







r.futures*是未来城市-区域环境模拟(FUTure city - regional Environment Simulation, FUTure)的一个实现,是一个新兴的城乡景观结构的多层次模拟模型。future使用耦合子模型生成景观模式的区域预测,这些子模型集成了土地变化的非平稳驱动因素:人均需求(需求子模型)、场地适宜性(潜在子模型)和转换事件的空间结构(PGA子模型)。
本教程展示了如何准备数据和运行模型。可以下载样例数据集并模拟美国北卡罗来纳州山麓三角地区的城市增长,该地区拥有快速增长的罗利、达勒姆和教堂山等城市。
- 工作流
1)初始步骤及数据准备
首先,我们将设置我们的分析计算区域,以覆盖我们的研究区域,使细胞与我们的一个土地利用栅格对齐:
g.region raster=landuse_2011 -p
我们将从1992年、2001年和2011年的NLCD数据集中提取类别21~24(含义如下图),并将其提取为新的二元地图,其中已发展地区为1,未发展地区为0,空(无数据)为不适合发展的地区(水、湿地、保护区)。

首先,我们将保护区数据从矢量转换为栅格数据,设置NULL值为零(为下一步更简单的栅格代数转换):
v.to.rast input=protected_areas output=protected_areas use=val
r.null map=protected_areas null=0

然后使用栅格运算创建发展/未发展地区的栅格:
r.mapcalc "urban_1992 = if(landuse_1992 >= 21 && landuse_1992 <= 24, 1, if(landuse_1992 == 11 || landuse_1992 >= 90 || protected_areas, null(), 0))" r.mapcalc "urban_2001 = if(landuse_2001 >= 21 && landuse_2001 <= 24, 1, if(landuse_2001 == 11 || landuse_2001 >= 90 || protected_areas, null(), 0))" r.mapcalc "urban_2011 = if(landuse_2011 >= 21 && landuse_2011 <= 24, 1, if(landuse_2011 == 11 || landuse_2011 >= 90 || protected_areas, null(), 0))"



1992,2001,2011的已发展区域(黄色)和未发展区域(紫色)
