









Adding Relationships to the SEC Knowledge Graph
1 导包并设置Neo4j
from dotenv import load_dotenv
import os
# Common data processing
import textwrap
# Langchain
from langchain_community.graphs import Neo4jGraph
from langchain_community.vectorstores import Neo4jVector
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.chains import RetrievalQAWithSourcesChain
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIEmbeddings
# Warning control
import warnings
warnings.filterwarnings("ignore")
# Load from environment
load_dotenv('.env', override=True)
NEO4J_URI = os.getenv('NEO4J_URI')
NEO4J_USERNAME = os.getenv('NEO4J_USERNAME')
NEO4J_PASSWORD = os.getenv('NEO4J_PASSWORD')
NEO4J_DATABASE = os.getenv('NEO4J_DATABASE') or 'neo4j'
# Global constants
VECTOR_INDEX_NAME = 'form_10k_chunks'
VECTOR_NODE_LABEL = 'Chunk'
VECTOR_SOURCE_PROPERTY = 'text'
VECTOR_EMBEDDING_PROPERTY = 'textEmbedding'
1.1 实例化Neo4j链接
kg = Neo4jGraph(
url=NEO4J_URI, username=NEO4J_USERNAME, password=NEO4J_PASSWORD, database=NEO4J_DATABASE
)
2 创建10-K Form的节点
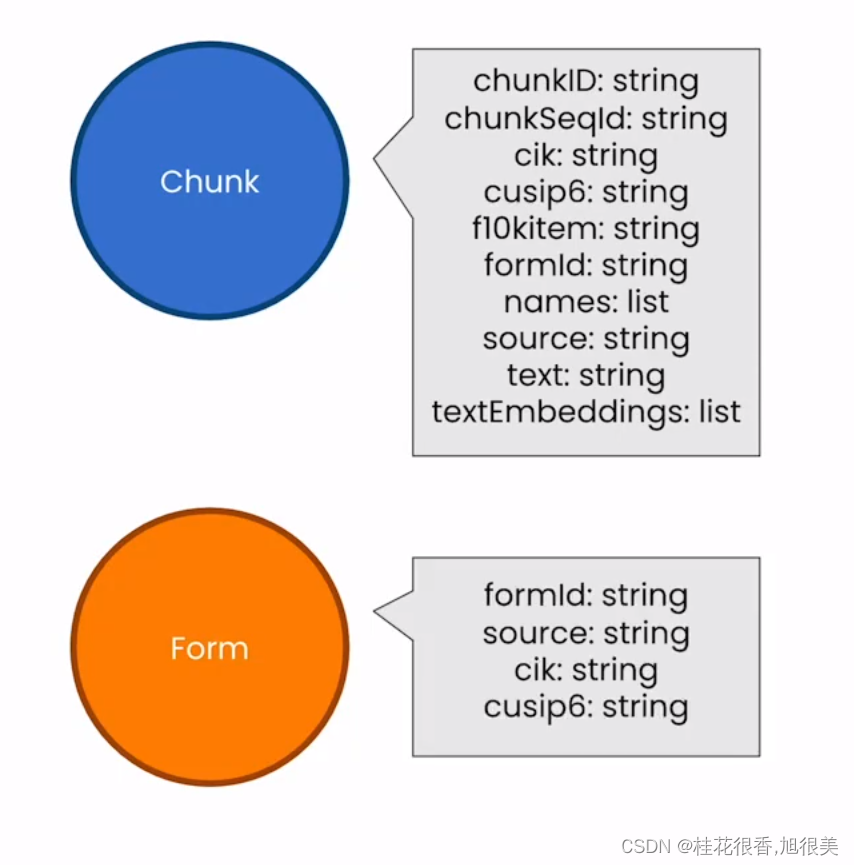
- 创建一个节点来表示整个Form 10-K
- 使用取自表单单个块的元数据填充
2.1 获取表节点的原始数据
# 每个块都包含我们需要创建表节点的信息
# 所以可以匹配任意块,然后使用这个快,只需要返回其中的一个节点
# 然后使用这种特殊的标记来从任何块节点的属性中提取特定的键
cypher = """
MATCH (anyChunk:Chunk)
WITH anyChunk LIMIT 1
RETURN anyChunk { .names, .source, .formId, .cik, .cusip6 } as formInfo
"""
form_info_list = kg.query(cypher)
form_info_list

#给个变量存一下
form_info = form_info_list[0]['formInfo']

2.2 创建表节点
cypher = """
MERGE (f:Form {formId: $formInfoParam.formId })
ON CREATE
SET f.names = $formInfoParam.names
SET f.source = $formInfoParam.source
SET f.cik = $formInfoParam.cik
SET f.cusip6 = $formInfoParam.cusip6
"""
kg.query(cypher, params={'formInfoParam': form_info})
查看一下验证是否创建成功
kg.query("MATCH (f:Form) RETURN count(f) as formCount")

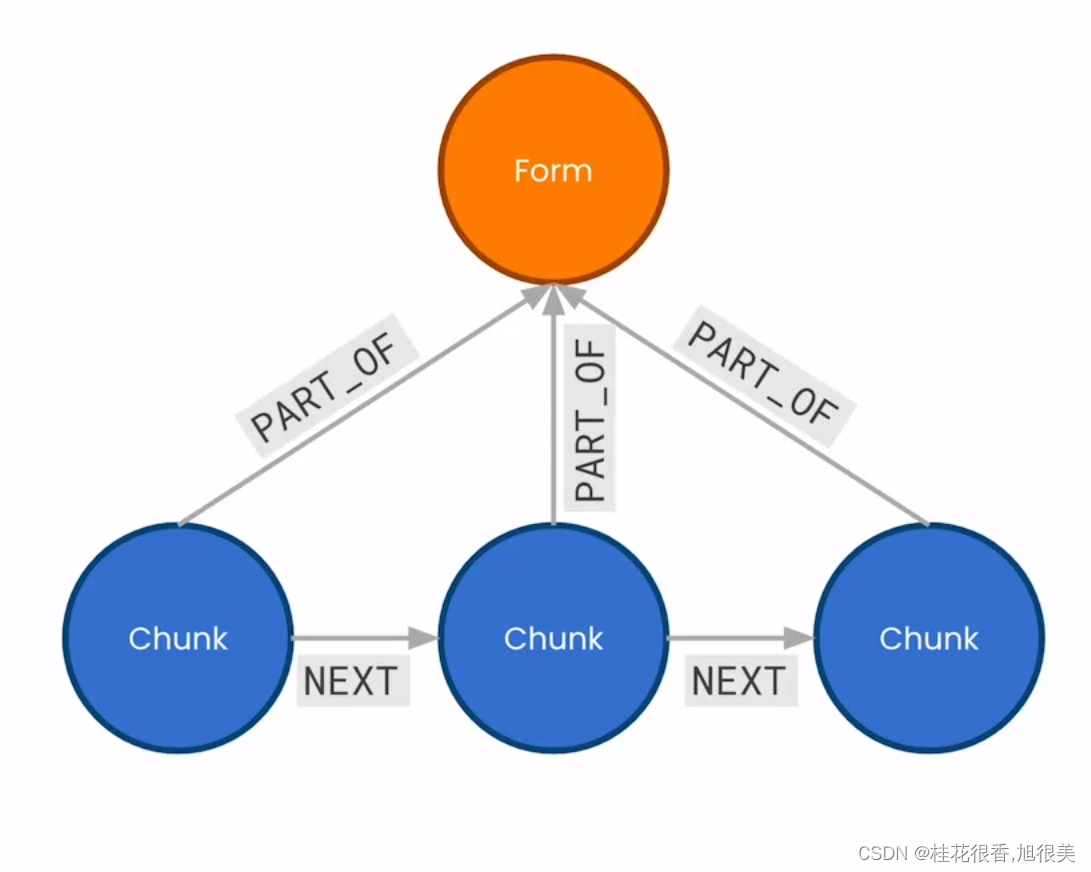
3 为每个部分(section)创建块节点的链接列表
目的是添加关系来改善每个块周围的上下文,把块之间链接起来,最后链接到新创建的表(Form)节点。结果将反应文档的原始结构。
- 从识别同一节中的块开始
# 匹配所有块,它们来自相同的表单ID,并将表单ID作为参数传递
cypher = """
