







文章目录
数据模型
数据模型(Data Models)包括模仿真实世界的实体联系模型(Entity Relational Model)与数据库使用的记录模型(Record Relational Model)
数据库操作
创建数据库
// 创建
CREATE DATABASE dbname
// 删除
DROP DATABASE dbname
创建数据表
// 创建
CREATE TABLE tblname(表字段说明)
// 删除
DROP TABLE tblname
创建副本
CREATE TABLE 表2 SELECT * FROM 表1
用数据表副本恢复数据表
INSERT INTO 表1 SELECT * FROM 表2
数据列操作
// 增加
ALTER TABLE tblname ADD newcolname coltype coloptions
// 修改
ALTER TABLE tblname CHANGE oldcloname newcolname coltype coloptions
// 删除
ALTER TABLE tblname DROP colname
操作语句
查
字段选择查询
单一/多字段选择(SELECT…FROM…)
// 普通查询
SELECT 查询字段(全部:*,多个:逗号分隔) FROM 表名
相同数据合并选择(SELECT DISTINCT…FROM…)
// 查询并删除重复数据
SELECT DISTINCT 字段名 FROM 表名
所有数据选择(SELECT ALL…FROM…)
// 查询且不允许删除重复数据
SELECT ALL 字段名 FROM 表名
限制查询数据记录个数(SELECT…FROM…LIMIT num)
用于分页查询
SELECT 字段名 FROM 表明 limit 查询条数
// 再查几条
SELECT 字段名 FROM 表明 limit 起始条数,查询条数
// 查询没有limit返回的条数,需要sql_calc_found_rows和found_rows配合使用
SELECT sql_calc_found_rows address FROM youplus_test.med_order limit 2;
SELECT found_rows();
字段计算选择(SELECT…AS…FROM…)
// 输出字段进行计算
SELECT balance*1.5 AS newbalance FROM 表名
条件选择
单一条件选择(WHERE…)
// 单条件查询
SELECT 字段 FROM 表名 WHERE 字段='指定值'
多重条件选择(WHERE…AND…)
// 多条件查询AND连接
SELECT 字段 FROM 表名 WHERE 字段1='指定值1' AND 字段2>'指定值2'
范围条件选择(WHERE…between…AND…)
// 范围条件查询
SELECT 字段 FROM 表名 WHERE 字段 between 100 AND 300
SELECT 字段 FROM 表名 WHERE 字段 between amount <= 300 AND amount >= 300
多个关联表关联选择
多个表关联查询
// 多个表关联查询
SELECT 表1.字段,表2.字段 FROM 表1,表2 WHERE 表1.字段=表2.字段
重命名
SELECT 字段1 as 别名1,字段2 as 别名2 FROM 表1,表2 WHERE 表1.字段=表2.字段
元组变量
// 元组变量
SELECT DISTINCT T.字段, S.字段 FROM 表1 AS T,表2 AS S WHERE T.字段>S.字段
模糊/模板替换(LIKE)
匹配整个列
// 字符串替换
%:字符串的模糊替换,匹配任意多个字符 'downtown'='down%'
_:字符的模糊替换,匹配任意单个字符 'downtown'='down_own'
SELECT field FROM tblname WHERE field LIKE '%rryr%'
// 查询结果为字段值等于‘小白’的数据
SELECT field FROM tblname WHERE field LIKE '小白'
like查询较大的数据表往往非常慢,因为需要读取和分析数据表里的全部数据记录,还无法用索引来优化。
一般用全文搜索查询来替换
正则匹配(REGEXP)
在列值内进行匹配,匹配到之后,相应的行会返回
规则为正常正则
// 查询结果为字段值包含‘小白’的数据
SELECT field FROM tblname WHERE field REGEXP '小白'
排序操作(ORDER BY)
// 排序
// ASC:升序,DESC:降序
SELECT 字段 FROM 表名 WHERE 字段='指定值' ORDER BY 字段 ASC/DESC
// 多个排序条件,先按照主序排,再按照次序排
SELECT 字段 FROM 表名 WHERE 字段='指定值' ORDER BY 字段1 ASC, 字段2 DESC
集合运算
并集(UNION / UNION ALL)
// 并集
// UNION:过滤重复,UNION ALL:不过滤重复
(SELECT 字段 FROM 表1) UNION (SELECT 字段 FROM 表2)
(SELECT 字段 FROM 表1) UNION ALL (SELECT 字段 FROM 表2)
交集(INTERSECT)
// 交集,不一定能用,看具体数据库,可能未纳为保留字段,使用下面的嵌套子查询
(SELECT 字段 FROM 表1) INTERSECT (SELECT 字段 FROM 表2)
SELECT 字段 FROM 表1 WHERE 字段 IN (SELECT 字段 FROM 表2)
差集(MINUS)
// 差集,不一定能用,看具体数据库,可能未纳为保留字段,使用下面的嵌套子查询