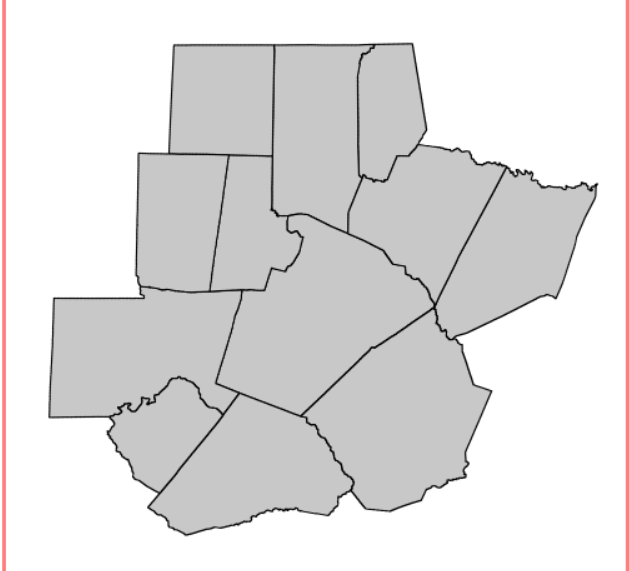
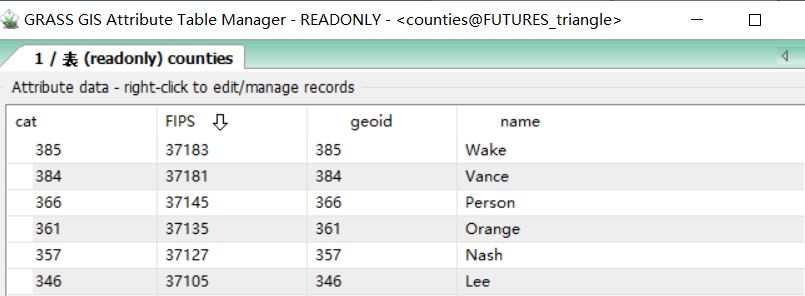
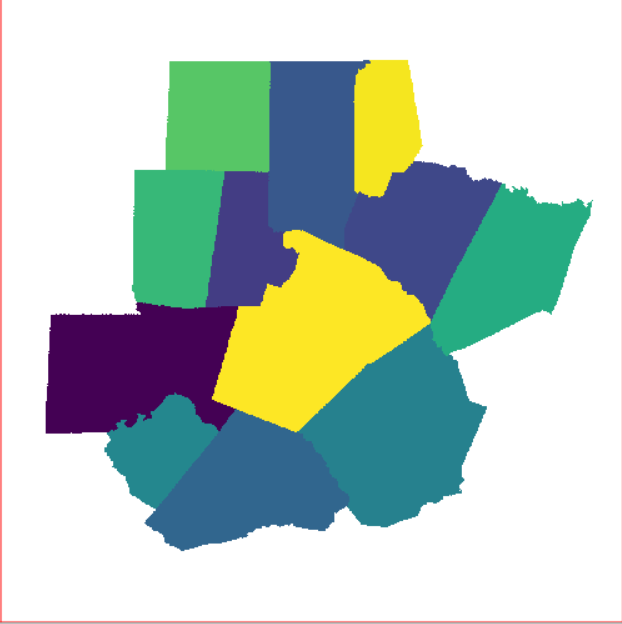
将带有FIPS属性(与人口数据相关)的矢量县界数据转换为栅格数据
FIPS代表联邦信息处理标准。这是一个用来定义美国政治或物理特征的代码。创建它是因为它可以在数据处理中用作唯一标识符。
每个州和县都有FIP。FIPS县代码是5位联邦信息处理标准代码,唯一标识美国的县和县等效物。
前两位是国家代码,后三位是县代码。FIPS 6-4替换为INCITS 31:2009。
v.to.rast input=counties type=area use=attr attribute_column=FIPS output=counties
If we need to run FUTURES only for smaller number of counties, we can extract them based on the identifier:
如果只需要预测少数几个县,我们可以基于FIPS(联邦信息处理标准)代码对它们进行提取,例如:
v.to.rast input=counties type=area where="FIPS in (37183, 37101)" use=attr attribute_column=FIPS output=counties_subset
在进一步的步骤之前,我们将设置工作目录,以便将创建的输入填充文件和文本文件保存在一个目录中,并且易于访问。菜单→设置→grass工作环境→改变工作目录,并将下载的文件population_project.csv和population_trend.csv移到该目录下
2)潜力子模型
模块r.futures 实现潜力子模型,作为FUTURE模型的一部分,潜力是通过一组系数来实现的,这些系数将地点适宜性因素的选择与一个地方被开发的可能性联系起来。这是通过将参数表与那些地点适宜性因子(映射预测因子)的映射结合使用来实现的,系数通过R的lme4软件包进行多级逻辑回归得到,其中系数可能因县而异,利用软件包中的疏浚功能,自动选择最佳模型。
首先,计算几个潜力因子预测器:
1、坡度
我们以30m分辨率dem模型为输入,利用 r.slope.aspect 模块计算改区域的坡度
r.slope.aspect elevation=elevation_30m slope=slope
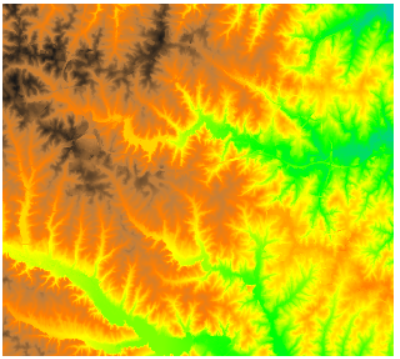