MATCH (from_same_form:Chunk)
WHERE from_same_form.formId = $formIdParam
RETURN from_same_form {.formId, .f10kItem, .chunkId, .chunkSeqId } as chunkInfo
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId']})
匹配到了formId 都等于 form_info['formId'] 的所有块,每个块都有相同的formId和不同的chunkId和不同的chunkSeqId。chunkSeqId 是从0递增的,这确保了所有快都按正确的顺序排列

3.1 按chunkSeqId 排序块
# 在上面的语法上添加了一句: ORDER BY from_same_form.chunkSeqId ASC
#(类似于sql 按id排序)
cypher = """
MATCH (from_same_form:Chunk)
WHERE from_same_form.formId = $formIdParam
RETURN from_same_form {.formId, .f10kItem, .chunkId, .chunkSeqId } as chunkInfo
ORDER BY from_same_form.chunkSeqId ASC
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId']})
看结果来自同一各表(formId 相同),chunkSeqId 是有顺序的,但是有重复,因为我们拿到了同一表单的不同部分的块,之前的查询结果没看到这个情况是因为我i们设置里数量限制(没来得及显示出来)

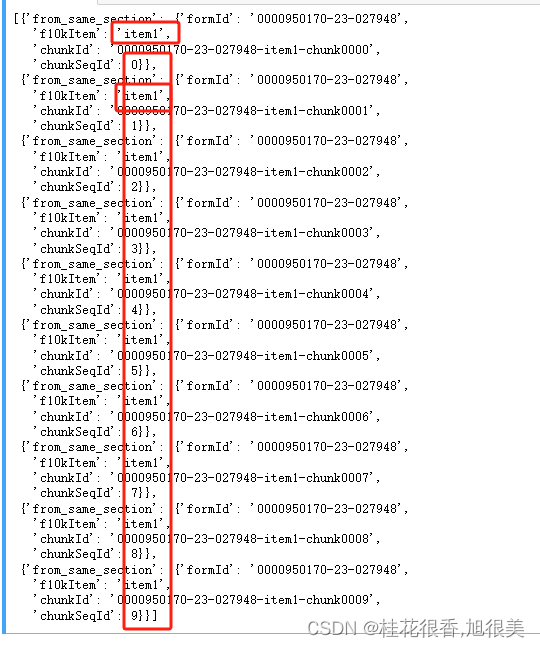
那如果我只想要一个部分的块按chunkSeqId 排序呢,将块限制在“item1”部分,按升序组织
# 添加了第三行的查询参数,添加了 f10kItem
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam // NEW!!!
