






Stable Diffusion
在介绍ComfyUI之前,我们先认识Stable Diffusion。Stable Diffusion是一款免费、开源的图像生成工具,自2022年8月推出以来便受到了广泛关注,到2024年2月Stable Diffusion3早期预览版发布,在图片质量,多主题提示和单词拼写等方面有巨大提升。相较于最大同类竞品Midjourney而言,它具备免费开源、本地部署、灵活可定制、风格多样、社团活跃等优势。其更高的生图上限和功能定制使得它收到越来越多的关注和更高端的应用。
Stable Diffusion主要有两种使用方式WebUI和ComfyUI。
WebUI
WebUI是基于浏览器的图形用户界面,通过固定的格式运行Stable Diffusion模型。
ComfyUI
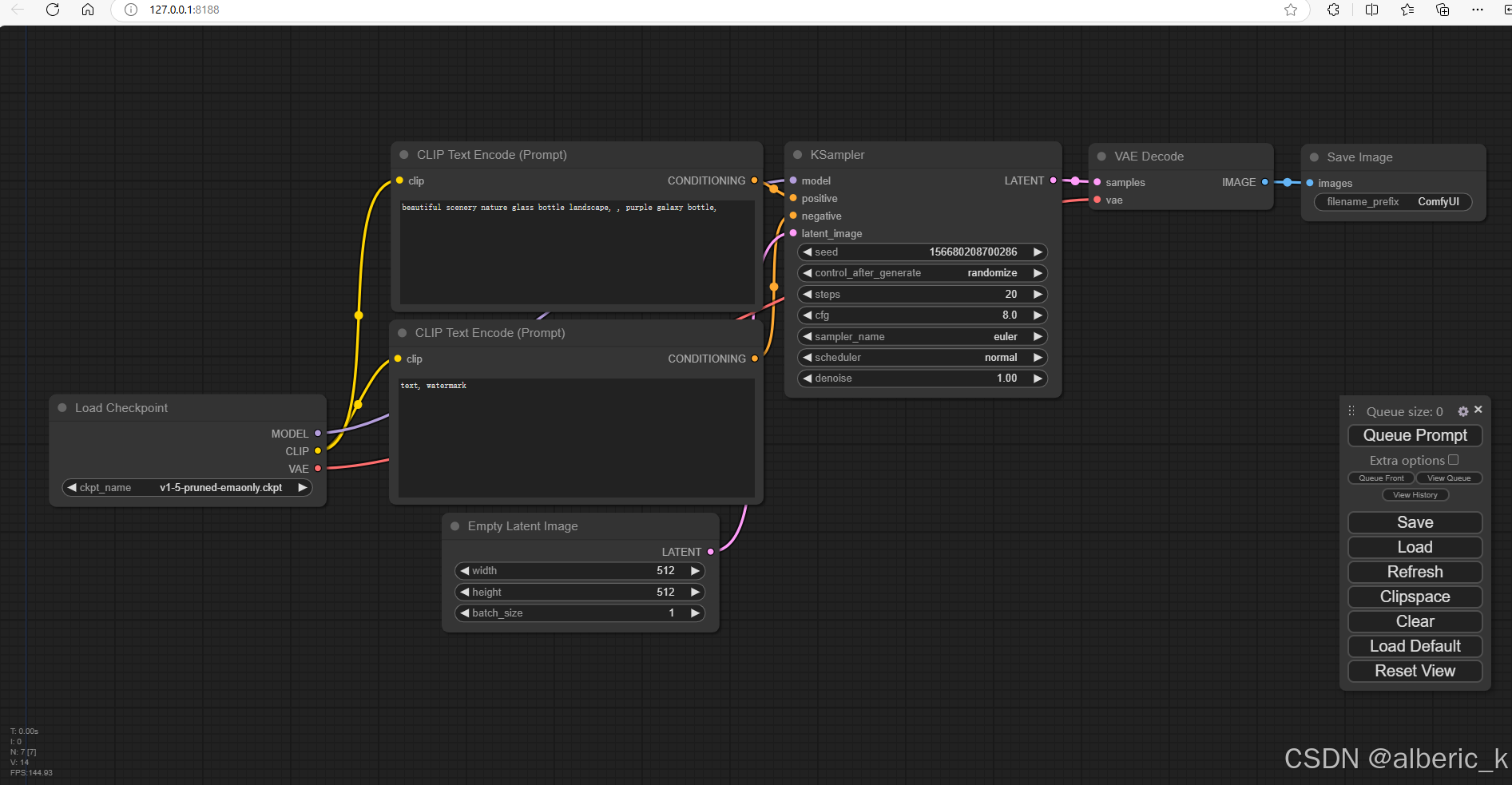
ComfyUI是一个基于节点式工作流的Stable Diffusion用户界面工具。区别于WebUI的固定操作模式,ComfyUI将图像生成流程拆解为不同的节点,每个节点执行特定的操作,节点之间通过输入和输出相互连接。
其主要功能有:
- 模型加载与选择: 有专门的节点用于加载 Stable Diffusion 基础模型,不同的基础模型擅长生成不同事物或风格的图片,用户可以根据自己的需求选择合适的模型。
- 文本编码: 将用户输入的文本提示词转换为模型可理解的向量编码。相同于WebUI界面,ComfyUI总有正向提示词和反向提示词的文本编码器,编码后的内容会作为采样器的采样条件,以指导图像的生成。
- 采样处理: 核心采样器节点实现Stable Diffusion模型的反向扩散过程。从一张完全噪音图开始,通过不断采样逐步去除噪音,最终生成图片。采样过程中有多个参数可调节,如采样步数、CFG 尺度、采样器类型、去噪幅度等。
- 图像解码与输出: 经过采样生成的图片数据是一种特殊的压缩格式(潜空间图像),需要通过图像解码器(VAE 解码)将其转换为真正的图片格式。
ComfyUI下载
方式1 官网下载
github链接:https://github.com/comfyanonymous/ComfyUl
网盘链接:https://pan.quark.cn/s/38b5dc2e9026
方式2 秋叶大佬版本
发布地址:https://www.bilibili.com/video/BV1Ew411776J/
网盘链接:https://pan.quark.cn/s/95e50b580752