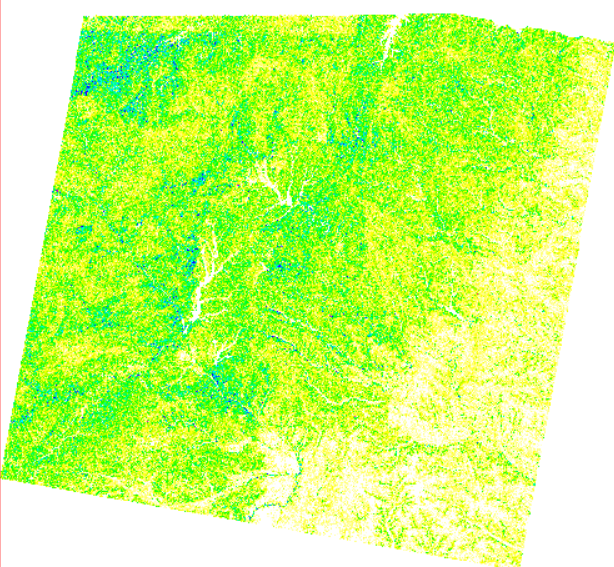
dem数据及坡度计算结果
2、与湖泊、河流的距离
首先,我们将从2011年NLCD数据集中提取类别开放水域
r.mapcalc "water = if(landuse_2011 == 11, 1, null())"
然后利用 r.grow.distance 模块计算到水域的距离,并将颜色表模式设置为蓝色
r.grow.distance input=water distance=dist_to_water r.colors -n map=dist_to_water color=blues

3、与保护区的距离
利用之前创建的保护区栅格文件,利用 r.grow.distance 模块计算与保护区的距离,并设置颜色表为从绿到红
r.null map=protected_areas setnull=0 r.grow.distance input=protected_areas distance=dist_to_protected r.colors map=dist_to_protected color=gyr

4、森林
根据土地利用类型提取森林图斑,并对森林与其他土地利用类型的过渡区域进行平滑(均值平滑),如NLCD category Open Water
r.mapcalc "forest = if(landuse_2011 >= 41 && landuse_2011 <= 43, 1, 0)" r.neighbors -c input=forest output=forest_smooth size=15 method=average r.colors map=forest_smooth color=ndvi

5、前往城市的时间
在这里,我们将计算到城市的旅行时间(>人口20000)作为累计成本距离,其中成本被定义为道路上的旅行时间。首先,我们指定不同类型的道路上的速度,然后复制道路栅格到我们的mapset中,这样我们可以通过添加一个新的属性字段速度来改变它,然后我们根据道路类型分配速度值(km/h):
g.copy vector=roads,myroads
v.db.addcolumn map=myroads columns="speed double precision"
v.db.update map=myroads column=speed value=50 where="MTFCC = 'S1400'"
v.db.update map=myroads column=speed value=100 where="MTFCC IN ('S1100', 'S1200')"