RETURN from_same_section { .formId, .f10kItem, .chunkId, .chunkSeqId }
ORDER BY from_same_section.chunkSeqId ASC
LIMIT 10
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'})
现在结果来自同一 form 同一 item了,并且按照chunkSeqId 顺序排列起来了
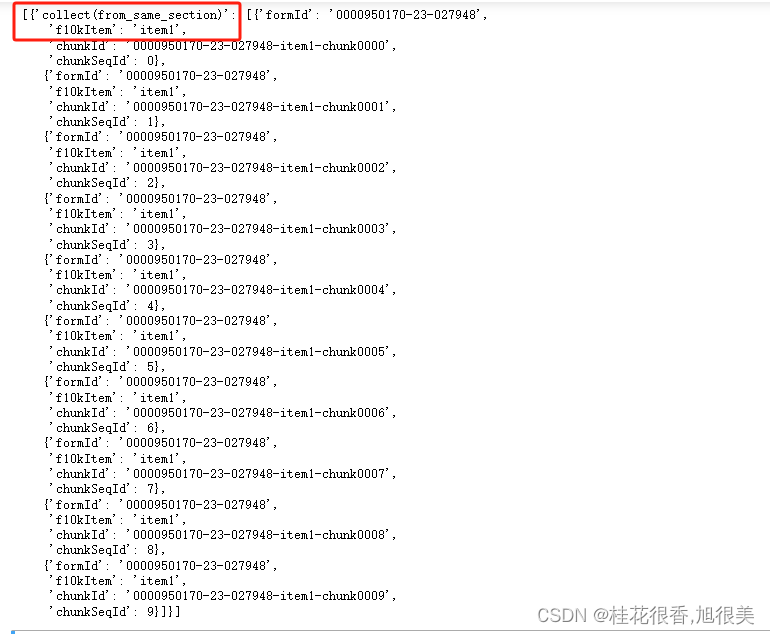
3.2 将这些排好顺序的块收集到列表里面
## cypher 语法里面注释用 //
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section { .formId, .f10kItem, .chunkId, .chunkSeqId }
ORDER BY from_same_section.chunkSeqId ASC
LIMIT 10
RETURN collect(from_same_section) // NEW!!!
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'})
4 在后续块之间添加NEXT关系(增加上下文关系)
- 使用Neo4j中的
apoc.nodes.link函数链接具有NEXT关系的Chunk节点的有序列表,最后会创建一个链接列表 apoc.nodes.link接收参数:一个节点列表;想要设置的关系(这里选择的NEXT);多次创建是否避免重复创建相同当前关系- 这样做只是为了开始“
项目1”部分
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section
ORDER BY from_same_section.chunkSeqId ASC
WITH collect(from_same_section) as section_chunk_list
CALL apoc.nodes.link(
section_chunk_list,
"NEXT",
{avoidDuplicates: true}
) // NEW!!!
RETURN size(section_chunk_list)
"""
kg.query(cypher, params={'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'})
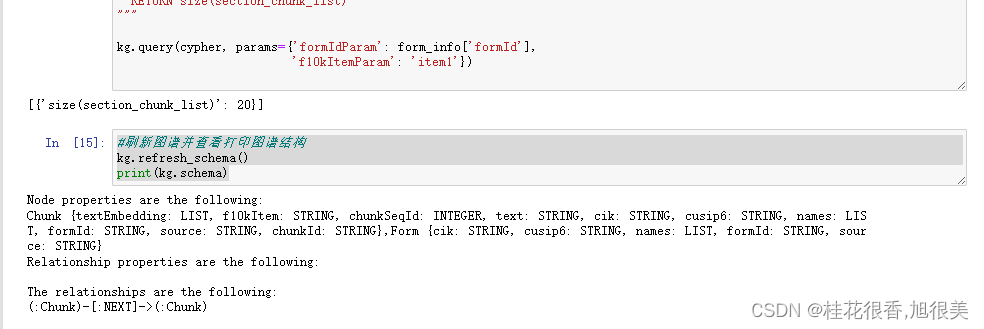
#刷新图谱并查看打印图谱结构
kg.refresh_schema()
print(kg.schema)
可以看到我们有节点信息,然后也有了块与块之间的NEXT 关系(单向)
5 为所有部分创建关系链接
上面已经可以为单个部分(item) 创建一个链接列表,然后可以用一个python循环来处理所有部分。该循环会遍历所有部分并调用查询,将这些不同的部分名称传递给他就可以了
