







背景:
-
多节点甚至多地部署,节点之间的数据一致性如何保证?
-
在并发场景下如何保证任务只被执行一次?
-
一个节点挂掉不能提供服务时如何被集群知晓并由其他节点接替任务?
-
存在资源共享时,资源的安全性和互斥性如何保证?
为解决分布式系统中面临的以上的一些挑战,在分布式环境下,需要一个协调机制来解决分布式集群中的问题,使得开发者更专注于应用本身的逻辑而不是关注分布式系统处理,保证分布式系统的数据一致性和容错性等。
ZooKeeper是一个分布式的开源协调服务,为分布式应用提供一致性服务,对数据的所有操作都是原子的和顺序一致的。ZooKeeper是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,通过Zab一致性协议在所有服务器之间复制一个状态机来确保数据的一致性,一旦这些数据的状态发生变化, Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
特点:
- Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
- 集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。
- 全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
- 更新请求顺序进行,来自同一个Client的更新请求按其发送顺序依次执行。
- 数据更新原子性,一次数据更新要么成功,要么失败。
应用场景:
ZooKeeper是分布式系统中非常重要的中间件,分布式应用程序可以基于ZooKeeper实现:
-
数据的发布和订阅
-
服务注册与发现:分布式环境中,客户端能实时洞察到服务器上下线的变化,实时掌握每个节点的状态,可根据节点实时状态做出一些调整。 ZooKeeper可以实现实时监控节点状态变化 可将节点信息写入ZooKeeper上的一个ZNode。监听这个ZNode可以获取它的实时状态变化。
-
分布式配置中心:分布式环境下,一般要求集群中,所有节点的配置文件信息同步。对配置文件修改后,希望能够快速同步到各个节点上。配置管理可交由ZooKeeper实现。可将配置信息写入ZooKeeper上的一个Znode,各个客户端服务器监听这个Znode,一旦ZNode中的数据被修改,ZooKeeper将通知各个客户端服务器。
-
统一命名服务:在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。如:IP不容易记住,而域名容易记住
-
分布式锁
-
Master选举
-
负载均衡:在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
-
分布式队列
zookeeper下载及安装
- 解压安装后,在zk文件夹下创建data和log目录,分别用于存储当前zk实例数据和日志。
