






局部空间自相关
import esda
import numpy as np
import pandas as pd
import libpysal as lps
import geopandas as gpd
import contextily as ctx
import matplotlib.pyplot as plt
from geopandas import GeoDataFrame
from shapely.geometry import Point
from pylab import figure, scatter, show
from splot.esda import moran_scatterplot
from esda.moran import Moran_Local
from splot.esda import plot_moran
from splot.esda import lisa_cluster
from splot.esda import plot_local_autocorrelation
%matplotlib inline
root_dir="/home/lighthouse/Learning/pysal/"
gdf = gpd.read_file(root_dir+'data/.shp') # 读取数据
数据概况
gdf.columns.values #字段名
array(['CODE', 'COUNT', 'SUM_AREA', 'FIRST_ANAM', 'OID_', 'CODE_1',
'DATAFLAG', 'TOTPOP', 'TOTPOP_10K', 'RURPOP_10K', 'TOWNPOP_10',
'AGRPRODUCT', 'AGRLBR_10K', 'AGRSTOTGDP', 'FSTGDPRATE',
'SCNDGDPRAT', 'THRDGDPRAT', 'Province', 'geometry'], dtype=object)
gdf.head(1)
计算局部空间自相关LISA
- 第一产业占GDP比重
FSTGDPRATE为变量
ax=gdf.plot(figsize=(8,8),column="FSTGDPRATE",scheme='Quantiles', k=5, cmap='GnBu', legend=True,)
ax.set_axis_off()

计算空间权重矩阵
- pysal中的局部自相关计算中,要求权重矩阵的每一个元素都有邻接元素
y = gdf['FSTGDPRATE'].values
w = lps.weights.distance.Kernel.from_dataframe(gdf, fixed=False, k=15)
w.transform = 'r'
- Local Moral 计算
moran_loc = Moran_Local(y, w)
- Local Moral 散点图
fig, ax = moran_scatterplot(moran_loc, p=0.05)
ax.set_xlabel('FSTGDPRATE')
ax.set_ylabel('Spatial Lag of FSTGDPRATE')
plt.show()
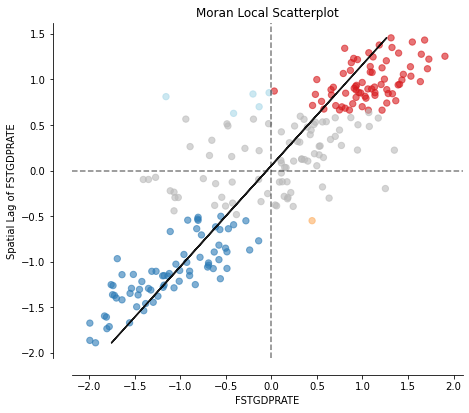
- 聚集区的空间分布
lisa_cluster(moran_loc, gdf, p=0.05, figsize = (9,9))
plt.show()
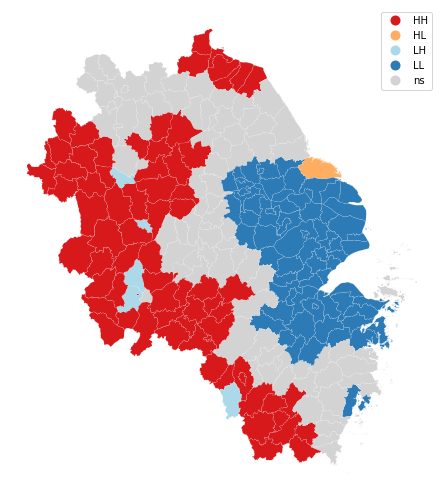
-
根据上图结果可以看出,图中西部为高值聚集区,东部为低值聚集区。高值聚集区的第一产业产值占比比较高,而低值聚集区的第一产业产值占比比较低,这可以反映出区域的经济发展水平的空间异质性,区域发展不均衡。
-
绘制结果组合图
plot_local_autocorrelation(moran_loc, gdf, 'FSTGDPRATE')
plt.show()
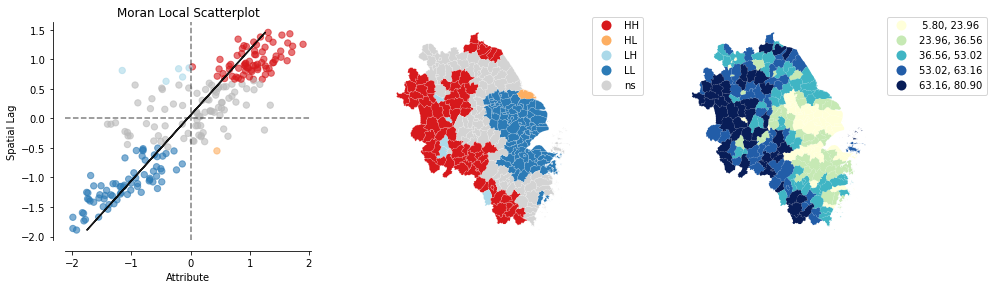














 14万+
14万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









