







咱们这次主要详细讲解如何利用钉钉机器人进行定时发送爬虫的内容
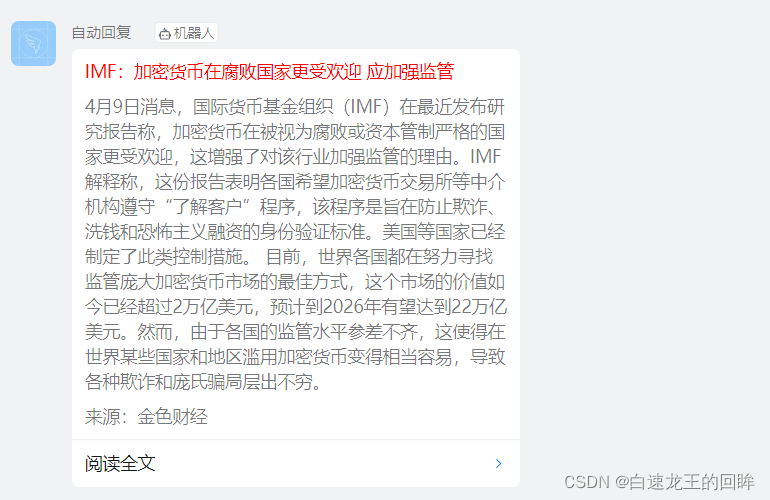
定时自动爬虫钉钉端展示

