责压测链路的验证,压测任务的准备,以及压测数据的构造。运维则需关注服务的压力等,但一般我们是在凌晨进行压测,对线上压力基本无需关注。
全链路压测是一个费时费力的工作,特别是最开始的时候,要么会出现各个业务线之间协议定义问题;要么会出现压测时系统崩溃;但随着经验逐渐增多,花费的时间会越来越少,逐步形成一个稳定且成熟的流程。
全链路压测的目标
不同的压测目标,必然也会影响技术方案的制定。拿我们部门举例,业务部门在一年中会有10几到20次的大促,在大促期间产生的问题都会被升级,这点上半年我们也吃了不少亏。因此,压测的首要目标就是保障下一次大促的稳定性。
这时我们会将压测的目标定位上一次大促流量峰值的3倍进行压测,并且保障系统各项指标的稳定,比如CPU使用率规定了不能超过30%,否则视为压测不通过。
此外,压测的目标也可以这样制定。比如我们的售卖系统当前可以支撑日峰值为100w+订单,而业务的目标预期是日300w+订单,则我们的目标可以设置为600w。因为哪怕系统健壮性足够强大,在大并发下依旧会产生各种各样的问题。当然,发现问题也就意味着我们发现了系统的瓶颈,这同样也是全链路压测的目标。
另外,压测计划同样非常重要,因为上一次压测的结果会非常快过期。依旧拿我们举例子,每次大促的场景并不相同,有时为小初大促,有时为高中大促。每次大促的参与人数,参与时间并不相同,对应的压测节奏和结论也会相差较大。制定明确的压测计划,也可以有效降低人力成本。
技术方案制定
技术方案的制定,是全链路压测中最难的一部分。设计几乎占了70%的工作量,仅仅沟通压测协议,来来回回开了不知道多少会。
如下图,是我负责的模块所经历的链路以及所用技术栈情况。我们服务使用php和golang作为主要语言。服务之间通过grpc进行通信,异步通信则采用rocketmq,存储则是使用mysql和redis。
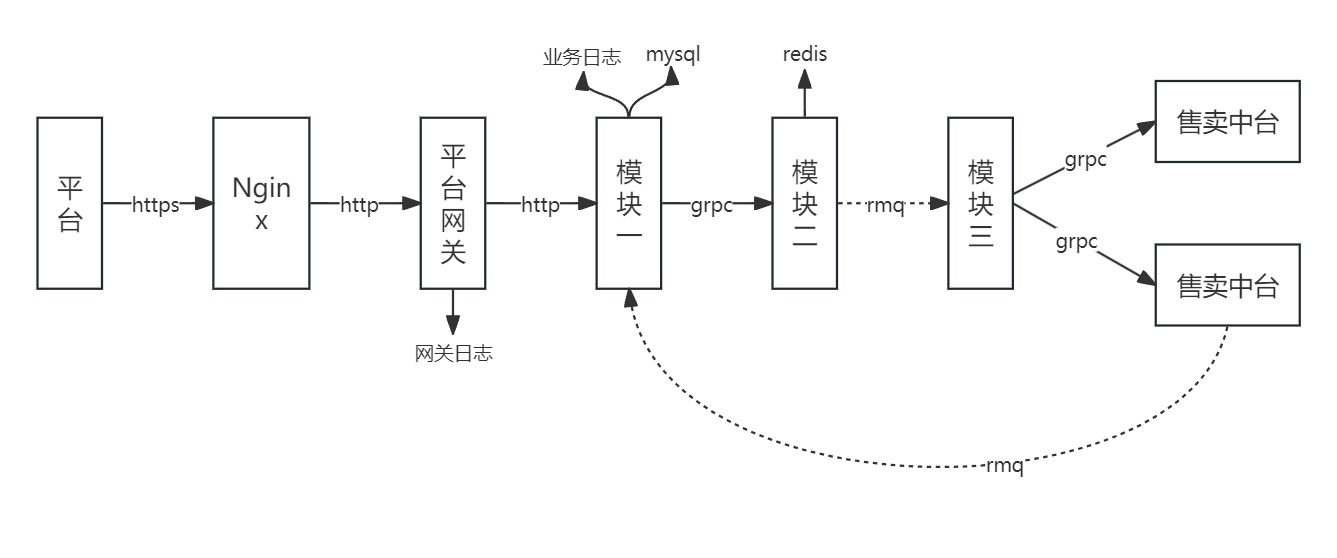
在我看来,部门所用技术栈还算是比较通用。接下来的步骤,我就依然按照我们的思路讲解。
确定压测的全链路
一般来讲,全链路并不一定指所有接口都跑一遍。一般是对于核心链路如下单,或是对核心f0功能涉及链路进行压测,找到这些链路的顶级入口,一般就是用户直接访问的接口,就可以定位压测的主要入口。
对于我所负责的一线平台服务,找到顶级入口和核心链路并不是很难,难点在于找到链路中涉及的相关下游,对齐并评估改造的影响点。
压测标识在全链路的处理和传递
这也是所有流程中最复杂的一步。我们需要保证压测标识能在各个服务之间安全地传递,并且有效地和线上真实请求区分开来,否则就很有可能造成线上事故。
保证压测标识的低侵入
全链路中涉及的模块之多,低侵入地实现方式,对稳定性有所保障的同时,还便于推广。
由压测平台发起的压测请求,会带上自定义header作为压测协议,协议包括了是否压测、压测发起人uid、压测模拟时间、压测模拟页面等参数。基于此协议,各个服务可以根据子模块公用方法识别是否是压测流量。
/**
* @return bool
* TRUE 是压测;FALSE不是压测
*/
public static function isPressure()
{
$callerURI = isset($_SERVER['yace_uri']) ? $_SERVER['yace_uri'] : null;
if (empty($callerURI)) {
return false;
}
...