(SELECT 字段 FROM 表1) MINUS (SELECT 字段 FROM 表2)
SELECT 字段 FROM 表1 WHERE 字段 NOT IN (SELECT 字段 FROM 表2)
聚合函数
平均值(AVG)
// 平均值
SELECT AVG(字段) AS avg_字段 FROM 表
总和值(SUM)
// 总和值
SELECT SUM(字段) AS total_字段 FROM 表
分组(GROUP BY)
// 分组
SELECT 字段1,SUM(字段2) AS total_字段2 FROM 表 GROUP BY 字段1
// 设置分组条件,先分组,再判断
SELECT 字段1,SUM(字段2) AS total_字段2 FROM 表 GROUP BY 字段1 HAVING SUM(字段2)>200
// 在查询结果的最后一行自动增加一条总数统计记录
SELECT 字段1,count(*) FROM 表 GROUP BY 字段1 WITH ROLLUP
计数(COUNT)
// 计数
SELECT COUNT(字段) AS count_字段 FROM 表
最大值(MAX)
SELECT MAX(字段) AS max_字段 FROM 表
最小值(MIN)
SELECT MIN(字段) AS min_字段 FROM 表
SELECT 字段 FROM 表名 WHERE 字段=MIN('指定值')
嵌套子查询
在主查询语句中另设置子查询语句
// 嵌套子查询
SELECT 字段 FROM 表名 WHERE 字段=(SELECT MAX(字段) FROM 表名)
比较设置 SOME(部分比较)、ALL(全部比较)
// 比较设置 SOME(部分比较)、ALL(全部比较)
SELECT 字段 FROM 表名 WHERE 字段>SOME(SELECT 字段 FROM 表名)
SELECT 字段 FROM 表名 WHERE 字段>ALL(SELECT 字段 FROM 表名 WHERE 字段='指定值')
增
INSERT INTO 表名 VALUES (字段, 值)
改
UPDATE 表 SET 字段='指定值' WHERE 字段='指定值'
删
// 删除整个表
DELETE FROM 表
// 删除数据
DELETE FROM 表 WHERE 字段='指定值'
// 可结合查询语句的where使用
DELETE FROM 表 WHERE 字段 between 100 and 300
DELETE FROM 表 WHERE amount <(SELECT avg(amount) FROM 表)
视图
每当一个sql运行完毕,均会产生一个结果集,可以为其命名,以这种方式创建的数据表便称为“视图”
创建视图
// 视图关联
// 创建视图
CREATE VIEW 视图名 AS SELECT 表1.字段,表2.字段 FROM 表1 INNER JOIN 表2 ON 表1.字段=表2.字段
// 视图查询
SELECT * FROM 视图名
连接操作
连接多个数据表执行特定功能
一般连接(Join)
两个数据表中至少有一个属性字段名称相同时,才可将这两个数据表连接。
一般连接指字段完全连接,即使是同名称的连接字段也要重复列出
内连接(inner Join)
相同字段的元组内容完全相同
CREATE VIEW 视图名 AS SELECT * FROM 表1 inner join 表2 ON 表1.字段=表2.字段
左外连接 (Left Outer Join)
相同字段的元组内容不完全相同,当左端有数据而右端无数据时,以Null表示右端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 left outer join 表2 ON 表1.字段=表2.字段
右外连接 (Right Outer Join)
相同字段的元组内容不完全相同,当右端有数据而左端无数据时,以Null表示左端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 right outer join 表2 ON 表1.字段=表2.字段
完全连接 (Full Outer Join);
相同字段的元组内容不完全相同,当左端有数据而右端无数据时,以Null表示右端不存在的元组内容,当右端有数据而左端无数据时,以Null表示左端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 full outer join 表2 ON 表1.字段=表2.字段
自然连接(Natural Join)
不将同名称的连接字段重复列出
后者包括自然内连接 (Natural Inner Join)
CREATE VIEW 视图名 AS SELECT * FROM 表1 natural inner join 表2 ON 表1.字段=表2.字段
自然左外连接 (Natural Left Outer Join)
同名称的连接字段不得重复列出,当左端有数据而右端无数据时,以Null表示右端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 natural left outer join 表2 ON 表1.字段=表2.字段
自然右外连接 (Natural Right Outer Join)
同名称的连接字段不得重复列出,当右端有数据而左端无数据时,以Null表示左端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 natural right outer join 表2 ON 表1.字段=表2.字段
自然完全连接 (Natural Full Join)
同名称的连接字段不得重复列出,当左端有数据而右端无数据时,以Null表示右端不存在的元组内容,当右端有数据而左端无数据时,以Null表示左端不存在的元组内容