主要工具
python3
爬虫:beautifulsoup解析库
定时任务:celery框架
钉钉机器人:对应的文档接口数据格式使用,以及post的规范等
服务器:阿里云两核2Gb学生专用服务器
前置知识
简单的python爬虫知识:请求头,bs4使用,获取对应元素
python文件读写
celery框架运行逻辑
钉钉机器人接口,需要先注册钉钉企业,并开启机器人
可参考我之前的博客:钉钉机器人1.0
参考链接
celery开发参考
钉钉机器人文档
可参考的钉钉机器人创建
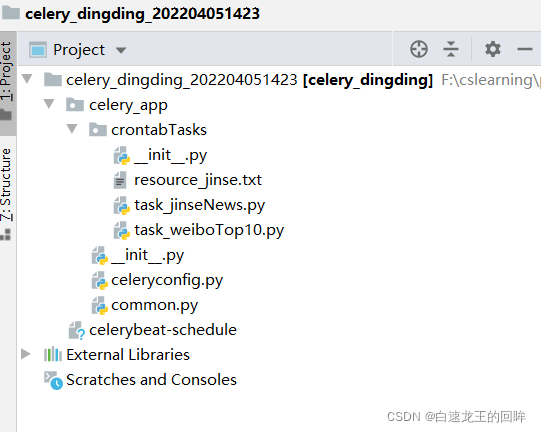
项目目录
外层的init
主要初始化,定义celery的实例以及从config中加载配置
# celery_app will load these info atomatically
from celery import Celery
# strict name format
app = Celery('dingding') # create an instance
app.config_from_object('celery_app.celeryconfig') # load the config
外部的celeryconfig
主要配置redis数据库作为broken核backend
同时导入模块并供beat任务定时调度
from datetime import timedelta
from celery.schedules import crontab
BROKER_URL = 'redis://127.0.0.1:6379'
CELERY_RESULT_BACKEND = 'redis://127.0.0.1:6379/0'
CELERY_TIMEZONE = 'Asia/Shanghai'
# task modules to import
# god damn 'S'!!!!!
CELERY_IMPORTS = (
'celery_app.crontabTasks.task_weiboTop10',
'celery_app.crontabTasks.task_jinseNews'
)
# schedules(beat)
CELERYBEAT_SCHEDULE = {
'weiboTop10-every-1-hour': {
'task': 'task_weiboTop10.get_news',
'schedule': timedelta(seconds = 3600),
},
'jinseNew-every-1-hour': {
'task': 'task_jinseNews.get_news',
'schedule': timedelta(seconds = 3600),
}
}
外部common
定义了钉钉机器人post需要的必要信息
import time
import hmac
import hashlib
import base64
# “自动回复”机器人
def get_sign_1():
# 当前时间戳
timestamp = int(round(time.time() * 1000))
# 密文
app_secret = '您的secert'
# 编码
app_secret_enc = app_secret.encode('utf-8')
# 时间戳 + 密文
string_to_sign = '{}\n{}'.format(timestamp, app_secret)
# (时间戳 + 密文) 编码
string_to_sign_enc = string_to_sign.encode('utf-8')
# 哈希摘要
hmac_code = hmac.new(app_secret_enc, string_to_sign_enc, digestmod=hashlib.sha256).digest()
# base64签名
sign = base64.b64encode(hmac_code).decode('utf-8')
# 返回时间戳 和签名
return timestamp, sign
内部weibotop10
用于爬虫抓取,并将抓取的信息通过server返回给robot并显示在聊天群中
import requests
import json
import time
from celery_app import app
from celery_app.common import get_sign_1
def ding_mesage(news):
# 钉钉header 加入时间戳 和 签名信息
ding_header = {"Content-Type": "application/json; charset=utf-8", 'timestamp': str((get_sign_1())[0]),
'sign': str((get_sign_1())[1])}
# 自己的oapi robot url,对应特定的token
ding_url = '您的url'
mes = {
"msgtype": "markdown",
"markdown": {
'title': "#### <font color=#FF0000>微博十大热门话题 </font> \n\n",
"text": "## <font color=#FF0000>微博十大热门话题 </font> \n\n",
}
}
# 加一个时间提示
mes['markdown']['text'] += time.ctime() + " \n\n"
url_specific = '(https://s.weibo.com/weibo?q=%23{}%23)'
# 信息link
for new in news:
new = ''.join(new.split())
mes['markdown']['text'] += '[' + new + ']' + url_specific.format(new) + " \n\n"
res = requests.post(ding_url, data=json.dumps(mes), headers=ding_header)
# 要对下面这个函数定时出发,一小时一次吧
@app.task(name = 'task_weiboTop10.get_news')
def get_news():
global latest_news
spider_header = {
'referer': 'https://weibo.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36',
}
url = 'https://weibo.com/ajax/side/hotSearch'
res = requests.get(url=url, headers=spider_header)
news = []
for i in range(10):
news.append(res.json()['data']['realtime'][i]['note'])
ding_mesage(news)
内部的jinseNews
获取金色财经新闻,通过txt记录当前id,保证每次获取的新闻不重复
通过爬虫 + post自动显示在聊天群中
import requests
import json
from celery_app import app
from celery_app.common import get_sign_1
def ding_mesage(news):
ding_header = {"Content-Type": "application/json; charset=utf-8", 'timestamp': str((get_sign_1())[0]),
'sign': str((get_sign_1())[1])}
ding_url = '您的url'
mes = {
"msgtype": "actionCard",
"actionCard": {
"title": news['title'],
'text': "#### <font color=#FF0000>{} </font> \n\n {} \n\n来源:金色财经".format(news['title'], news['content']),
"singleTitle": "阅读全文",
"singleURL": news['url']
}
}
res = requests.post(ding_url, data=json.dumps(mes), headers=ding_header)
# 要对下面这个函数定时出发,一小时一次吧
@app.task(name = 'task_jinseNews.get_news')
def get_news():
with open('celery_app/crontabTasks/resource_jinse.txt', 'r') as file:
latest_news = int(file.read())
spider_header = {
'referer': 'https://www.jinse.com/',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36'
}
res = requests.get(url='https://api.jinse.cn/noah/v2/lives?limit=20&reading=false&source=web&flag=up&id=&category=1'.format(latest_news), headers=spider_header)
for news in res.json()['list'][0]['lives']:
if news['id'] == latest_news:
break
news_data = {}
news_data['title'] = news['content_prefix']
news_data['content'] = news['content'].split('】')[-1]
news_data['url'] = 'https://www.jinse.com/lives/{}.html'.format(news['id'])
ding_mesage(news_data)
latest_news = res.json()['list'][0]['lives'][0]['id']
with open('celery_app/crontabTasks/resource_jinse.txt', 'w') as file_w:
file_w.write(str(latest_news))
最后
通过拉起celery服务部署到server上即可完成
总结
利用server的一次小实验
定时任务 + 爬虫 + 钉钉机器人api调用小demo



















 6604
6604

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