if (//识别压测标识) {
return true;
}
return false;
}
不同模块应具备私有标识。
我负责模块的场景流程,是由辅导老师替学生下单,再将支付二维码发至用户支付,这样一个流程。因此,压测更多需要模拟多个老师下单的流程。
由于辅导老师是我们平台服务的对象,售卖中台不关注辅导老师的信息。因此,在压测header的基础上,我们还在Cookie中自定义XUID属性,模拟使用真实老师uid进行操作。
服务内处理
为了防止脏数据的产生影响线上,模块还需对老师uid、学生uid以及订单id进行偏移。使用自定义的加密函数,将uid偏移为不影响线上。
对于golang而言,在协程中执行,以及在协程中再开协程的时候,压测标识比较容易丢失。部门的技术栈使用的是gin框架,因此,我们修改了gin中的context结构体,加入了全链路压测的属性(在开发规范中,我们还强制要求研发不能直接使用gin自带的初始化方法)。这样即使是在协程中,我们依旧可以通过传递context的方式传递标识。
另外,全链路压测的日志也需要与线上日志隔离开。一方面是为了不污染线上日志,另一方面也是为了准确区分压测流量和线上流量,因为当前op实现流量监控和告警都是通过日志进行采集。(当然,其实这点没有做,只是我觉得这样更好,因此补充上来)
服务之间通信
服务间通信,则交由grpc透传header。在透传时也应注意,下游接口是读接口还是写接口,如果是没有参与全链路压测的读接口,还需要将uid进行回归后,再传递于下游。
RocketMq本身也是自带了透传压测header的能力,因此直接使用即可。另外,架构组也提供了配置能力,使用方可以选择是否过滤压测的mq,以及mq限速。
服务外
这里主要是持久化、缓存、以及cos等外部服务。为了不对线上产生影响,存储层做好隔离是必须的,所以我们事先建好了影子表。影子表和线上真实表结构是一模一样的,唯一的区别就是在表名后加了“Shadow”后缀。
//数据隔离,表名统一加shadow
