






SpringCloud与Dubbo的区别?
两者都是现在主流的微服务框架,但却存在不少差异:
初始定位不同:SpringCloud定位为微服务架构下的一站式解决方案;Dubbo 是 SOA 时代的产物,它的关注点主要在于服务的调用和治理
生态环境不同:SpringCloud依托于Spring平台,具备更加完善的生态体系;而Dubbo一开始只是做RPC远程调用,生态相对匮乏,现在逐渐丰富起来。
调用方式:SpringCloud是采用Http协议做远程调用,接口一般是Rest风格,比较灵活;Dubbo是采用Dubbo协议,接口一般是Java的Service接口,格式固定。但调用时采用Netty的NIO方式,性能较好。
组件差异比较多:例如SpringCloud注册中心一般用Eureka,而Dubbo用的是Zookeeper
SpringCloud生态丰富,功能完善,更像是品牌机,Dubbo则相对灵活,可定制性强,更像是组装机。相关资料
Dubbo流程?
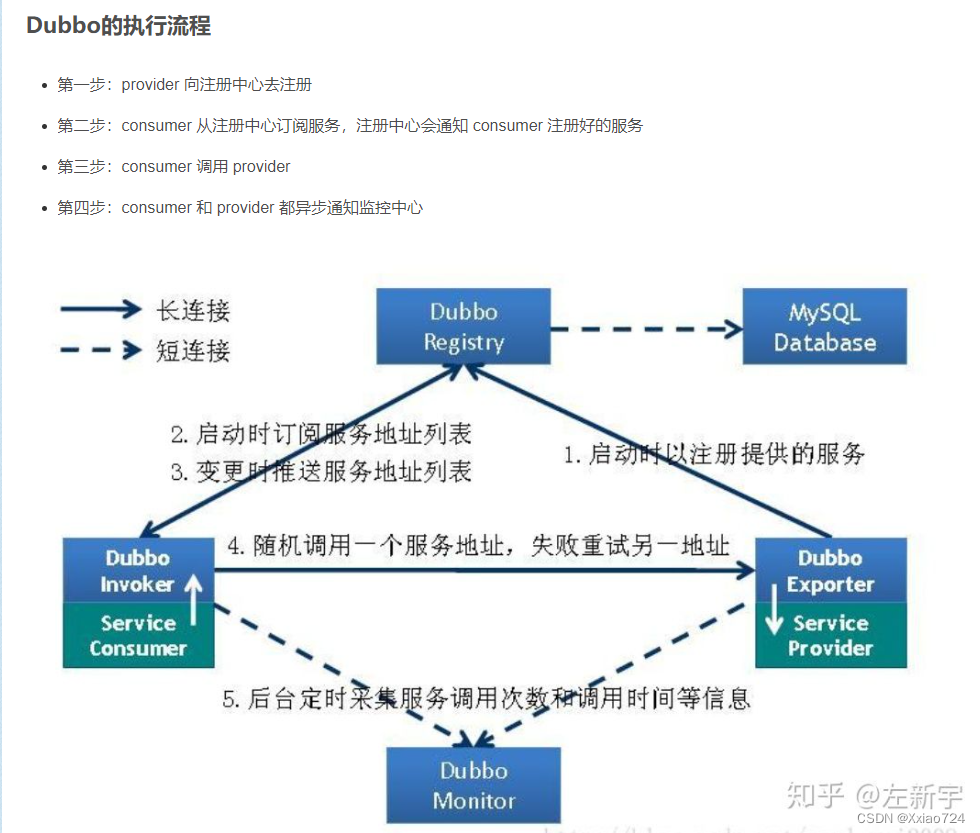
dubbo调用失败策略?
Failover(失败自动切换):调用出现失败的时候 根据配置的重试次数 会自动从其他可用地 址中重新选择一个可用的地址进行调用
Failsafe(失败安全):当出现调用失败时,会忽略此错误,并记录一条日志,同时返回一个空结果
Failfast(快速失败):调用失败立即报错 幂等性
Forking(并行调用):第一次调用的时候就同时发起多个调用,只要其中一个调用成功,就认为成功
Broadcast(广播调用):只要任意有一个提供者出错,则认为此次调用出错
dubbo协议与http协议对比?
协议层区别
HTTP ,HTTPS 使用的是 应用层协议 应用层协议:定义了用于在网络中进行通信和传输数据的接口
DUBBO接口使用的是 TCP/IP是传输层协议 传输层协议:管理着网络中的端到端的数据传输
决定了dubbo协议比http协议要快
socket层区别
dubbo默认使用socket长连接,即首次访问建立连接以后,后续网络请求使用相同的网络通道
http1.1协议默认使用短连接,每次请求均需要进行三次握手,而http2.0协议开始将默认socket连接改为了长连接
特点
rpc长连接:传输效率较高,可定制化路由,适用于内部系统互联;
http短连接:协议标准化且易读,容易对接外部系统,适用于上层业务模块
dubbo协议追求的是数据量小,小则快,适用与内部服务之间的数据交互。
安全性就没有https做的那么好,但是也不需要,毕竟dubbo协议设计的初衷就是内部使用的。
为了让单线程(进程)的服务端应用同时处理多个客户端的事件
既然dubbo协议适用于服务之间的互相调用。spring cloud的feign内部为什么使用http协议呢?个人认为是架构的需要吧,例如服务A是java写的,服务B是python写的。这个时候dubbo协议就跑不通了。只能用http这种标准协议来交互。
nginx进行负载均衡?
三大类: 1轮询 2最少连接 3 ip hash
1 轮询
普通轮询方式
权重轮询方式
2最少连接
请求分配给活动连接数最少的服务器,哪台服务器连接数最少,则把请求交给哪台服务器,由nginx统计服务器连接数
确保了相同的客户端的请求一直发送到相同的服务器
Eureka的流程?