- 在zk的data目录下,创建myid文件,此文件记录节点id,每个zookeeper节点都需要一个myid文件来记录节点在集群中的id,此文件中只能有一个数字,这里zk实例myid中写入一个1即可。
- 进入zk文件夹下bin/conf/目录,将配置文件zoo_sample.cfg重命名为zoo.cfg,配置zoo.cfg如下:
[root@hadoop1 conf]# vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000 # 单位时间,其他时间都是以这个倍数来表示
# The number of ticks that the initial
# synchronization phase can take
initLimit=10 # 节点初始化时间,10倍单位时间(即十倍tickTime)
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5 # 心跳最大延迟周期
# the directory where the snapshot is stored.
dataDir=/usr/java/zookeeper-3.4.6/data # 该实例对应的数据目录
dataLogDir=/usr/java/zookeeper-3.4.6/logs # 该实例对应的日志目录
# the port at which the clients will connect
clientPort=2181 # 客户端连接端口
# 集群配置
server.1=hadoop1:2888:3888 # server.id=host:port:port
server.2=hadoop2:2888:3888 # server.id=host:port:port
server.3=hadoop3:2888:3888 # server.id=host:port:port注意:
- 集群配置中模版为server.id=host:port:port,
- id是上面myid文件中配置的id,id与hostname必须一一对应;
- ip是节点的ip或host;
- 第一个port是节点之间通信的端口;
- 第二个port用于选举leader节点(集群模式下,不同服务器可以共用同一个port端口)
hadoop2机器上zk和hadoop3机器上zk的实例配置与hadoop1机器上zk类似,可以直接拷贝zk1的配置到hadoop2 hadoop3机器,然后修改各自的zoo.cfg和data目录下的myid即可。
├──zookeeper-3.4.6
│ ├── data
│ │ └── myid
│ ├── logs
│ └── bin
├── zookeeper-3.4.6
│ ├── data
│ │ └── myid
│ ├── logs
│ └── bin
└── zookeeper-3.4.6
│ ├── data