# 由于设置avoidDuplicates(避免重复)为True ,所以再次对item1 操作也不会重复创建NEXT关系列表
cypher = """
MATCH (from_same_section:Chunk)
WHERE from_same_section.formId = $formIdParam
AND from_same_section.f10kItem = $f10kItemParam
WITH from_same_section
ORDER BY from_same_section.chunkSeqId ASC
WITH collect(from_same_section) as section_chunk_list
CALL apoc.nodes.link(
section_chunk_list,
"NEXT",
{avoidDuplicates: true}
)
RETURN size(section_chunk_list)
"""
for form10kItemName in ['item1', 'item1a', 'item7', 'item7a']:
kg.query(cypher, params={'formIdParam':form_info['formId'],
'f10kItemParam': form10kItemName})
6 使用PART_OF关系将块连接到其父Form
匹配一个块和一个表单,其中他们具有相同的formId ,然后在他们之间合并一个新的部分关系
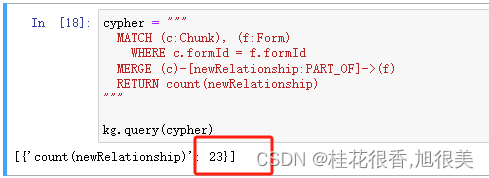
cypher = """
MATCH (c:Chunk), (f:Form)
WHERE c.formId = f.formId
MERGE (c)-[newRelationship:PART_OF]->(f)
RETURN count(newRelationship)
"""
kg.query(cypher)
可以看到创建了23个关系
7 在每个节(Section | item)的第一个块上创建SECTION关系
# 第一个块的chunkSeqId 是 0
# 可以使表单导航到特定的部分的开始(第一个块)
cypher = """
MATCH (first:Chunk), (f:Form)
WHERE first.formId = f.formId
AND first.chunkSeqId = 0
WITH first, f
MERGE (f)-[r:SECTION {f10kItem: first.f10kItem}]->(first)
RETURN count(r)
"""
kg.query(cypher)
我们有四个部分:[‘item1’, ‘item1a’, ‘item7’, ‘item7a’], 所以创建了4个 SECTION关系

8 尝试一些cypher 查询
8.1 匹配 Item 1 section 的 第一个 chunk
