







Spark系列文章:
大数据 - Spark系列《一》- 从Hadoop到Spark:大数据计算引擎的演进-CSDN博客
大数据 - Spark系列《二》- 关于Spark在Idea中的一些常用配置-CSDN博客
大数据 - Spark系列《三》- 加载各种数据源创建RDD-CSDN博客
大数据 - Spark系列《四》- Spark分布式运行原理-CSDN博客
大数据 - Spark系列《五》- Spark常用算子-CSDN博客
大数据 - Spark系列《六》- RDD详解-CSDN博客
大数据 - Spark系列《七》- 分区器详解-CSDN博客
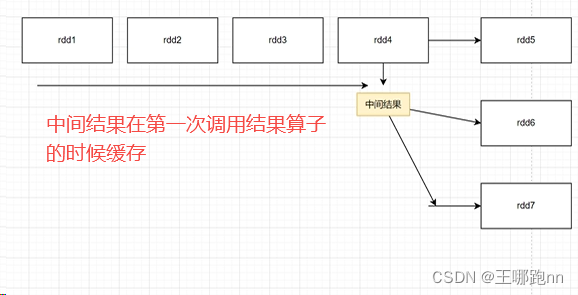
10.1 RDD缓存的概念理解
如果一个RDD是由多个RDD计算来的 ,且后续的使用多次
rdd1->rdd2->rdd3->rdd4 -->rdd4结果缓存 重复使用
-
- - - - -> rdd4.map
-
- - - - -> rdd4.flatmap
-
- - - - -> rdd4.groupBy
缓存不会破坏rdd之间的依赖关系,所以缓存的数据丢失后不会影响计算结果,通过血源关系重新追溯计算
10.2 RDD缓存API
1. persist
rdd2.persist(StorageLevel.MEMORY_AND_DISK) // 可以自己控制存储级别
// NONE 相当于没有存储
// DISK_ONLY 缓存到磁盘
// DISK_ONLY_2 缓存到磁盘,2个副本
// MEMORY_ONLY 缓存到内存
// MEMORY_ONLY_2 缓存到内存,2个副本
// MEMORY_ONLY_SER 缓存到内存,以序列化格式
// MEMORY_ONLY_SER_2 缓存到内存,以序列化格式,2个副本
// MEMORY_AND_DISK 缓存到内存和磁盘
// MEMORY_AND_DISK_2 缓存到内存和磁盘,2个副本
// MEMORY_AND_DISK_SER 缓存到内存和磁盘,以序列化格式
// MEMORY_AND_DISK_SER_2 缓存到内存和磁盘,以序列化格式,2个副本
// OFF_HEAP 缓存到堆外内存
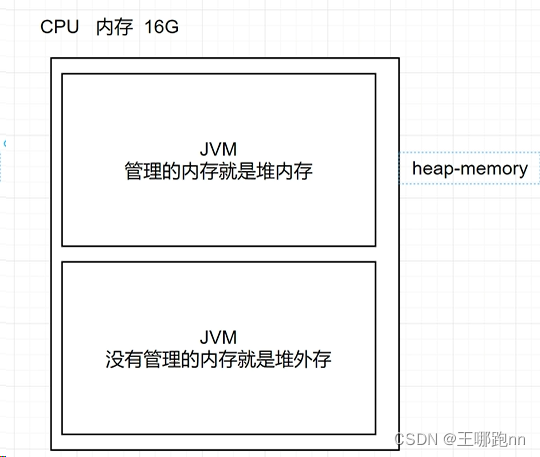
🍠堆内存和堆外存
-
堆内存:
-
概念:堆内存是指在计算机内存中由操作系统动态分配给程序的一块内存区域,用于存储程序运行时创建的对象和数据结构。
-
特点:堆内存是动态分配的,大小不固定,可根据程序需要动态扩展和收缩。在堆内存中分配的内存空间由垃圾回收器负责管理,当对象不再被程序引用时,垃圾回收器会自动回收这些对象所占用的内存空间,以便其他对象使用。
-
使用场景:堆内存通常用于存储程序运行时动态创建的对象和数据结构,如Java中的对象实例等。
-
-
堆外存:
-
概念:堆外存是指数据存储在计算机内存之外的存储介质上,如硬盘、SSD等,也称为外部存储。
-
特点:堆外存的存储空间通常比堆内存大得多,但访问速度相对较慢。堆外存的数据持久性较高,即使程序结束或计算机断电,数据仍然能够被保留。在大数据处理中,通常会将数据存储在堆外存储介质上,以应对数据量大、持久性要求高的情况。
-
使用场景:堆外存通常用于存储大规模数据集,如文件、数据库等,以及需要长期保存和持久化的数据。
-
2. unpersist
如果需要清除已经缓存的RDD数据,可以调用 rdd.unpersist() 方法;
3. 🥙cache
cache( )就是调用的 persist(StorageLevel.MEMORY_ONLY)
//数据:logs.txt
ERROR: Unable to connect to database
ERROR: File not found
WARNING: Disk space is running low
INFO: Server started successfully
INFO: User login successful
ERROR: Connection timeout
WARNING: Network connection unstable
INFO: Data processing completed
INFO: Task execution started