│ │ └── myid
├── logs
└── bin连接实例
所有实例全部启动过后,选择任一实例进行连接,这里选择hadoop2机器的实例zk,输入命令:
[root@hadoop1 zookeeper-3.4.6]# ./bin/zkCli.sh -server hadoop2:2181
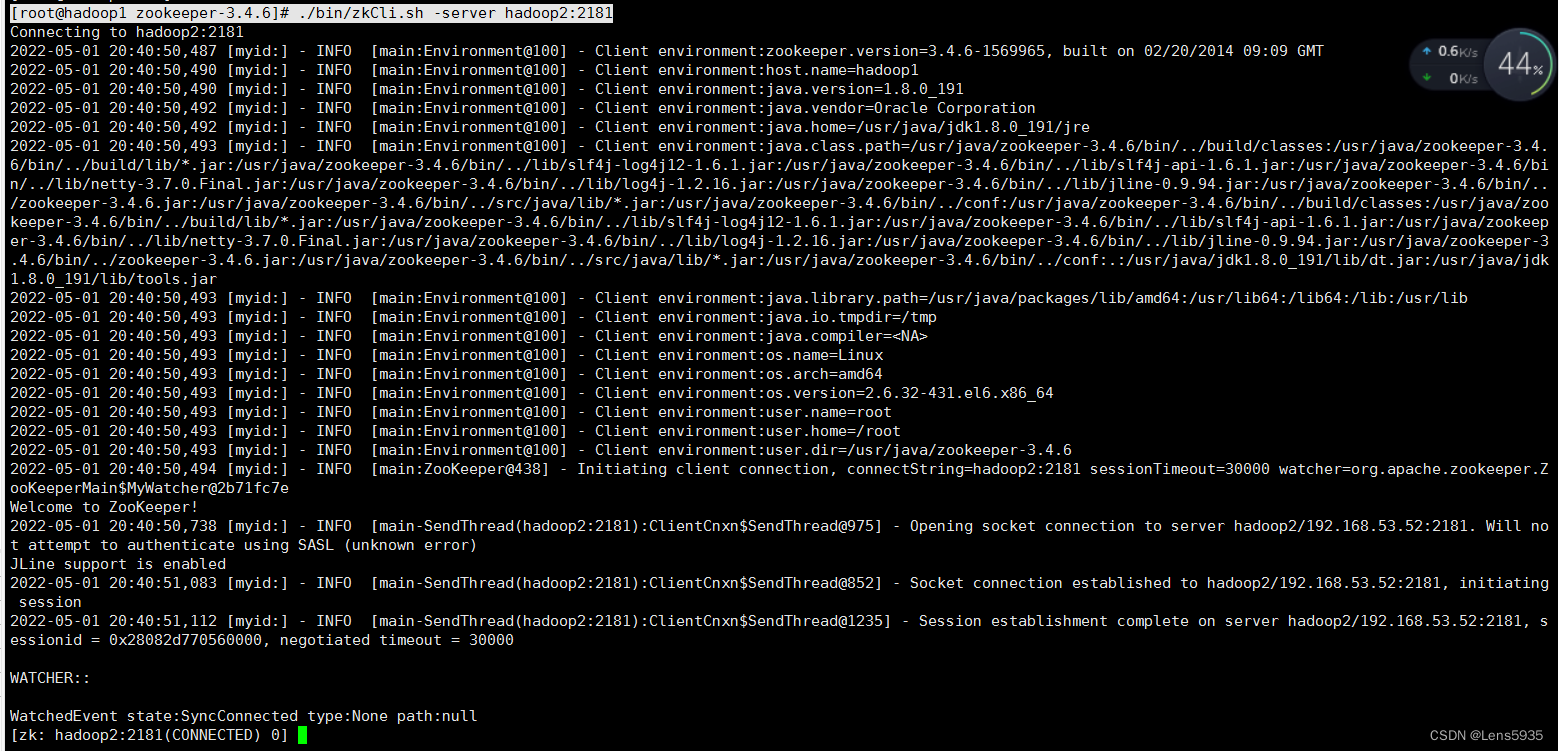
创建节点
连接成功之后,可以在当前实例上创建节点,类似于创建一个key-value值或者文件夹
[zk: hadoop2:2181(CONNECTED) 0] create /zk_test 1234
Created /zk_test
[zk: hadoop2:2181(CONNECTED) 1] get /zk_test
1234
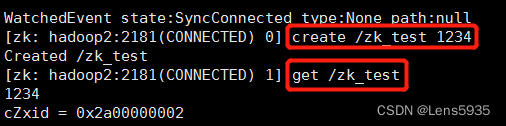
在其他实例上获取hadoop2上zk实例创建的节点
zk为了保证数据的一致性,zk会将节点写入的值同步到集群中每个节点,那么其他节点理论上也可以访问到hadoop2机器上传zk创建的值。连接hadoop3机器上zk来验证下:
[root@hadoop3 bin]# . zkCli.sh -server hadoop2:2181
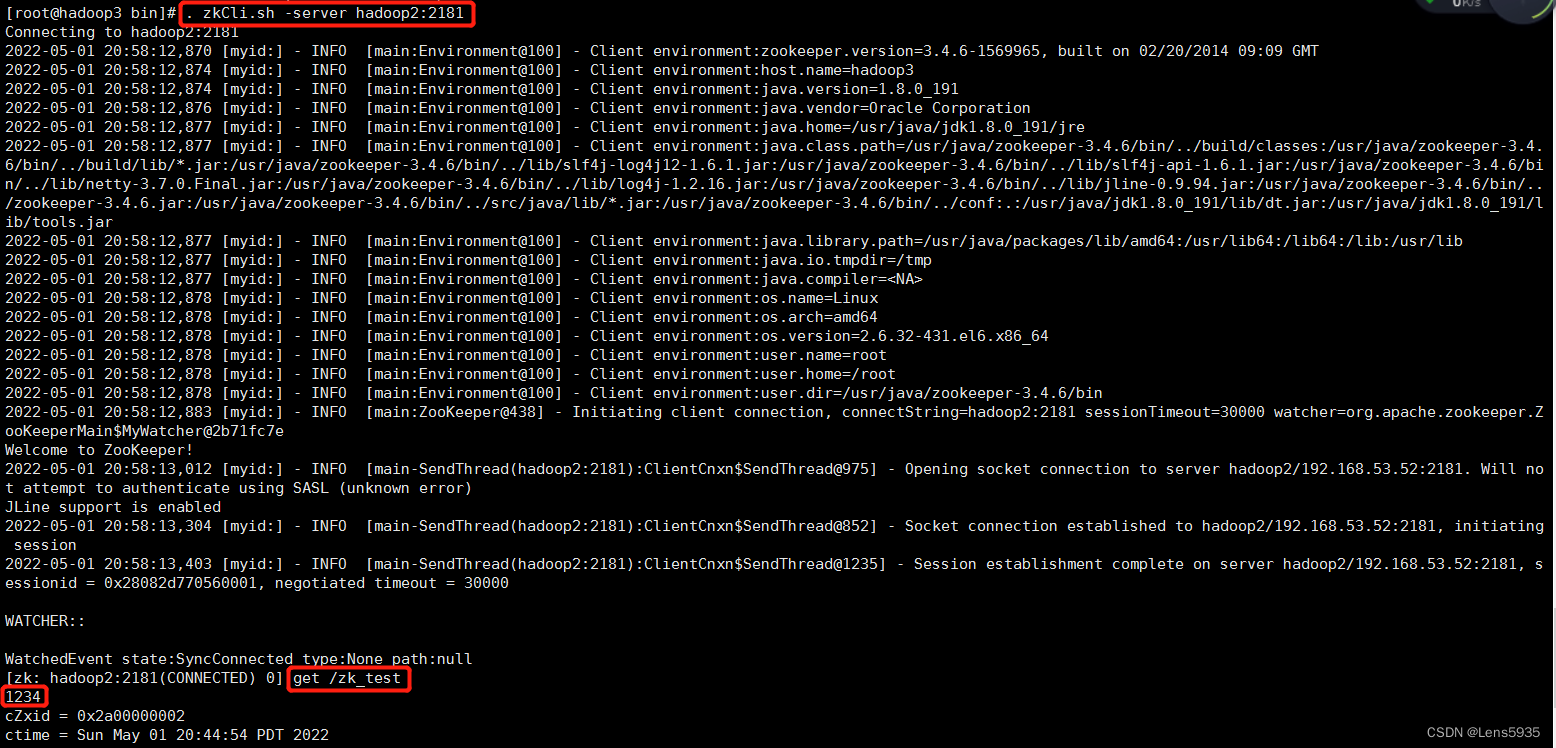 可以看到,我们成功的在hadoop3机器zk上获取到hadoop2机器zk创建的节点,说明数据写入zk2后,在各个节点间同步并实现了一致。
可以看到,我们成功的在hadoop3机器zk上获取到hadoop2机器zk创建的节点,说明数据写入zk2后,在各个节点间同步并实现了一致。
zookeeper命令
1.create创建
使用 create 命令可以创建一个 ZNode 节点。默认创建永久节点。用法如下:
create [-s] [-e] path data acl
-s:表示创建一个顺序节点。
-e:表示创建一个临时节点。
path:表示要创建的节点路径名。
data:表示要创建的节点数据。
acl:表示要创建的节点的访问控制列表。可以不写,默认为 world:anyone:cdrwa。
注意:
不可以递归创建。例如:创建 /zk_test/node 节点时,其父节点 /zk_test 必须已经存在。
临时节点下不可以创建子节点。
2.ls读取
使用 ls 命令可以列出 Zookeeper 指定节点下的所有下级节点。用法如下:
ls path [watch]
path:表示要查询的节点路径。
watch:表示是否开启监控,监控 path 下的子节点变化(NodeChildrenChanged,NodeDeleted)。
使用 ls2 命令可以列出 Zookeeper 指定节点下的所有下级节点,并且显示当前节点的属性信息。用法如下:
ls2 path [watch]
path:表示要查询的节点路径。