# 使用
# 从表单到通过SECTION 关系链接的块的模式
# 匹配 到部分(item)的第一个块
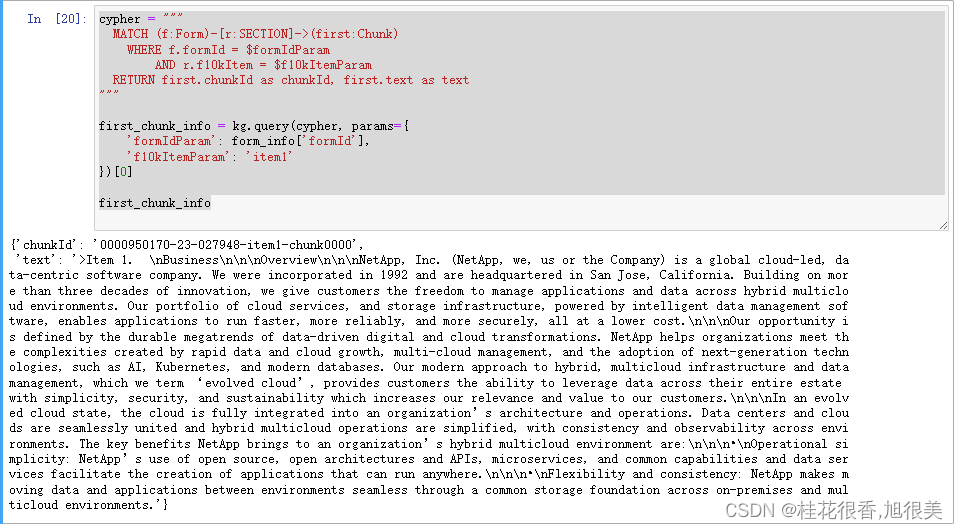
cypher = """
MATCH (f:Form)-[r:SECTION]->(first:Chunk)
WHERE f.formId = $formIdParam
AND r.f10kItem = $f10kItemParam
RETURN first.chunkId as chunkId, first.text as text
"""
first_chunk_info = kg.query(cypher, params={
'formIdParam': form_info['formId'],
'f10kItemParam': 'item1'
})[0]
first_chunk_info
8.2 可以在获取第一个快的情况下使用NEXT关系获取该部分的第二个块
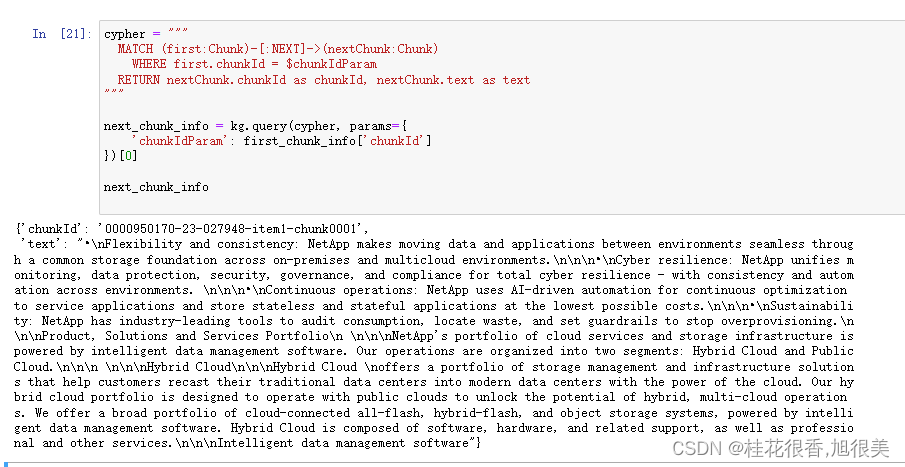
cypher = """
MATCH (first:Chunk)-[:NEXT]->(nextChunk:Chunk)
WHERE first.chunkId = $chunkIdParam
RETURN nextChunk.chunkId as chunkId, nextChunk.text as text
"""
next_chunk_info = kg.query(cypher, params={
'chunkIdParam': first_chunk_info['chunkId']
})[0]
next_chunk_info
 检查下确保有两个链接的块
检查下确保有两个链接的块
print(first_chunk_info['chunkId'], next_chunk_info['chunkId'])

8.3 查询三个连续块的window
可以用NEXT关系和中间的块的chunkId(窗口的中心)
cypher = """
MATCH (c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c2.chunkId = $chunkIdParam
RETURN c1.chunkId, c2.chunkId, c3.chunkId
"""
kg.query(cypher,
params={'chunkIdParam': next_chunk_info['chunkId']})

一旦在图数据中有一个起点,你就可以获取到与之相连的信息。使用RAG ,可以通过语义搜索发现一个节点,现在可以通过图(graph)中的模式匹配(pattern match)为该节点添加上额外的上下文。
9 信息存储在图的结构中
- 图中节点和关系的匹配模式称为路径
- 路径的长度等于路径中关系的数量
- 路径可以被捕获为变量,并在查询的其他地方使用
上面匹配了一个包含三个节点和两个关系的模式,这个东西成为路径,路径是图中清大的特性,比如:在算法中查找两个节点之间的最短路径。
路径的衡量标准是路径中的关系数量.