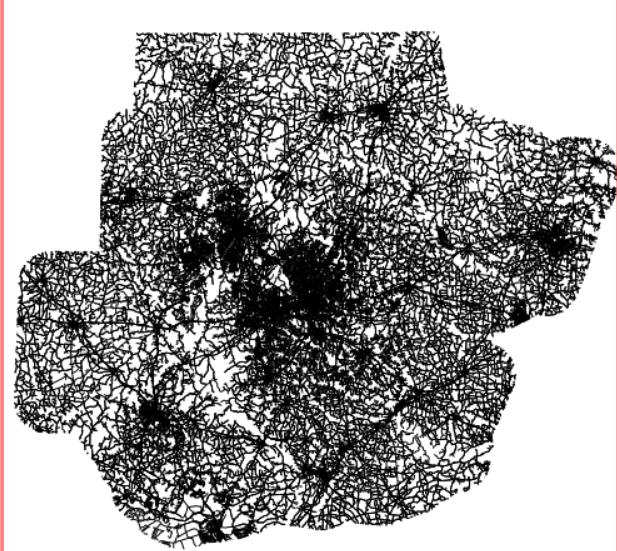
然后,使用属性表中的速度值作为栅格值对所选道路类型进行栅格化
v.to.rast input=myroads type=line where="MTFCC IN ('S1100', 'S1200', 'S1400')" output=roads_speed use=attr attribute_column=speed

我们将该区域的其余部分设置为低速,并重新计算速度,作为在每分钟内通过30m cell的时间:
r.null map=roads_speed null=5 r.mapcalc "roads_travel_time = 1.8 / roads_speed"
最终利用 r.cost 计算到城市的时间分布:
r.cost input=roads_travel_time output=travel_time_cities start_points=cities_20000 r.colors map=travel_time_cities color=byr
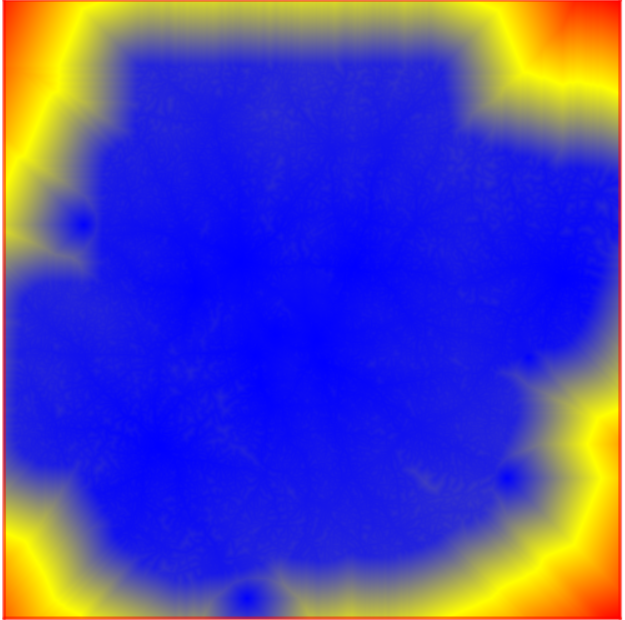
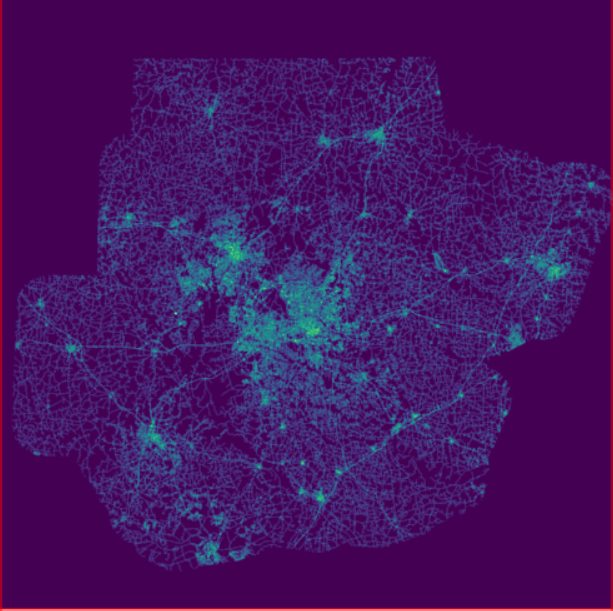
6、路网密度
我们将对道路进行栅格化,并使用移动窗口分析(r.neighbors)来计算道路密度:
v.to.rast input=roads output=roads use=val r.null map=roads null=0 r.neighbors -c input=roads output=road_dens size=25 method=average
7、与道路交叉口的距离
We will consider TIGER roads of type Ramp as interchanges, rasterize them and compute euclidean distance to them:
将TIGER道路数据集中的Ramp类型看作道路交叉点(立交桥),对其栅格化后计算与他们的欧式距离
v.to.rast input=roads type=line where="MTFCC = 'S1630'" output=interchanges use=val r.grow.distance -m input=interchanges distance=dist_interchanges
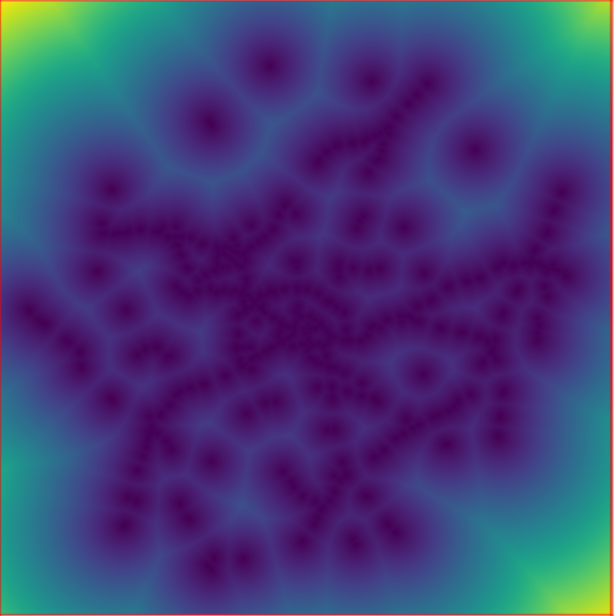
8、发展压力