watch:表示是否开启监控,监控 path 下的子节点变化。
3.get获取
使用 get 命令可以获取 Zookeeper 指定节点的数据内容和属性信息。用法如下:
get path [watch]
path:表示要查询的节点路径。
watch:表示是否开启监控,监控节点变化(NodeDataChanged,NodeDeleted)。
4.set更新
使用 set 命令可以更新指定节点的数据内容。用法如下:
set path data [version]
path:表示要更新的节点路径名。
data:表示要更新的节点数据。
version:表示指定基于哪个节点数据版本进行更新。
5.delete删除
使用delete 命令可以删除 Zookeeper 上的指定节点。用法如下:
delete path [version]
path:表示要删除的节点路径名。
version:表示指定基于哪个节点数据版本进行删除。
注意:不支持递归删除。例如:删除 /zk_test 节点时,其节点下不能存在子节点。
使用 rmr 命令可以递归删除 Zookeeper 上的指定节点和其所有的子节点。用法如下:
rmr path
path:表示要删除的节点路径名。
6.ACL
使用 setAcl 命令可以设置 Zookeeper 上的指定节点的访问控制列表,即访问权限。用法如下:
setAcl path acl
path:表示要设置权限的节点路径名。
acl:表示要设置的权限列表,可以设置多种权限。
例:为 /node 节点设置权限 ip:192.168.0.1:cdrwa 。
setAcl /node ip:192.168.0.1:cdrwa
getAcl
使用 getAcl 命令可以获取 Zookeeper 上的指定节点的访问控制列表。用法如下:
getAcl path
path:表示要获取权限的节点路径名。
例:获取 /node 节点的访问控制列表。
getAcl /node
7.其他
使用 stat 命令可以获取 Zookeeper 上的指定节点的属性信息。用法如下:
stat path [watch]
path:表示要获取属性信息的节点路径名。
watch:表示是否开启监控,监控节点变化(NodeDataChanged,NodeDeleted)。
例:查看 /node 节点属性信息。
stat /node
使用 connect 命令可以连接 Zookeeper 上的指定服务器。用法如下:
connect host:port --host:服务器IP,port:端口号
例:连接 192.168.0.12:2181 Zookeeper 服务器。
connect 192.168.0.1:2181
使用 close 命令可以关闭当前会话。
使用 quit 命令可以退出当前客户端。

















 877
877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









