



NLP类(参考书目:自然语言处理:基于预训练模型的方法):
1、GPT,是一种自回归语言模型,预训练是最大化似然函数
其中k是上文窗口大小,θ是网络参数
2、Bert
基于自编码的预训练任务进行训练,基本预训练任务由掩码语言模型(MLM)和下一个句子预测(NSP)组成。
掩码语言模型中,将原文本中15%的词MASK掉,通过Bert得到MASK的词的上下文表示hi,再通过词向量矩阵W(就是最开始的Embedding矩阵)进行还原,得到概率分布P
与原词标签比较,得到交叉熵损失进行训练。
下一个句子预测
该预训练任务用于构建两段文本之间的联系,正负样例比例大致控制在1:1,是一个二分类任务,判断第二句话是不是第一句话的下一句。
输入格式是这样的:
[CLS]sentence1[SEP]sentence2[SEP]
选取最后一层的第一个输出(即[CLS]位置的隐含层表示h0)乘以Embedding矩阵进行二分类
其它预训练任务:
1、整词掩码(针对中文),分词之后掩码最小单位是中文的词
2、n-gram掩码 分词之后,先判断需不需要掩码,如果需要掩码,选择连续掩码几个(个数越多,概率越小)
RL类
这篇总结中介绍了3篇文章,和模仿学习相关,但它们只有专家序列的状态,没有动作(其实模仿学习可以看成一种预训练)
1.playing hard exploration games by watching youtube
预训练辅助任务:
预测视频中两帧之间的时间间隔,将视频和图像对应
通过辅助任务得到环境的良好表征
模仿过程:
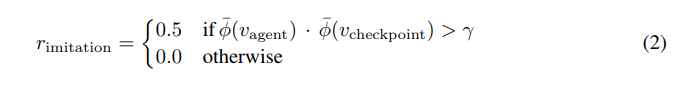
如果智能体产生的状态和专家状态的相似度大于一个定值,就可以获得额外奖励
2.zero shot visual imitation
对环境进行随机探索,目的是搜集数据,训练一个模型,这个模型可以根据当前状态和目标,输出达到目标的动作序列。Goal-conditioned skill policy (GSP)
这样,输入初始状态和专家序列中的状态,就可以重现专家序列。
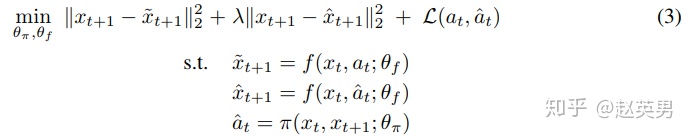
训练时,损失函数由3部分构成。
第一部分是让模型在正确的动作下,预测下一个状态尽量准
第二部分是让模型在设想的动作下,预测下一个状态也尽量的准(动作可以不一样,但下一状态要一样)
