







概念
批量执行数据
挑战
可维护性:如果批处理作业失败,必须知道失败的点和时间,以便快速调试。这利用了可维护性。
可扩展性:批处理必须是可扩展的。批处理作业批量在一段时间内可能从十个扩展到数千个的程度。应用程序必须能够在处理过程中没有明显滞后的情况下扩展操作的大小。
可用性:批处理作业并非始终完成,而是在某个时间安排。通常,企业批处理作业会堆积起来,以便在硬件、数据和其他资源可用的给定时间点进行处理。例如,在银行系统中,交易最终被安排在资源更多可用时记录。
安全性:批处理必须是安全的,涉及数据验证、敏感数据加密、安全访问外部系统等。
框架
Spring Batch
Spring Batch 是 2007 年与 Accenture 和 Spring Source 合作完成的一个项目。
Spring Batch 可以被视为三层配置:应用程序、核心和基础架构
三个层次如下:
应用程序:应用程序层编译开发人员编写的所有批处理作业和代码,例如业务逻辑、服务代码以及作业结构的配置。请注意,在实践中,应用程序不是一个独特的实体,而是核心和基础架构层的包装,因为在大多数情况下,开发包括自定义基础架构代码,例如读取器和写入器,以及核心类。
核心:核心包含用于控制和启动批处理作业的运行时类。它包括核心组件,例如 Job 和 Step 接口以及其他接口,例如 JobLauncher 和 JobParameters。
基础架构:基础架构包含开发人员所需的读取器、写入器和服务模板以及核心框架。它处理来自文件、数据库等的读、写、错误处理功能。
引入资源
<!--batch批处理-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-batch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.20</version>
</dependency>
配置
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.username=root
spring.datasource.password=12345678
spring.datasource.url=jdbc:mysql://localhost:3306/batch?useSSL=false&autoReconnect=true&characterEncoding=utf8
# 项目启动时创建数据表的sql脚本
spring.sql.init.schema-locations=classpath:config-schema.sql
# 项目启动时执行建表sql
spring.batch.jdbc.initialize-schema=always
# 批处理不自动执行,需手动执行
spring.batch.job.enabled=false
数据资源
data.csv
id,username,address,gender
1,张三,深圳,男
2,李四,广州,男
3,王五,上海,男
4,赵六,北京,男
事务编写
@Configuration
public class CsvBatchJobConfig {
// 用来构建job
@Autowired
JobBuilderFactory jobBuilderFactory;
// 用来构建step
@Autowired
StepBuilderFactory stepBuilderFactory;
// 支持持久化操作
@Autowired
DataSource dataSource;
// 配置一个ItemReader
// FlatFileItemReader用来加载普通文件
@Bean
@StepScope
FlatFileItemReader<User> itemReader(){
FlatFileItemReader<User> reader = new FlatFileItemReader<>();
// 第一行是标题,所以跳过一行
reader.setLinesToSkip(1);
// 配置资源文件位置
reader.setResource(new ClassPathResource("data.csv"));
// 设置每一行的数据信息
reader.setLineMapper(new DefaultLineMapper<User>(){{
setLineTokenizer(new DelimitedLineTokenizer(){{
setNames("id","username","address","gender");
// 配置列与列之间间隔符
setDelimiter(",");
}});
// 设置要映射的实体属性
setFieldSetMapper(new BeanWrapperFieldSetMapper<User>(){{
setTargetType(User.class);
}});
}});
return reader;
}
// 配置ItemWriter
// FlatFilterItemWriter写出一个普通文件
// JdbcBatchItemWriter通过JDBC将数据写出到一个关系型数据库
@Bean
JdbcBatchItemWriter jdbcBatchItemWriter(){
JdbcBatchItemWriter writer = new JdbcBatchItemWriter();
writer.setDataSource(dataSource);
writer.setSql("insert into user(id,username,address,gender) " + "values(:id,:username,:address,:gender)");
// 将实体类的属性和SQL中的占位符一一映射
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
return writer;
}
@Bean
Step csvStep(){
return stepBuilderFactory.get("csvStep")
.<User, User>chunk(2) //每读取两条数据就执行一次write操作
.reader(itemReader())
.writer(jdbcBatchItemWriter())
.build();
}
@Bean
Job csvJob(){
return jobBuilderFactory.get("csvJob")
.start(csvStep())
.build();
}
}
手动执行跑批
1、主入口开启批处理支持
@EnableBatchProcessing // 开启批处理支持
2、执行controller
@RestController
public class BatchController {
@Autowired
JobLauncher jobLauncher;
@Autowired
Job job;
@GetMapping("/batch")
public void batch(){
try{
Map<String, JobParameter> parameters = new HashMap<>();
parameters.put("date", new JobParameter(13L));
JobParameters jobParameters = new JobParameters(parameters);
jobLauncher.run(job, jobParameters);
}catch (Exception e){
e.printStackTrace();
}
}
}
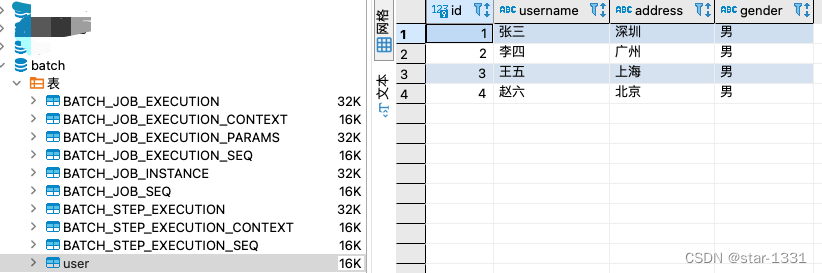
3、启动服务,并访问batch接口,batch库中会自动创建出多个批处理相关的表,这些表用来记录批处理的执行状态,同时,data.csv中的数据也成功插入user表中















 2803
2803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