CREATE VIEW 视图名 AS SELECT * FROM 表1 natural full outer join 表2 ON 表1.字段=表2.字段
字符串操作
合并字符串
SELECT concat(filed1,' ',filed2) FROM tblname
截取字符串
// 1:起始字符,10:截取个数
// 1为第一个字符
SELECT substr(filed,1,10) FROM tblname
// 前10字符
SELECT left(filed,10) FROM tblname
// 后10字符
SELECT right(filed,10) FROM tblname
返回字符位置
SELECT locate(filed, column) FROM tblname
字符长度
SELECT char_length(filed) FROM tblname
IF判断
// IF(a,b,c),a为判断条件,b为符合判断,c为不符合判断
// 改变字符输出
SELECT if(char_length(code)>10,concat(left(code,5),'...',right(code,5)),code) FROM tblname
批量替换
UPDATE tblname SET column = replace(column, field1, field2)
日期和时间
// 区间查询
select count(*) from tblname where create_time between '2023/01/01 00:00:00' and '2024/01/01 00:00:00'
// 分组查询,查询2023每月的量
select count(*), month(create_time) as m from tblname where year(create_time)=2023 group by m
// date_format/time_format,格式化
select count(*), date_format(create_time, '2023-%m') as y_m from youplus_test.med_order group by y_m
// 加一个时间/日期间隔 ADDDATE()、DATE_ADD()
select adddate('2023-12-21 6:00', interval 3 minute) // 2023-12-21 06:03:00
// 减一个时间/日期间隔 SUBDATE()、DATE_SUB()
select subdate('2023-12-21 6:00', interval 3 minute) // 2023-12-21 05:57:00
// 两个时间/日期 间隔 SUBTIME()、DATEDIFF()返回天数、TIMEDIFF()
select datediff('2023-12-21 6:00', '2023-12-19 9:00') // 2
select timediff('2023-12-21 6:00', '2023-12-19 9:00') // 45:00:00
// TIME_TO_SEC()转为秒,SEC_TI_TIME()转回时间
select sec_to_time(60) // 00:01:00
实体关系模型(E-R Data Model)
由实体集(Entity Sets)、属性字段与关系集(Relationship Sets)3个部分组成
实体集(Entity Sets)
实体:一组具有一定结构形态的数据
实体集:同类型实体的集合
属性字段
实体结构项目的描述
关系集(Relationship Sets)
实体与实体间的联系称为关系
同类型的关系的集合称为关系集

约束
对于E-R模型的一些约束定义,使其在某些环境下的数据类型符合该环境约束的要求
创建/增加约束
ALTER TABLE tblname ADD FOREIGN KEY [idxname] (column1) REFERNCES table2 (column2)
映射约束
实体与实体间对应连接的要求,即实体与实体间关系集的定义
一对一(One to One):A中任一实体最多可连接B中的一个实体
一对多(One to Many)
多对多(Many to Many)
多对一(Many to One)
参与约束
各实体间连接的程度
完全参与:每一个实体至少与其他任一实体连接
部分参与:有一些实体未能与其他实体创建连接
索引键
作为识别实体的依据
索引文件
一种技术:专门来直接找到所需记录或找到该记录所属的组
在排序索引、哈希索引方法设计上,应考虑如下因素:
查找类型 (Access Types): 考虑查找效率 (Efficiency),查找类型包括找到某记录 (Record)或找到该记录所属的组 (Group)。应兼顾时间 (Time) 与空间 (Space) 的代价
查找时间 (Access Time): 考康查找时间,在最短时间内找到某记录
添加记录时间 (Insertion Time): 添加记录所需要的时间,包括查找适当空间与调整索引结构
删除记录时间 (Deletion Time): 删除记录所需要的时间,包括查找需要被删除的记录与调整索引结构
溢出空间 (Space Overhead):当设置溢出空间时,应考虑付出空间的代价
创建/删除索引(CREATE/DROP INDEX)
// 创建三种方式
CREATE TABLE 表名(字段1 ...,字段2 ...,PRIMARY KEY id, INDEX idxtitle(title))
CREATE INDEX idxtitle ON title(title)
ALTER TABLE titles ADD INDEX idxtitle(title)
ALTER TABLE tblname ADD PRIMARY KEY (indexcols ...)