protected function initShadow() {
/* --- 压测流量读写走影子表 Start--- */
$isPressure = isPressure();
if($isPressure) {
$this->_table = $this->_table.'Shadow';
}
/* --- 压测流量读写走影子表 End--- */
}
这里之所以做成表级别的隔离没做库级别的隔离,除了成本问题,在服务当中,也有不少提供查询能力的表(例如配置中心),这一部分我们并不期望走到影子表。因此,在基类我们做成了插件式的用法,只对写操作相关的表进行影子表处理。
对于缓存,我们使用的是Redis,这一块处理也相似,考虑成本问题,我们并没有做库层的隔离,而是做key层的隔离,识别到压测流量,则给key加上“_shadow”后缀,保证压测流量不污染线上缓存数据。
确保全链路压测流量能被监控到
如果部门有相应的压测平台,压测平台可以记录下每次发压的链路以及相应的监控,以及系统各项指标。
改造完成后,最终结构会变成如下:
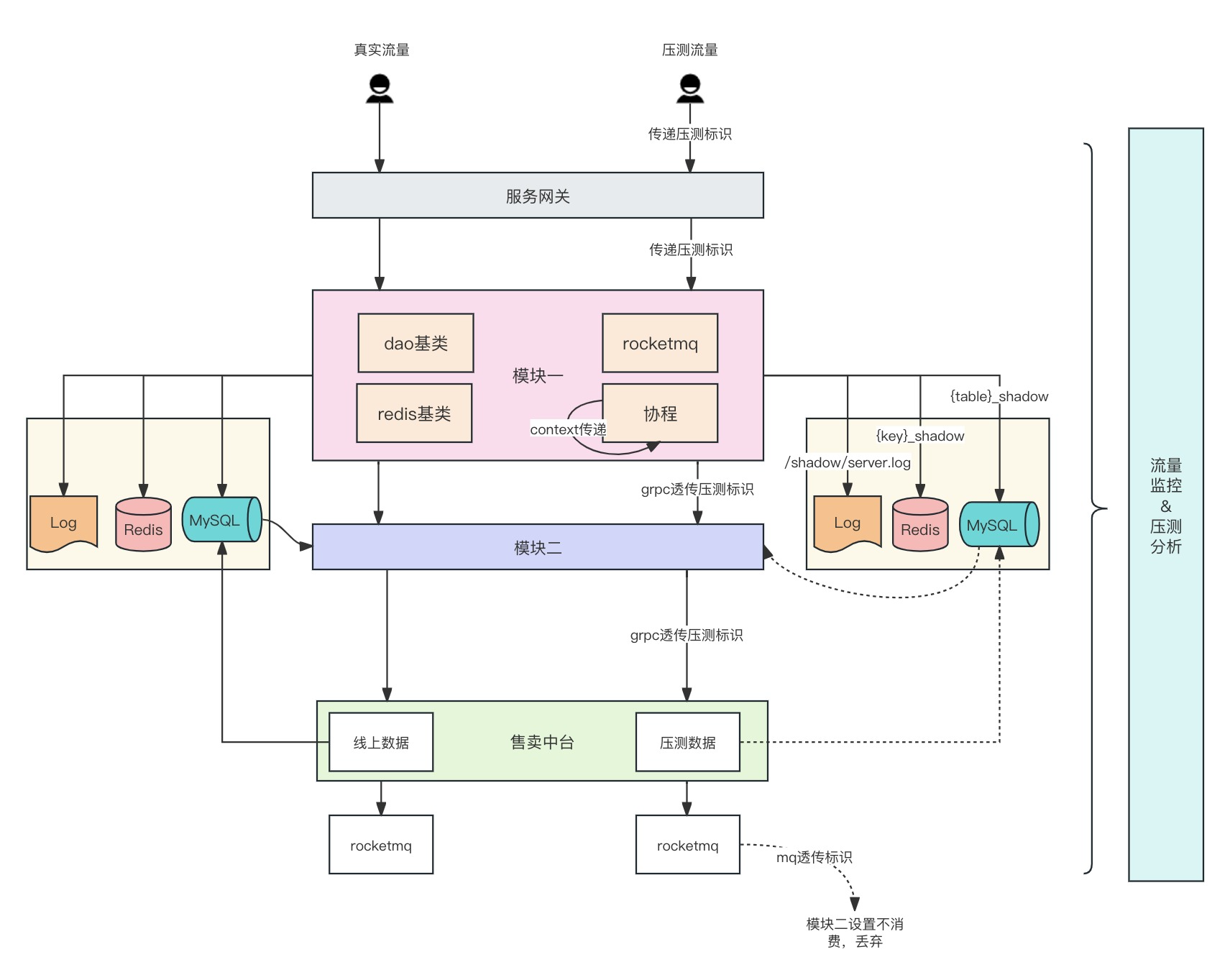
全链路压测一些感想
在经历了几次全链路压测后,我对于服务也有一些感想
- 服务是否是cpu密集型,cpu使用率比较低,可以将pod核数缩小+pod扩容。
- 指标不止需要关注整体服务,也需要深入单个pod,腾讯集群和阿里集群之间具有隔离性,并不互通。不同集群在面对相同压力请求时,也具有不同表现。(特别是最近阿里稳定性并不强)
- cpu达标并不意味着一定达标了,是否会导致慢sql,会不会导致连接过多未释放,mq是否有delayer等。
如果这篇文章对您有帮助,欢迎一键三连,这次一定哦!欢迎关注公众号「林枍」,多多交流,多多讨论。
















 4445
4445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









