









依然是导包创建Neo4j实例
from dotenv import load_dotenv
import os
from langchain_community.graphs import Neo4jGraph
# Warning control
import warnings
warnings.filterwarnings("ignore")
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE')
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Note the code below is unique to this course environment, and not a
# standard part of Neo4j's integration with OpenAI. Remove if running
# in your own environment.
OPENAI_ENDPOINT = os.getenv('OPENAI_BASE_URL') + '/embeddings'
# Connect to the knowledge graph instance using LangChain
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)
2 创建向量索引
#第一行创建向量索引,并命名为 movie_tagline_embeddings
#第二行为m节点创建索引,这些节点具有标签:Movie,
#并且对于电影的标语属性(taglineEmbedding)创建嵌入(embeddings)并存储他们
#OPTIONS 选项里有索引配置,作为索引配置对象传进去
#这里有两个重要配置:第一个是向量为度,这里设置为1536(openai 的embedding模型的默认大小)
#另外一个就是余弦相似度
kg.query("""
CREATE VECTOR INDEX movie_tagline_embeddings IF NOT EXISTS
FOR (m:Movie) ON (m.taglineEmbedding)
OPTIONS { indexConfig: {
`vector.dimensions`: 1536,
`vector.similarity_function`: 'cosine'
}}"""
)
想要验证索引是否已经创建,可以要求Neo4j直接显示向量索引
kg.query("""
SHOW VECTOR INDEXES
"""
)

3 填充向量索引(进行编码)
- 使用OpenAI计算每个电影标语(movie.tagline)的矢量表示
- 将矢量添加到“
Movie”节点作为taglineEmbedding属性
#第一行:执行找到电影标语不是None的电影
#第二行 对电影的 tagline属性进行编码,然后使用的是openAI编码模型
# $ 传入参数位置及代变量,在后面的params 参数字典里传入相应的参数字典值
# CAll 哪一行就是: 将矢量添加到“`Movie`”节点作为`taglineEmbedding`属性
kg.query("""
MATCH (movie:Movie) WHERE movie.tagline IS NOT NULL
WITH movie, genai.vector.encode(
movie.tagline,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS vector
CALL db.create.setNodeVectorProperty(movie, "taglineEmbedding", vector)
""",
params={"openAiApiKey":OPENAI_API_KEY, "openAiEndpoint": OPENAI_ENDPOINT} )
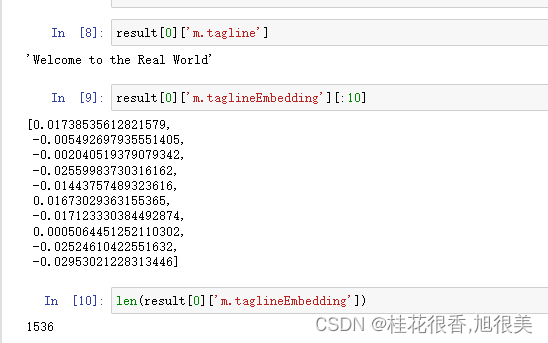
现在查看下标语及计算出来的文本编码嵌入
result = kg.query("""
MATCH (m:Movie)
WHERE m.tagline IS NOT NULL
RETURN m.tagline, m.taglineEmbedding
LIMIT 1
"""
)
4 相似性搜索
- 相似性搜索计算question的嵌入
- 基于question和标语的相似性识别匹配的电影嵌入向量(
taglineEmbedding)
# 我们之前对标语进行了向量索引构建
# 因此我们对那些标语进行相似性搜索
# with as 语句对问题进行同种当时的编码
# CALL db.index.vector.queryNodes 是用来进行相似度搜多的函数,返回我们想要的若干节点(后面根据节点拿到节点的属性数据)
# RETURN 返回相似度搜索到的电影的title和tagline以及相似度分数
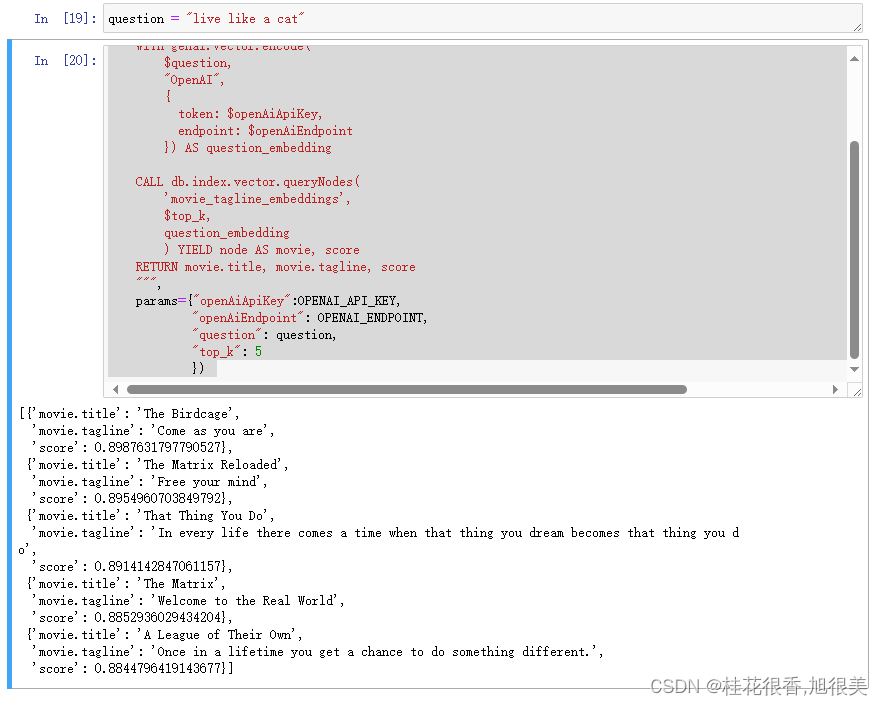
kg.query("""
WITH genai.vector.encode(
$question,
"OpenAI",
{
token: $openAiApiKey,
endpoint: $openAiEndpoint
}) AS question_embedding
CALL db.index.vector.queryNodes(
'movie_tagline_embeddings',
$top_k,
question_embedding
) YIELD node AS movie, score
RETURN movie.title, movie.tagline, score
""",
params={"openAiApiKey":OPENAI_API_KEY,
"openAiEndpoint": OPENAI_ENDPOINT,
"question": question,
"top_k": 5
})

换个question试试















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