ALTER TABLE tblname ADD UNIQUE [indexname] (indexcols ...)
ALTER TABLE tblname ADD FULLTEXT [indexname] (indexcols ...)
// 删除
ALTER TABLE tblname DROP PRIMARY KEY
ALTER TABLE tblname DROP INDEX indexname
ALTER TABLE tblname DROP FOREIGN KEY indexname
排序索引(Ordered Indices)
将索引排序,指定查找方向,提高查找效率
顺序查找:一个接一个地查找
二分法查找(Binary Search):先排序,再二分查找
直接查找:在顺序文件内创建索引区,直接索引查找
索引区
包含索引指针,指向文件对应记录的查找键,分为主键(Primary Indices)、次索引(Secondary Indices)、紧密索引(Dense Indices)、稀疏索引(Sparse Indices)
主键(Primary Indices):索引区内的索引与文件记录的查找键相同
次索引(Secondary Indices):索引区内的索引与文件记录的查找键不相同,指向其他的字段
紧密索引(Dense Indices):索引区内的每一个索引对应每一个文件记录的查找键
稀疏索引(Sparse Indices):索引区内的一个索引对应n个文件记录的查找键
多层索引(Multilevel Indices):如果文件是一个非常大的顺序文件,则可在索引区建置多层索引,以提高执行效率
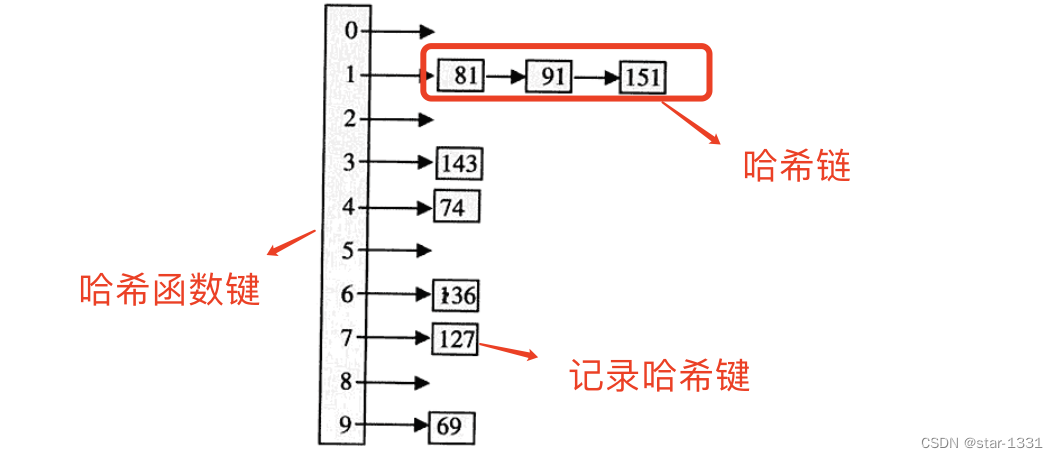
哈希索引(Hash Indices)
将索引分放在哈希函数数值列内,可迅速进行查找
哈希是最快速的一种查找方式,可几乎等同于直接查找,查找复杂度与数据多少无关
以哈希函数创建哈希表,记录查找键的特性,安放在对应数值列内。查找时,只要找到记录所属的数值列,即可找到记录
哈希函数
将哈希函数键置入哈希表索引数值列的函数内
HF = x mod 10,表示任何值x除以10的余数,即产生哈希函数键
哈希函数键
放在表索引数值列的索引键
查找时,可用哈希函数键非常迅速地查找到记录哈希键,查找复杂度与数据多少无关,为O(1)
哈希链
当多个记录查找键安排在同一位置时,以链接方式散开
静态哈希
一旦哈希函数设置了哈希表索引数值列,就不再改变索引数值列的结构,当添加或删除记录查找键时,仅更新哈希链的结构