cypher = """
MATCH window = (c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c1.chunkId = $chunkIdParam
RETURN length(window) as windowPathLength
"""
kg.query(cypher,
params={'chunkIdParam': next_chunk_info['chunkId']})

10 查找可变长度窗口
- 如果图形中不存在关系,则模式匹配将失败
- 例如,一个节中的第一个块没有前面的块,所以下一个查询不会返回任何内容
cypher = """
MATCH window=(c1:Chunk)-[:NEXT]->(c2:Chunk)-[:NEXT]->(c3:Chunk)
WHERE c2.chunkId = $chunkIdParam
RETURN nodes(window) as chunkList
"""
# pull the chunk ID from the first
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})
10.1 修改NEXT关系获取可变长度
cypher = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(c:Chunk)-[:NEXT*0..1]->(:Chunk)
WHERE c.chunkId = $chunkIdParam
RETURN length(window)
"""
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})
NEXT 改成了 NEXT*0..1, *号后面是范围,第一个数字是最小关系数,第二个数字是要匹配的最大关系数。

通过在模式的开头和结尾都使用可变长度,可以匹配链表的边界条件,无论是查看链表中的第一个项目还是链表的末尾。
注意当我们运行查询的时候,实际上有两个模式被匹配。第一个长度为0,第二个长度为1.意味着它在一个关系中有两个节点(注意查询节点是first_chunk_info,类似与正则表达式,与第一个节点长度为0和1的窗口长度被查询出来了)。
获取最长的路径
#
cypher = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(c:Chunk)-[:NEXT*0..1]->(:Chunk)
WHERE c.chunkId = $chunkIdParam
WITH window as longestChunkWindow
ORDER BY length(window) DESC LIMIT 1
RETURN length(longestChunkWindow)
"""
kg.query(cypher,
params={'chunkIdParam': first_chunk_info['chunkId']})
还是按照刚才的模式去匹配,但是要按照他们的长度降序排列所有的路径,然后将其限制仅为一个(降序的第一个就是最长的)

11 使用Cypher自定义相似性搜索的结果
- 扩展矢量存储定义以接受Cypher查询
- Cypher查询获取向量相似性搜索的结果,然后以某种方式对其进行修改
- 从一个简单的查询开始,该查询只返回一些额外的文本和搜索结果
# 一开始的两个变量 node和score来自向量相似度搜索本身
# 我们将其取出,然后只是取一个字面上的字符串,并将它成为 额外文本(extraText)
# 我们将 额外文本与节点文本拼接 返回
# 并返回相似度分数
# 还返回了关于结果节点的元数据
retrieval_query_extra_text = """
WITH node, score, "Andreas knows Cypher. " as extraText
RETURN extraText + "\n" + node.text as text,
score,
node {.source} AS metadata
"""
这是一个Cypher查询的基本模式,扩展了Neo4j向量类的内置向量搜索查询。所以你必须输出一个名为文本的向量,一个名为分数的变量,以及一些名为元数据的东西。但那可以是任何你想要的。
12 设置矢量存储以使用查询(query),然后在LangChain中实例化检索器和问答链
# 新传入一个名为 retrieval_query 参数
# 对于 retrieval_query 我们将传入之前定义的Cypher 查询
# 通过额外的查询来扩展向量搜索
vector_store_extra_text = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_extra_text, # NEW !!!
)
# Create a retriever from the vector store
retriever_extra_text = vector_store_extra_text.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_extra_text = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_extra_text
)
问个问题试一下
chain_extra_text(
{"question": "What topics does Wensong know about?"},
return_only_outputs=True)
{'answer': 'Wensong knows about Manufacturing and Supply Chain, Research and Development, Human Capital, Environmental Disclosure, Diversity, Inclusion, and Belonging, Benefits, Wellbeing, and Engagement.\n',
'sources': 'https://www.sec.gov/Archives/edgar/data/1002047/000095017023027948/0000950170-23-027948-index.htm'}
哈哈,我可不知道供应链,明显在瞎说哈哈哈
- !!!注意,LLM在这里产生幻觉,使用检索到的文本中的信息以及额外的文本。
- 修改提示以尝试获得更准确的答案
chain_extra_text(
{"question": "What single topic does Wensong know about?"},
return_only_outputs=True)
'answer': 'Wensong knows about Manufacturing and Supply Chain.\n',
'sources': 'https://www.sec.gov/Archives/edgar/data/1002047/000095017023027948/0000950170-23-027948-index.htm'}
12.1 做一下其他尝试
- 修改下面的查询以添加您自己的附加文本
- 尝试设计提示以完善您的结果
- 注意,每次更改Cypher查询时,都需要重置向量存储、检索器和链。
# modify the retrieval extra text here then run the entire cell
retrieval_query_extra_text = """
WITH node, score, "Andreas knows Cypher. " as extraText
RETURN extraText + "\n" + node.text as text,
score,
node {.source} AS metadata
"""
vector_store_extra_text = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_extra_text, # NEW !!!
