







啥是卷积神经网络(三)( GoogLeNet详解)
故事的起因
这里为什么直接就介绍 GoogLeNet网络结构,而不是介绍更早地一点的AlexNet、VGG等结构呢?主要原因就是一个叫做 1x1 卷积核的机制。这个1x1 卷积方式就是GoogLeNet首次提出来的,在我的‘啥是卷积神经网络(一)’中对1x1卷积核进行了详细的介绍。怕到时候忘记,就先来记录一下GoogLeNet v2网络的学习笔记。至于v2、v3啥的后面再说。
故事的经过
废话不多说,先来一张图片压压惊。

有没有一种感觉,看完这个图片之后更吃惊了。不要慌,你看到这个图之后可能会更懵。

这两个图片中除了基础的卷积、池化、激活等步骤外,多了两个新鲜的名字,一个叫做Inception,另一个叫做辅助分类器。在仔细看你会发现,咦,末尾咋就一个全连接层。这些正是GoogLeNet网络中的亮点。使用官方的语言表述就是(来自哔站):
1. 引入了Inception结构(融合不同尺度的特征信息);
2. 添加了两个辅助分类器帮助训练;
3. 使用1x1卷积核对数据进行降维以及映射处理;
4. 丢弃全连接层,使用平均池化代替,大大的减少了模型的参数量。
由于这个网络结构有点长,我把他进行分块讲解。具体分为:
输入、Inception(3a)、Inception(3b)、Inception(4a)、Inception(4b)、Inception(4c)、Inception(4d)、Inception(4e)、Inception(5a)、Inception(5b)、输出。下面根据这个分块,进行详细的讲解。
0. 输入
为了方便观看,我们把它按照分块进行截取,下面就是输入部分网络参数结构图。需要注意一点的是,图表中**#3x3 reduce’和‘#5x5 reduce’表示3x3和5x5卷积之前1x1的卷积核的个数。**

根据上图中的网络结构和参数表,绘制输入部分的流程机制,如图所示。

图中灰色方块表示卷积核。原始输入图像为224x224x3,且都进行了零均值化的预处理操作(图像每个像素减去均值)。下面是文字版的解释:
- 使用7x7的卷积核(滑动步长2,padding为3),64通道,卷积后进行ReLU操作,输出为112x112x64;
- 经过3x3的max pooling(步长为2),输出为((112 - 3+1)/2)+1=56,输出为56x56x64;
- 进行局部响应归一化(LRN);
- 使用64个1x1的卷积核(滑动步长为1),64通道,卷积后进行ReLU操作,输出为56x56x64x64,
- 使用192个3x3的卷积核(滑动步长为1,padding为1),64通道,卷积后进行ReLU操作,输出为56x56x64x192;
- 进行局部响应归一化(LRN);
- 经过3x3的max pooling(步长为2),输出为((56 - 3+1)/2)+1=28,即28x28x64x192。
这个图详细的描述了输入部分都干了啥。这里出现了一个新的名词——局部响应归一化(Local Response Normalization,LRN),它在Alexnet模型中首次提出来的,后面会对它进行解释说明,现在就需要知道它是个类似于激活函数的东西就可以了,作用是对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
1. Inception(3a、b)
这里就要先说说这个Inception结构了。
Inception 结构的主要思路是用密集成分来近似最优的局部稀疏结构。是不是读起来很拗口,我们先来看一张图。

这是作者先提出来的基本结构,这里先叫它基础版。和我们熟知的卷积不同,基础版Inception采用了多通道卷积的方式,用理工男的直观解释就是,一般的卷积核之间相当于电路中的串联,而Inception结构相当于并联电路。(是不是很形象,哈哈哈)。那它这样做有什么好处呢?
听听作者的心里话:一般来说,提升网络性能最直接的办法就是增加网络深度和宽度,这也就意味着更巨量的参数。但是,巨量参数容易产生过拟合,也会大大增加计算量。文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。
具体来说:Inception使用3个不同大小的卷积核对输入图片进行卷积操作,并附加最大池化,将这4个操作的输出沿着通道这一维度进行拼接,构成的输出特征图将会包含经过不同大小的卷积核提取出来的特征。
也就是说,Inception模块采用多通路(multi-path)的设计形式,每个支路使用不同大小的卷积核,最终输出特征图的通道数是每个支路输出通道数的总和。
但是这有一个致命的弱点,就是这将会导致输出通道数变得很大,尤其是使用多个Inception模块串联操作的时候,模型参数量会变得非常巨大。因此,出现了Inception的升级版,它的结构如下图所示。