第三部分是让动作预测尽量准。
上面用于训练的数据都是在前期探索中获得的,训练也是自监督的。
3. Imitating Latent Policies from observation
论文中的方法分为两部分。
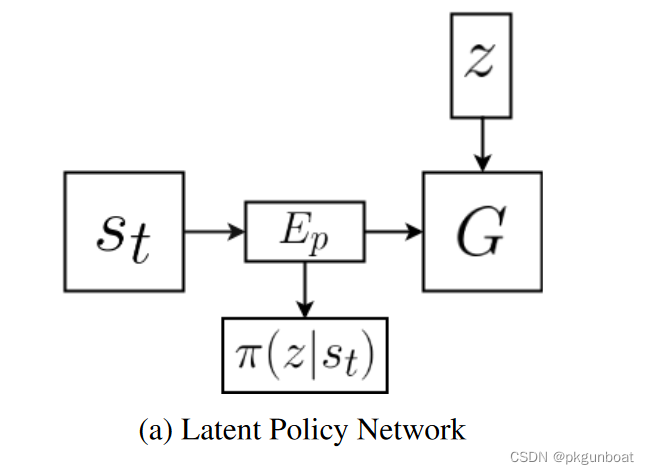
第一部分,通过观察专家状态序列进行学习(只有状态,没有动作)
自己根据观察总结出动作空间(相当于看朋友玩视频类游戏,有些操作理论是可行的,但是朋友没做出来过,那你就不知道有这种操作,或者你观察到朋友没有动,以为有stop这种动作,但实际上只是被墙卡住了)和状态进行学习,建立映射
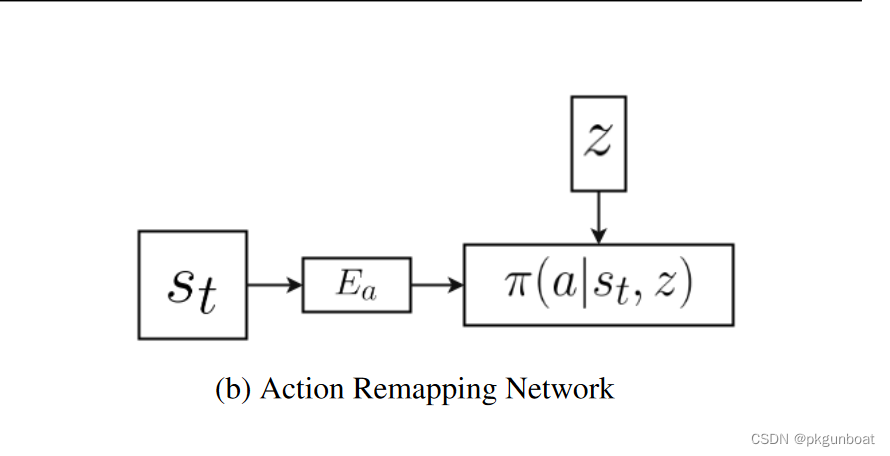
第二部分,将自己脑补出的动作,和现实中的动作进行映射(之前是看别人玩,现在是自己上手了,这个步骤有点像把游戏键位换成自己熟悉的键位)
第一部分的loss分为两部分,Lmin用来约束生成模型,让生成的下一个状态尽量准确
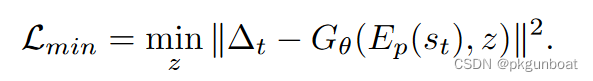
第二部分Lexp约束概率分布,表面看是让St+1的期望和St+1尽量接近,实际上是为了约束z的条件概率分布
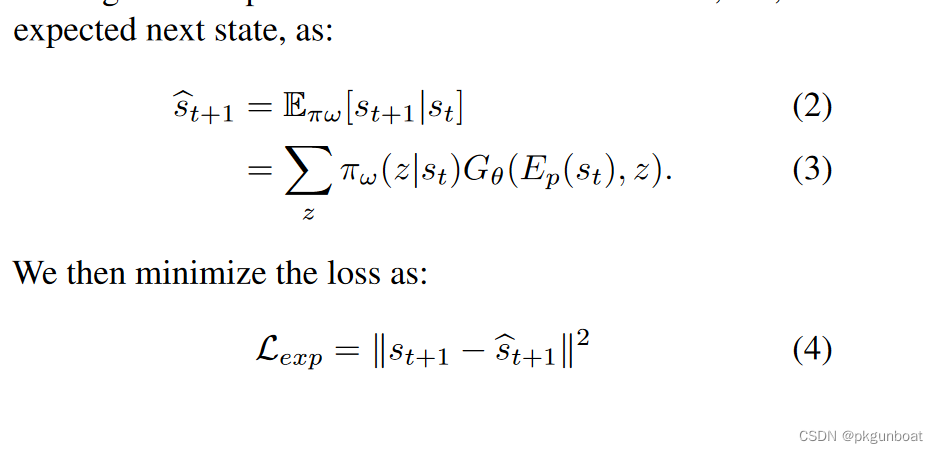
第二部分的loss用于建立映射
首先使用策略进行探索(比如随机策略),采样到{st, at, st+1}这种序列用于训练。根据st+1和st选择出最有可能的z,将z的概率使用交叉熵损失函数最大化。

4.Reinforcement learning of physical skills from videos
不再需要动作捕捉,伯克利推出「看视频学杂技」的AI智能体 - 知乎
这篇工作预处理部分和强化学习关系不大,和CV关系比较大,这里就记录一下reward的设计

5.Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos
原来《我的世界(Minecraft)》还能用视频预训练方法来玩! - 知乎
通过类似Bert的预训练方法,训练一个动作标记器,之后可以对网上海量的动作进行标记,做模仿学习再微调。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