利用 r.futures.devpressure 模块计算发展压力因子,发展压力是一个基于搜索距离内邻近发达细胞数量的预测因子,并以距离加权。压力因子在整个模型中起到特殊的作用,它允许在在预测的变更和后续步骤的变更之间进行反馈。
r.futures.devpressure -n input=urban_2011 output=devpressure_1 method=gravity size=10 gamma=1 scaling_factor=1 r.futures.devpressure -n input=urban_2011 output=devpressure_0_5 method=gravity size=30 gamma=0.5 scaling_factor=0.1

当gamma值增加时,影响随距离的增加而迅速减小,size的大小是移动窗口大小的一半。当gamma值较低时,当地的发展会影响更远的地方,计算将两组不同的伽玛和大小参数的潜力统计模型。
9、重新调节变量Rescaling variables
通过在GUI的Python选项卡中运行一个简短的Python代码片段来查看我们的预测变量的范围:
for name in ['slope', 'dist_to_water', 'dist_to_protected', 'forest_smooth', 'travel_time_cities', 'road_dens', 'dist_interchanges', 'devpressure_0_5', 'devpressure_1']:
minmax = grass.raster_info(name)
print name, minmax['min'], minmax['max']

对输入变量进行调整,调整为0~100范围
r.mapcalc "dist_to_water_km = dist_to_water / 1000" r.mapcalc "dist_to_protected_km = dist_to_protected / 1000" r.mapcalc "dist_interchanges_km = dist_interchanges / 1000" r.mapcalc "road_dens_perc = road_dens * 100" r.mapcalc "forest_smooth_perc = forest_smooth * 100"
10、采样sample
为了只分析对应的行政区域,我们对图层进行裁剪
r.mapcalc "urban_2011_clip = if(counties, urban_2011)"

