







最近被抖音的各种神奇特效折服的不行不行的,于是准备自己写一个简单的小特效,下面开始进入正题:
首先我们要知道特效要实现的功能。
本人毕竟第一次弄,就选择一个简单的特效------戴帽子
框架搭建思路:
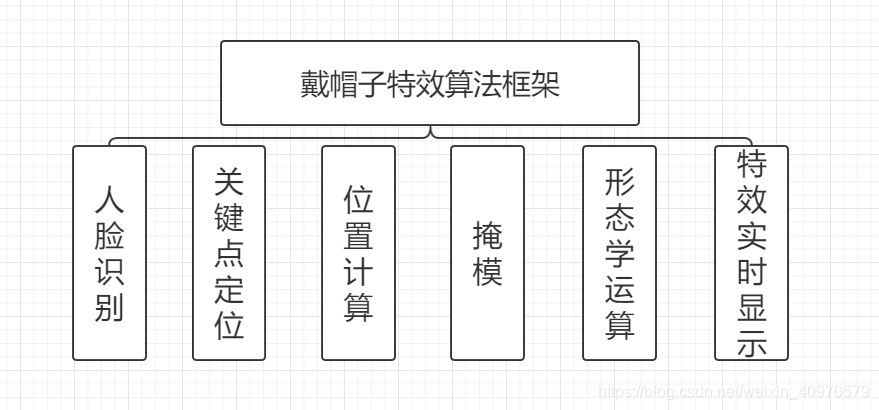
人脸识别
这里的人脸识别采用开源库OpenCV中的haarcascade_frontalface_default.xml文件进行检测,这个文件在OpenCV官网上或者GitHub上就可以下载,这里挂个网址:
https://github.com/opencv/opencv/tree/master/data/haarcascades
需要下载哪个文件,点进去,右键单击Raw即可下载。
经后期实践证明,这个方法并不太好,对于侧脸和遮挡不能很好的检测出人脸。
这里做一个简单的例子对文件的使用进行说明:
import cv2
import numpy as np
# 调用文件
face = cv2.CascadeClassifier("./haarcascade_frontalface_default.xml")
# 打开摄像头,
cap = cv2.VideoCapture(0)
while True:
# ret 返回布尔值,frame表示每帧图像
ret, frame = cap.read()
# 灰度转换
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
face_detection = face.detectMultiScale(gray, 1.1, 5)
if len(face_detection) > 0:
for faceRect in face_detection:
# 左上角坐标和长宽
x, y, w, h = faceRect
# 绘制边框矩形,线宽为2
cv2.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 0), 2)
cv2.imshow("face", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
运行上述示例,就可以看到自己帅气、美丽的脸庞被框起来了(虽然效果不太好)。这里我们需要的参数有x, y, w, h ,也就是边框左上角坐标和边框矩形的长和宽。
人脸关键点定位
这里采用深度学习对人脸关键点进行定位,环境配置:
win10+OPENCV4+TensorFlow(CPU)1.8
具体操作可参照:
基于OpenCV和tensorflow的人脸关键点检测
手把手教你做人脸识别和关键点检测(基于tensorflow和opencv)
我的深度学习训练和测试代码是根据上述两篇博客进行修改的,数据集采用
Facial Keypoints Detection数据集,这个网上下载有点麻烦,需要注册啥的,如果需要的话可以私信我,或者发我邮箱: machine_vision0876@163.com 。数据集如下图所示:
下面进入正题:神经网络结构采用三层神经网络,两层全连接,池化方式为最大值,激活函数为Relu,Dropout为0.7。经过150次左右的迭代,loss趋于稳定,大约为1.12。下面将附上训练代码,代码大部分是上面提到的博客提供的代码,做了略微的改动以适应版本配置需求。
import matplotlib.pyplot as plt
import os
import tensorflow as tf
import pandas as pd
import numpy as np
def input_data(train=True):
# 获取训练集和测试集
file_name = train_csv if train else test_csv
df = pd.read_csv(file_name)
cols = df.columns[:-1]
df = df.dropna() # 丢弃有缺失数据的样本
df['Image'] = df['Image'].apply(
lambda img: np.fromstring(img, sep=' ') / 255.0) # 归一化输入的数据
X = np.vstack(df['Image'])
X = X.reshape((-1, 96, 96, 1))
if train:
y = df[cols].values / 96.0 # 将坐标缩放到0,1区间,加速收敛
else:
y = None
print(df.describe())
return X, y
train_csv = './data/facial-keypoint-detection/training.csv'
test_csv = './data/facial-keypoint-detection/test.csv'
valid_size = 100 # 验证集大小
train_epoches = 300 # 循环训练次数
batch_size = 64 # mini-batch的大小
learning_rate = 0.001 # 学习率
def weights_variable(shape, namew='w'):
# 初始化权重
initial = tf.truncated_normal(shape=shape, stddev=0.1)
return tf.Variable(initial, name=namew)
def biases_variable(shape, nameb='b'):
# 初始化偏置
initial  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1863
1863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