缺点:当频繁增删数据记录,哈希链将长短不一,失去平衡,影响查找效率
解决方式:(都不是太好)
1、预留哈希链空间,以长度最大的哈希链为基准
2、定期更新哈希结构,视情况,选择适当的哈希函数定期更新
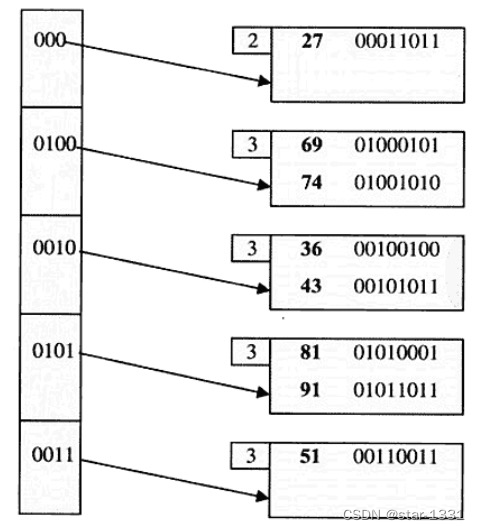
动态哈希
当增删查找键时,索引数值列与查找键数值列也随之对应增删
例如将查找键数值列值设为2
比较索引法和哈希法
当查找指定记录where a = c,选哈希
索引法的查找复杂度为O(log n),n为记录数量;
哈希法的查找复杂度与记录数量无关,为O(1)
当查找区间记录where a <= c1 and a >= c2,选索引
索引法已将记录查找键排序,只需查找1次
哈希法并未将记录查找排序,需要执行多次查找
事物管理
事物处理
执行多个连续操作,进而完成一个单元逻辑工作
多个进程同时运行时,进程之间相互影响、分享内存、分享数据,如果管理不严,将使数据失去一致性
多个进程执行,需要确保 事物处理ACID特性:
紧密性(Atomicity):在事务处理的多个操作中,若有任一个操作失败,则该事务操作不得返回结果(Reflect)进行数据库更新。换言之,必须每一个操作均成功执行后,才可将结果返回并进行数据库更新
一致性(Consistency):事务处理的各个操作执行完成后,应确保各环节与结果的一致性
绝缘性(Isolation):在事务处理内,各个操作间有其关键性的先后执行关系,多个操作并发时,仍应以关键性为准分别考虑,不能相互干扰
持久性(Durability),事务处理的各个操作成功执行完成后,应立即返回结果至数据库进行合理更新以确保系统的持久延续。
操作命令
读取read,将数据库的数据保存至缓冲区
写入write,将缓存区的数据搬移至数据库
事物处理状态
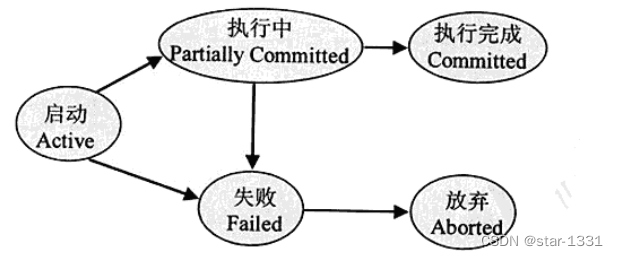
启动状态:事务处理开始执行的状态
执行中状态:事务处理正在执行的状态
失败状态:无法继续正常执行的状态
放弃状态:事物处理回滚至起始状态,同时数据库恢复至事务处理前的存储内容,此时准备重新启动或取消该事务处理
执行完成状态:事务处理成功执行完成,并返回数据库进行更新
数据库恢复机制
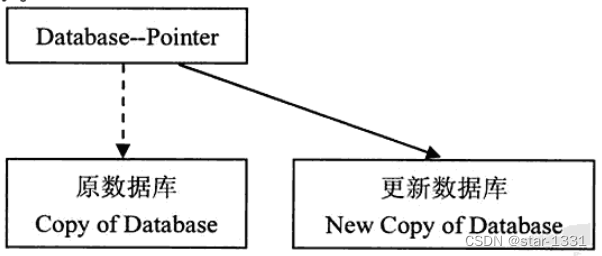
阴影复制法(Shadow Copy)
设置数据库指针(Database–Pointer)指向数据库
当要运行数据库更新时,系统将数据库复制为另一个新数据库,指针改为指向新数据库并执行更新