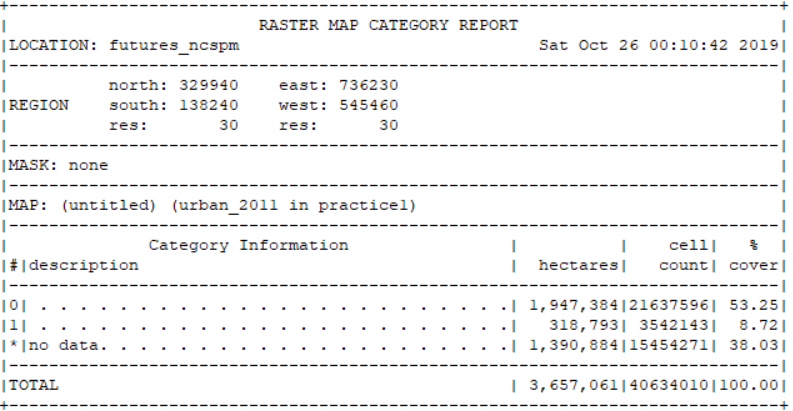
为了估计采样点数量,我们利用 r.report 计算发展/未发展细胞的数量及其比例
r.report map=urban_2011 units=h,c,p
选取未发展地区10000个随机点和已发展地区2000个随机点作为预测因子和响应变量样本
r.sample.category input=urban_2011_clip output=sampling sampled=counties,devpressure_0_5,devpressure_1,slope,road_dens_perc,forest_smooth_perc,dist_to_water_km,dist_to_protected_km,dist_interchanges_km,travel_time_cities npoints=10000,2000
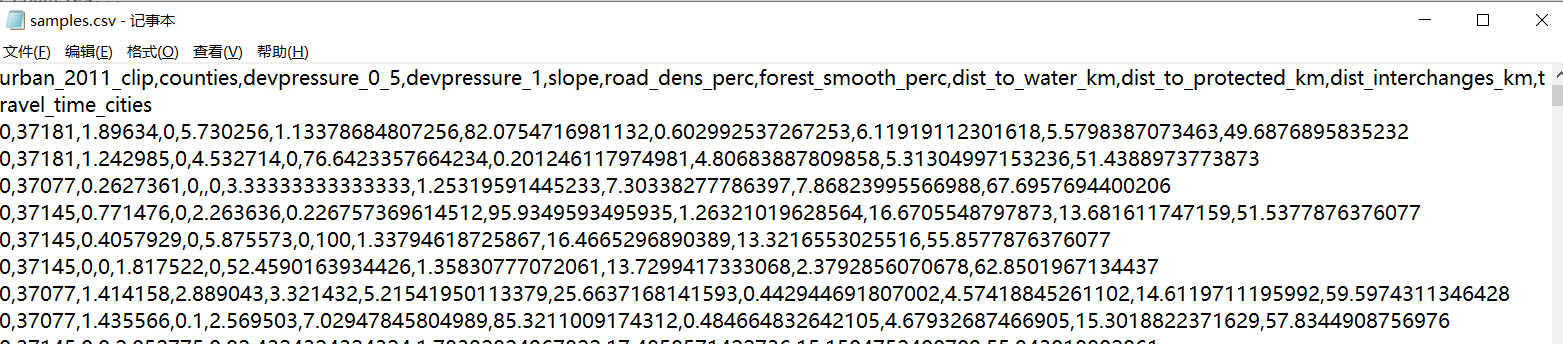
属性表可以导出为CSV文件(不是必要步骤):
v.db.select map=sampling columns=urban_2011_clip,counties,devpressure_0_5,devpressure_1,slope,road_dens_perc,forest_smooth_perc,dist_to_water_km,dist_to_protected_km,dist_interchanges_km,travel_time_cities separator=comma file=samples.csv
11、发展潜力预测
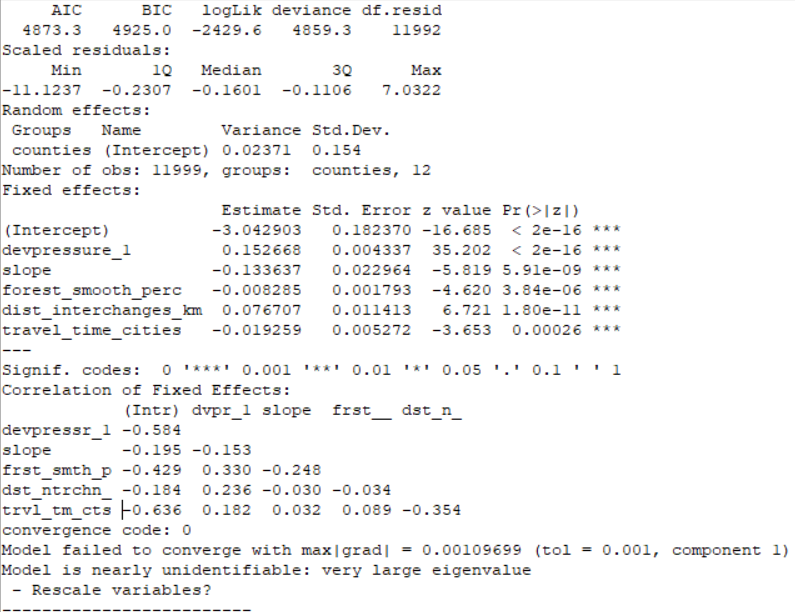
利用 r.futures.potential 进行城市化模型预测,然后利用R 脚本选取最佳模型,我们可以使用不同的预测词组合,例如
r.futures.potential input=sampling output=potential.csv columns=devpressure_1,slope,forest_smooth_perc,dist_interchanges_km,travel_time_cities developed_column=urban_2011_clip subregions_column=counties --o
3)需求子模型
首先,我们将对道路进行遮罩,使其不影响人均土地需求关系。
v.to.rast input=roads type=line output=roads_mask use=val r.mask roads_mask -i //加上掩膜会产生栅格压缩编码的问题(待解决)
