






该论文主要讲述了多智能体通信。
简介中提出,很多多智能体任务需要通信,所以提出了两种算法RIAL和DIAL。论文中考虑的任务是完全合作,部分观测,顺序多智能体决策的任务。所有的智能体的目标是相同的,最大化累计折扣奖励。没用智能体能观察到完整的马尔可夫状态,智能体之间可以通过有限离散的信道交流,智能体必须发现一种通信协议始得他们协调表现以及解决问题。论文所关注的设置是中心化训练,去中心化执行。
RIAL算法使用了DRQN算法。一种变种是独立q-learning,即把其它智能体当作环境的一部分。第二种是训练一个网络,参数队所有智能体共享,执行保持去中心化,不同的观测可以导致不同的表现。
DIAL算法着眼于中心化训练,相比仅仅参数共享提供了更多的机会提升学习。事实上,RIAL算法在智能体内部可以端到端训练,跨智能体之间不可端到端训练,因为智能体之间没有梯度通过。第二个措施始得通过中心化学习,实值信息可以在智能体之间流动,因此处理通信动作成为了智能体之间连接的瓶颈。结果是,梯度可以通过通信信道传播。通过去中心化执行,实值信息可以离散化映射到通信动作。
正向的奖励是稀疏的,因为正的奖励只有当正确的发送和被接收才能得到,而这很难通过随机搜索去发现。
因为RIAL算法有两个动作:环境动作u和通信动作m,所以训练两个网络Qu和Qm,这样可以减少输出的个数。RIAL算法取消了DQN中使用的repalybuffer,因为多个智能体同时学习是非稳态的,replaybuffer的数据会有误导性。
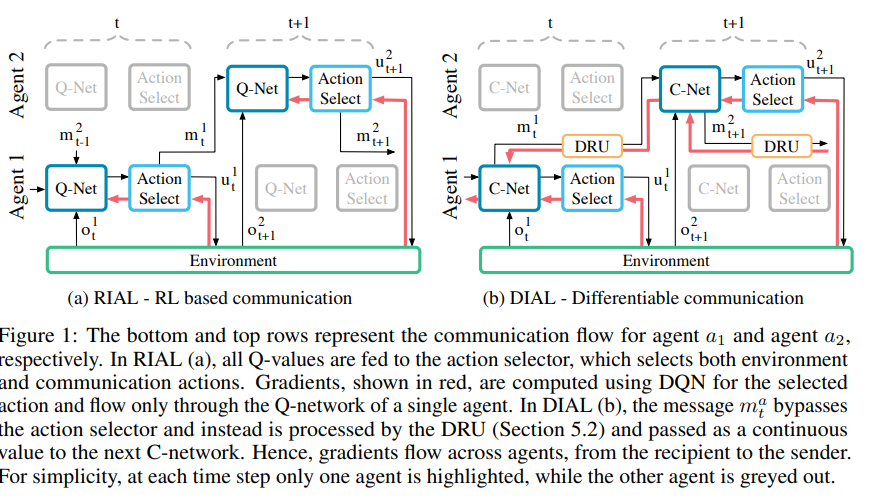
两张图分别是RIAL算法和DIAL算法。
RIAL算法使用了参数共享,所有的智能体共用一套参数,通过输入来区分不同的智能体。

当然RIAL算法也有缺陷,它并没有发挥中心化学习的全部优势,智能体没有给其它智能体通信动作的反馈,而这对于学习通信协议是很重要的。(个人感觉这里action select可以用gumbel softmax,这样梯度可以传播)
DIAL解决了这个缺陷,DIAL结合了中心化学习和Q网络,不仅仅参数共享,而且通过通信信道在智能体之间传播梯度。DIAL在中心化学习时,通信动作被一个智能体网络的输出和其它智能体网络的输入之间的直接连接所取代。因此,当任务限定通信为离散信息时,在学习期间智能体将自由发送实值信息给其它智能体。因为这些信息的功能与其它网络的激活相同,梯度可以在信道中传播,允许智能体之间端到端的反向传播。
C-net输出两种不同的值,Q值用于actor-selector,mt是实值信息向量,通过actor-selector,并通过DRU单元。DRU单元将mt添加高斯噪声,并通过一个logistic回归。














 2185
2185











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