)
# Create a retriever from the vector store
retriever_extra_text = vector_store_extra_text.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_extra_text = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_extra_text
)
13 创建一个使用块窗口查询的链
13.1 首先,创建一个检索单个节点的常规矢量存储
neo4j_vector_store = Neo4jVector.from_existing_graph(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
index_name=VECTOR_INDEX_NAME,
node_label=VECTOR_NODE_LABEL,
text_node_properties=[VECTOR_SOURCE_PROPERTY],
embedding_node_property=VECTOR_EMBEDDING_PROPERTY,
)
# Create a retriever from the vector store
windowless_retriever = neo4j_vector_store.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
windowless_chain = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=windowless_retriever
)
13.2 接下来,定义一个窗口检索查询以获取连续的块
目标是通过相邻块扩展上下文,这可能与提供完成答案相关,为此,请使用块窗口查询,然后从窗口中提取每个块长的文本。最后这些文本将被连接在一起,为LLM提供完整的上下文
retrieval_query_window = """
MATCH window=
(:Chunk)-[:NEXT*0..1]->(node)-[:NEXT*0..1]->(:Chunk)
WITH node, score, window as longestWindow
ORDER BY length(window) DESC LIMIT 1
WITH nodes(longestWindow) as chunkList, node, score
UNWIND chunkList as chunkRows
WITH collect(chunkRows.text) as textList, node, score
RETURN apoc.text.join(textList, " \n ") as text,
score,
node {.source} AS metadata
"""
13.3 设置将使用窗口检索查询的QA链
有了上面的查询语句,我们现在可以创建一个向量存储
注意,当我们创建这个向量存储时,我们将把它作为检索查询传递进去,因此初始向量搜索将被我们的窗口扩展,所有这些都被组合在一起,然后这就是要传递给LLM的上下文
vector_store_window = Neo4jVector.from_existing_index(
embedding=OpenAIEmbeddings(),
url=NEO4J_URI,
username=NEO4J_USERNAME,
password=NEO4J_PASSWORD,
database="neo4j",
index_name=VECTOR_INDEX_NAME,
text_node_property=VECTOR_SOURCE_PROPERTY,
retrieval_query=retrieval_query_window, # NEW!!!
)
# Create a retriever from the vector store
retriever_window = vector_store_window.as_retriever()
# Create a chatbot Question & Answer chain from the retriever
chain_window = RetrievalQAWithSourcesChain.from_chain_type(
ChatOpenAI(temperature=0),
chain_type="stuff",
retriever=retriever_window
)
13.4 对比两个chain
question = "In a single sentence, tell me about Netapp's business."
无窗口chain只会通过向量搜索匹配单个块,然后用它来提供答案
answer = windowless_chain(
{"question": question},
return_only_outputs=True,
)
print(textwrap.fill(answer["answer"]))
answer = chain_window(
{"question": question},
return_only_outputs=True,
)
print(textwrap.fill(answer["answer"]))

两个答案有点相似,但是有一个区别是:通过扩展上下文,它实际上突出了Net App 的Keystone,这是他们的首要产品。所以有上下文的答案更丰富。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