用 r.futures.demand 模块来推导人口与发展的关系,这种关系可以是线性/对数/对数平方/指数/指数方法,在手册中可以寻找不同关系的例子
- linear: y = A + Bx
- logarithmic: y = A + Bln(x)
- logarithmic2: y = A + B * ln(x - C) (requires SciPy)
- exponential: y = Ae^(BX)
- exp_approach: y = (1 - e^(-A(x - B))) + C (requires SciPy)
手册中描述了输入填充CSV文件的格式,重要的是要同步子区域的类别和CSV文件的列标头(在我们的例子中是FIPS编号),如何简单地生成年表(需求计算)在r.future .demand手册中有描述,例如在Python控制台运行:
','.join([str(i) for i in range(2011, 2036)])
然后我们可以创建DEMAND文件
r.futures.demand development=urban_1992,urban_2001,urban_2011 subregions=counties observed_population=population_trend.csv projected_population=population_projection.csv simulation_times=2011,2012,2013,2014,2015,2016,2017,2018,2019,2020,2021,2022,2023,2024,2025,2026,2027,2028,2029,2030,2031,2032,2033,2034,2035 plot=plot_demand.pdf demand=demand.csv separator=comma
然后可以在工作环境中看到plot_demand.png 和 demand.csv文件
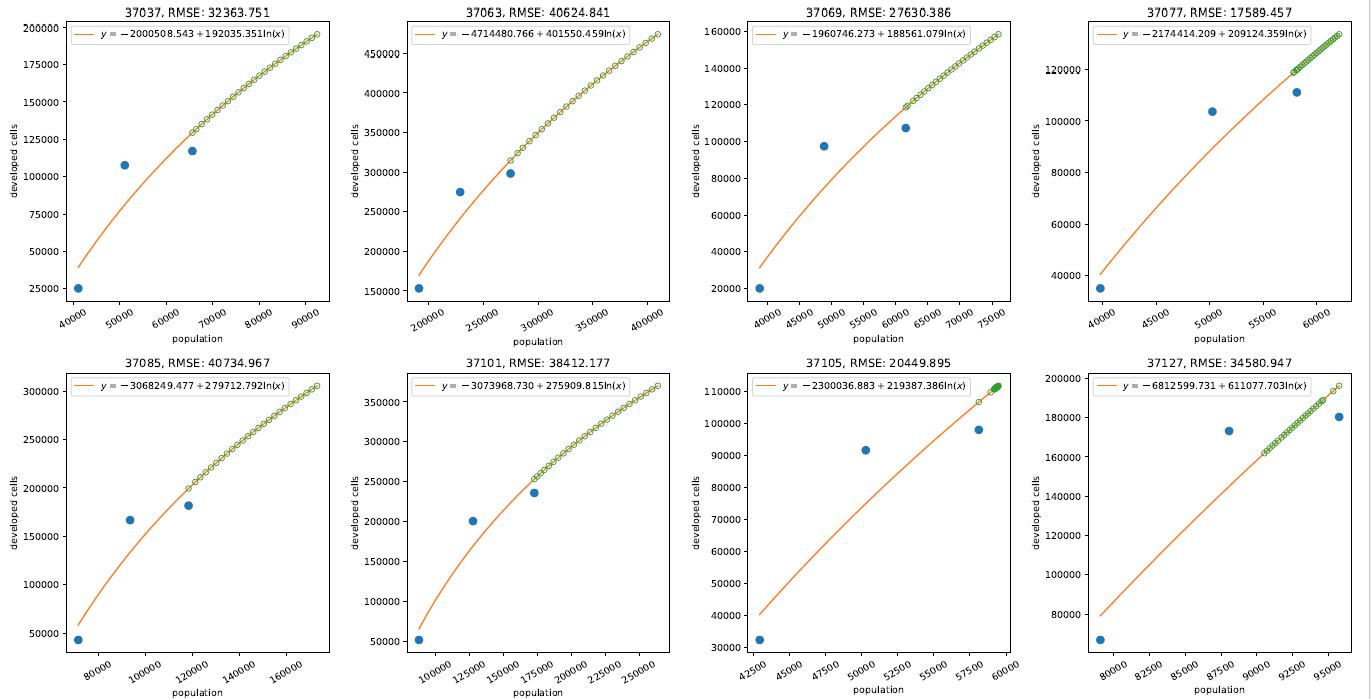
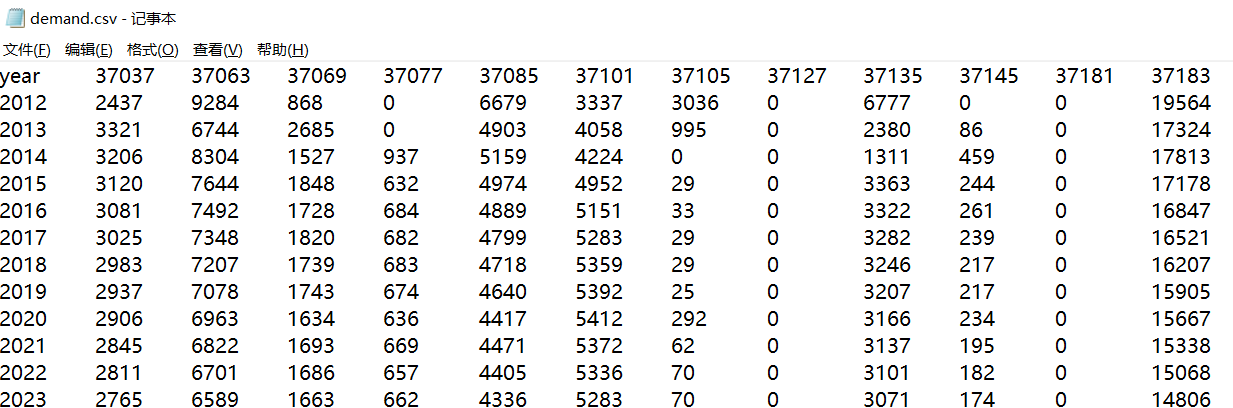
4)图斑校准
图斑校准是一个非常耗时的计算,首先,通过比较历史和最新的发展,我们得出新发展的图斑,我们可以在整个区域运行这个程序,并且只保留最小尺寸为2个单元格的图斑(1800 = 2 x 30 x 30 m)。