INFO: Application terminated
WARNING: System temperature is high
ERROR: Out of memory error
INFO: File uploaded successfully
INFO: Database backup completed
ERROR: Server crashed unexpectedlypackage com.doit.day0219
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.storage.StorageLevel
import org.apache.log4j.{Level, Logger}
/**
* @日期: 2024/2/19
* @Author: Wang NaPao
* @Blog: https://blog.csdn.net/weixin_40968325?spm=1018.2226.3001.5343
* @Tips: 和我一起学习吧
* @Description:
*/
object Test01 {
def main(args: Array[String]): Unit = {
// 创建SparkConf对象,并设置应用程序名称和运行模式
val conf = new SparkConf()
.setAppName("LogAnalysis") // 设置应用程序名称
.setMaster("local[*]") // 设置运行模式为本地模式
Logger.getLogger("org.apache.spark").setLevel(Level.WARN)
// 创建SparkContext对象,并传入SparkConf对象
val sc = new SparkContext(conf)
val rdd1 = sc.textFile("data/logs.txt")
val rdd2 = rdd1.map(line => {
val arr: Array[String] = line.split(": ")
(arr(0), 1)
})
val rdd3 = rdd2.groupByKey()
val rdd4 = rdd3.map(e => {
println("rdd4的逻辑执行"+e._1)
(e._1, e._2.size)
})
// rdd4.cache() // 将rdd4的结果缓存起来 内存中
//cache( )就是调用的 persist(StorageLevel.MEMORY_ONLY)
rdd4.persist(StorageLevel.MEMORY_ONLY)
/*
rdd4.persist() // 内存中
rdd4.persist(StorageLevel.DISK_ONLY)
rdd4.persist(StorageLevel.MEMORY_ONLY) // 堆内内存 数据对象的方式管理
rdd4.persist(StorageLevel.DISK_ONLY_3) // 副本
rdd4.persist(StorageLevel.MEMORY_ONLY_2) // 副本
rdd4.persist(StorageLevel.MEMORY_AND_DISK) // 副本
// 开启堆外内存 缓存数据
rdd4.persist(StorageLevel.OFF_HEAP) // 堆外
*/
// 保留rdd之间的依赖 , 所以缓存的数据丢失不会影响最后的计算结果
// 通过rdd的依赖关系恢复
println("--------------------------------")
rdd4.filter(_._1=="ERROR").foreach(e=>{println("ERROR 数量为"+e._2)})
rdd4.filter(_._1=="WARNING").foreach(e=>{println("WARNING 数量为"+e._2)})
rdd4.filter(_._1=="INFO").foreach(e=>{println("INFO 数量为"+e._2)})
sc.stop()
}
} 















 1290
1290











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