相较于官方版本,这里内置了一些模型和插件。
ComfyUI安装
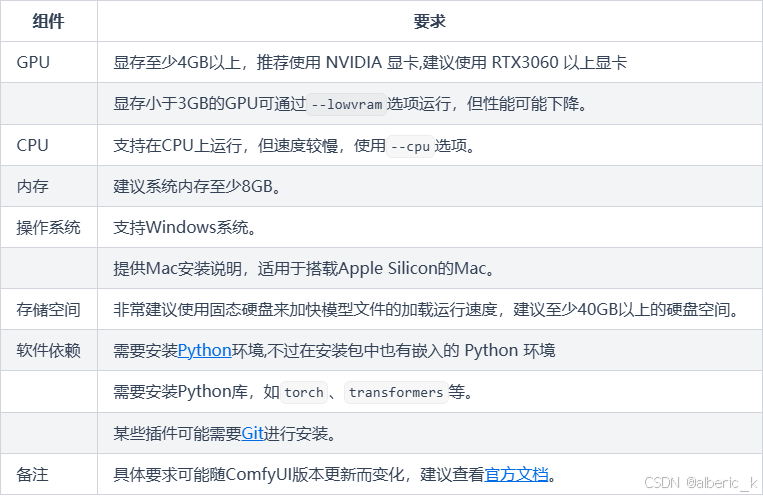
配置要求
安装方式
无论是方式1还是方式2都是免安装解压即用。
方式1

方式2

没有问题的话,到这里就可以学习使用了!

















 990
990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