r.futures.calib development_start=urban_1992 development_end=urban_2011 subregions=counties patch_sizes=patches.txt patch_threshold=1800 -l
然后会得到一个patch.txt文件(稍后在PGA中使用),一个补丁大小分布文件,包含所有找到的补丁的大小。

此时,我们开始校准以获得最佳的图斑形状参数(对于本教程,可以跳过这一步,使用建议的参数)。
首先,我们只选择一个县
5)FUTURES 模型模拟
将切换回之前的区域:
g.region raster=landuse_2011 -p
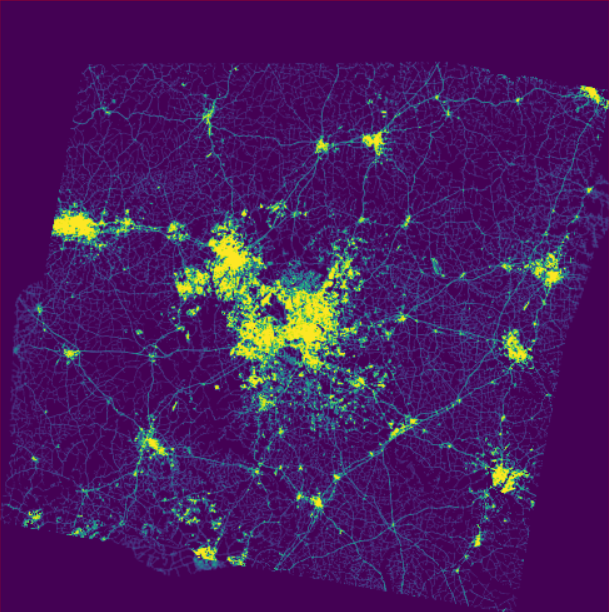
现在已经有了 r.futures.pga 模型所必须的输入数据,可以运行模拟:
r.futures.pga subregions=counties developed=urban_2011 predictors=slope,forest_smooth_perc,dist_interchanges_km,travel_time_cities devpot_params=potential.csv development_pressure=devpressure_1 n_dev_neighbourhood=10 development_pressure_approach=gravity gamma=1 scaling_factor=1 demand=demand.csv discount_factor=0.3 compactness_mean=0.2 compactness_range=0.1 patch_sizes=patches.txt num_neighbors=4 seed_search=2 random_seed=1 output=final output_series=final
最终的预测结果如下:
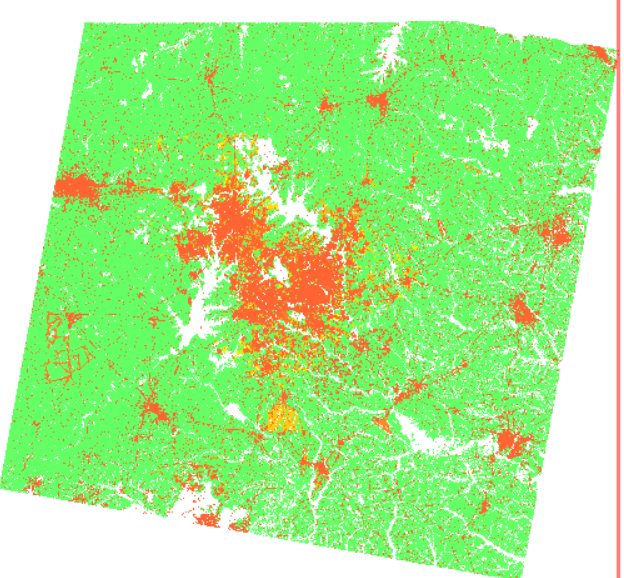
6)不同情景的模拟
利用incentive_power参数可以探索涉及到鼓励填充(infill)和蔓延(sprawl)的政策的模拟情况
默认值是1,可以将其更改为0.25到4之间的数字,以测试城市蔓延(sprawl)/填充(infill)场景,较高的权重导致填充(infill)行为,较低的权重导致城市蔓延(sprawl)。
参考链接: https://grasswiki.osgeo.org/wiki/FUTURES_tutorial















 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