在原有的结构上进行改造,在每个3x3和5x5的卷积层之前,增加1x1的卷积层来控制输出通道数;在最大池化层后面增加1x1卷积层减小输出通道数。这就是1x1卷积核的作用,至于原理嘛,请看>>>‘啥是卷积神经网络(一)’
口说无凭,接下来举个Inception(3a)的例子来看看传统卷积、Inception基础版和Inception升级版卷积核参数到底相差多少:

- 使用传统的3x3卷积来实现卷积操作,则需要192x3x3x256=442368个卷积核参数;
- 使用基础版Inception模块需要:
(1x1x192x64)+(3x3x192x128)+(5x5x192x32)=276480个卷积核参数,也就是传统3x3卷积核参数的一半。 - 使用升级版Inception模块需要:
(1×1×192×64)+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32)=157184个卷积核参数,也就是将近传统3x3卷积核参数的三分之一。
由此可见,这个升级版Inception确实是可以使用较少的参数增加网络性能,到这里如果还是不懂的话,可以看下面这个图。

这个图很清晰的描述了Inception(3a)的工作机制,这里补充两个知识点:
4. 最大池化后,为什么尺寸没变?
答:因为其池化的步长为1,且进行了Padding操作。在TensorFlow中用padding='SAME’表示填充。这里给大家补上一个池化输出尺寸计算的公式,方便大家计算。
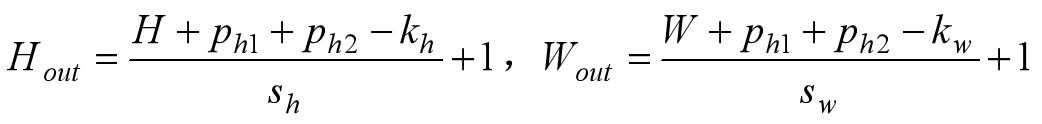
第一行之前填充ph1行,最后一行后面填充ph2行。在第一列之前填充pw1列,在最后一列之后填充pw2列,用sh和sw表示步长,kh和kw表示卷积核尺寸。带进去算一下:Hout=(28+1+1-3)/1+1=28。
5. 最后特征图输出深度256是哪里来的?
答:在完成各部分卷积后,对这几个结果进行拼接,就是连在一起,具体就是:
(64+128+32+32)=256,因此输出特征图大小为28x28x256。
Inception(3b)结构和Inception(3a)唯一的差别就是卷积核的数量。

按照上面的方式进行计算,最后得到的数据大小为28x28x480,可见,这个特征图的深度又增加了。看下图>>>

2. Inception(4a、b、c、d、e)
这个是 Inception(4)是这个结构里最精彩的桥段,把它分为两个部分 Inception(4a、c、d);另一部分是 Inception(4b、e)。为啥不按照顺序分呢?因为 Inception(4a、c、d)这部分结构和 Inception(3a、b)结构一样,不一样的就是卷积核数量,所以介绍起来简单;而 Inception(4b、e)增加了一个辅助分类器。介绍起来相对来说比较麻烦。
2.1 Inception(4a、c、d)
这三个部分结构一样,怕你忘,看图

原理和Inception(3)一样一样的,这里通过图片来说明一下其参数计算和原理。
首先是 Inception(4a),看图


然后是Inception(4c),接着看图


最后是Inception(4d),来看图


好了,第一部分完事了,接下来是第二部分。
2.2 Inception(4b、e)
这里多了一个辅助分类器的东西,先看看它的截图,红框的地方就是。

这个结构看着还挺简单的,它有什么用呢?直观来说,它就相当于卷积神经网络中的最后几层。它在训练阶段出现是为了避免网络过深引起的浅层梯度消失问题,GoogLeNet在中间层的Inception module加入了两个辅助分类器(softmax),训练时在进行梯度下降求导的时候,将辅助分类器的损失函数(cost function)乘以x倍的权重加到总的损失函数上,这样可以有效避免梯度消失的问题。做预测的时候就和这两个玩意没啥关系了。也就是说,这个玩意相当于一个正则化项,在防止梯度消失的同时,增加网络的分类性能。
接下来我们看看Inception(4b、e)工作流程。
首先是Inception(4b),看图


这里辅助分类器中1x1卷积核数量设为x(主要是我不知道多少,还不敢瞎写)。
然后是Inception(4e),接着看图。


3. Inception(5a、b)
说到这里,其实Inception结构就没啥了。就是各个部分的参数计算。
先是Inception(5a),来吧,继续看图吧


然后接着看Inception(5b)


故事的结局
故事的结局经历了以下几个步骤
- 通过一个7x7的平均池化,得到1x1x1024形状的特征数据;
- 采用Dropout函数,丢弃40%的数据;
- 通过全连接将特征数据变成线性1x1000形状;
- 使用Softmax激活函数对数据进行激活。
- OK!完事!















 587
587











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