当事务处理成功执行完毕并更新数据库后,系统将删除原数据库(阴影数据库),使用更新数据库
当事务处理无法成功执行完毕并进入放弃状态,指针改为指向阴影数据库,准备重新启动
事务处理命令
事务处理的意义:当一个进程运行时,从开始读取数据到将运行结果写入数据库,此过程期间不允许任何改变原始数据的因素发生
setAutoCommit(false),系统将关闭自动运行模式,程序代码有运行描述,但无实际动作
————>
sql语句执行
————>
rollback(),回滚到起始状态
————>
commit(),将描述的所有程序代码一并快速运行
————>
setAutoCommit(true),解除事务处理环境,系统恢复正常运行模式
并发串行化
允许多重事务处理同时执行,视CPU的空闲,操作系统将各事务处理进行适当调度后交由CPU来执行,可明显提高CPU与周边资源的工作效率,同时减少事务处理各操作的等待时间
CPU某一时间只能执行一个工作任务,无法同时执行多个事务,但是可以轮流切换(Switch)执行各个事务处理
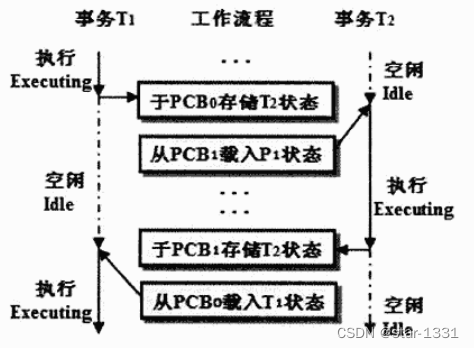
根据等待执行事务的数量不同,可分为单一事务处理和多批事务处理,两者都尊循一个执行完成之后,再执行另外一个
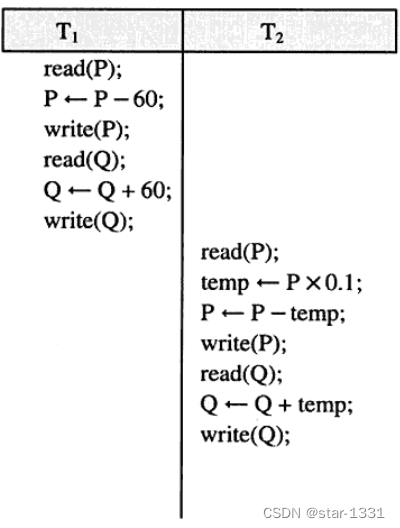
多重交互事物处理:各操作命令视CPU空闲,交互竞争进入。注意保持ACID特性。
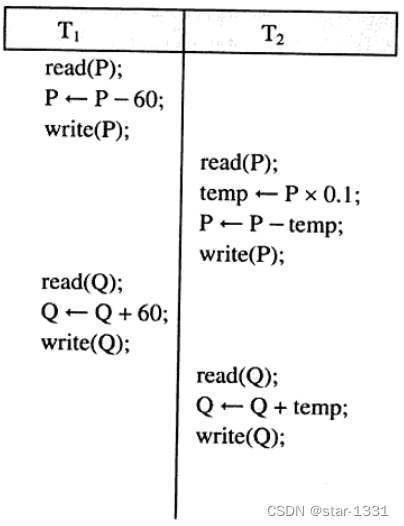
故障恢复
当事务处理无法继续正常执行时,将进入失败状态,再进入放弃状态。此时,系统将事务处理回滚至起始状态,同时数据库恢复至事务处理前的存储内容,准备重新启动或取消该事务处理
恢复命令
通过roolback()来辅助执行,在未执行commit()之前执行,可引导事务处理回滚到起始状态
恢复调度
当事务处理进入失败状态后,下一步应是执行恢复,准备重新启动或取消该事处理,调度设计尤为重要,否则会付出相当大的恢复代价。
可恢复调度
可恢复调度:能够进行回滚
不可恢复调度:不能进行回滚,之前误操作已更新完毕
无级联恢复调度
更新数据库的次序为T1、T2、T3,T1执行失败,T2、T3尚未执行,仅需回滚T1;T1更新完成,T2执行失败,T3尚未执行,只需回滚T2
按次序更新完成,一个完毕再执行另外一个
















 676
676











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