Eureka自我保护机制?
既然Eureka Server会定时剔除超时没有续约的服务,那就有可能出现一种场景,网络一段时间内发生了 异常,所有的服务都没能够进行续约,Eureka Server就把所有的服务都剔除了,这样显然不太合理。所以,就有了 自我保护机制,当短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下, Eureka Server不会剔除任何的微服务,等到服务恢复正常后,再退出自我保护机制。自我保护开关
服务同步:
Eureka Server之间会互相进行注册,构建Eureka Server集群,不同Eureka Server之间会进行服务信息同步,用来保证服务信息的一致性
Eureka和Zookeeper的区别

SpringCloud五大核心组件
Eureka 注册中心
Eureka service:注册中心,里面有一个注册表,保存了各个服务所在的机器和端口号
Eurake Client:负责将这个服务的信息注册到Eureka Server中
Feign 服务之间的调用(采用http调用)
Feign的一个机制就是使用了jdk动态代理
首先,如果你对某个接口定义了@FeignClient注解,Feign就会针对这个接口创建一个动态代理
Feign的动态代理会根据你在接口上的@RequestMapping等注解,来动态构造出你要请求的服务的地址
最后针对这个地址,发起请求、解析响应
Ribbon 负载均衡
Ribbon 作用是负载均衡,会帮你在每一次请求的时候选择一台机器,均匀的把请求发送到各个机器上 ,Ribbon的负载均衡默认的使用RoundRobin(哈希取模算法)轮询算法。
首先Ribbon会从 Eureka Client里面获取到对应的服务注册表,也就知道了所有的服务都部署在了那台机器上
然后Ribbon就可以使用默认的Round Robin算法,从中选择一台机器,
Feigin就会针对这些机器构造并发送请求。

Hystrix 熔断 降级
熔断:配置属性有 是否开启熔断器 请求次数 失败率达到多少后跳闸
5分钟内请求积分服务直接就返回了,不要去走网络请求卡住几秒钟,这个过程,就是所谓的熔断!
@FeignClient(name = "eureka-client",fallback =UserClientFallBack.class )
Fallback属性 定义的是熔断类 如果调用失败可以直接返回 自定义的错误或者降级处理方案 而不会抛出异常
FallbackFactory属性 会捕获异常信息
zull 网关服务
前端不用去关心后端有几百个服务,就知道有一个网关,所有请求都往网关走,网关会根据请求中的一些特征,将请求转发给后端的各个服务。
Nacos的实现原理
1.客户端provider向nacos server的open api发起调用,把自己的服务地址链接,服务名称注册上去
2.nacos server与服务提供者provider建立心跳机制,用来检测服务状态
3.服务消费者consumer查询出提供服务实例列表
4.并且默认10s去nacos server拉取服务实例列表
5.当服务消费者检测到服务异常,基于UDP协议推送更新
6.服务消费者即可调用了
nacos特性
nacos支持CP和AP两种
nacos是根据配置识别CP或AP模式,如果注册Nacos的client节点注册时是ephemeral=true即为临时节点,那么Naocs集群对这个client节点效果就是AP,反之则是CP,即不是临时节点
#false为永久实例,true表示临时实例开启,注册为临时实例
spring.cloud.nacos.discovery.ephemeral=true
连接方式
nacos使用的是netty和服务直接进行连接,属于长连接
服务异常剔除
eureka:
Eureka client在默认情况每隔30s想Eureka Server发送一次心跳,当Eureka Server在默认连续90s秒的情况下没有收到心跳, 会把Eureka client 从注册表中剔除
nacos:
nacos client 通过心跳上报方式告诉 nacos注册中心健康状态,默认心跳间隔5秒,
nacos会在超过15秒未收到心跳后将实例设置为不健康状态,可以正常接收到请求
超过30秒nacos将实例删除,不会再接收请求
操作实例方式
nacos:提供了nacos console可视化控制话界面,可以对实例列表进行监听,对实例进行上下线,权重的配置,并且config server提供了对服务实例提供配置中心,且可以对配置进行CRUD,版本管理
eureka:仅提供了实例列表,实例的状态,错误信息,相比于nacos过于简单
自我保护机制
相同点:保护阈值都是个比例,0-1 范围
不同点:
1)保护方式不同
Eureka保护方式:当在短时间内,统计续约失败的比例,如果达到一定阈值,则会触发自我保护的机制,在该机制下,Eureka Server不会剔除任何的微服务,等到正常后,再退出自我保护机制。自我保护开关(eureka.server.enable-self-preservation: false)
Nacos保护方式:当健康实例占总服务实例 的比例小于阈值时,无论实例 (Instance) 是否健康,都会将所有实例返回给客户端。这样做虽然损失了一部分流量,但是保证了集群的剩余健康实例 (Instance) 能正常工作。
2)范围不同
Nacos 的阈值是针对某个具体 Service 的,而不是针对所有服务的
Eureka的自我保护阈值是针对所有服务的。
如何解决分布式事务问题?
1 TCC
TCC分为3个阶段
-
Try 阶段:尝试执行,完成所有业务检查(一致性), 预留必须业务资源(准隔离性)
-
Confirm 阶段:确认执行真正执行业务,不作任何业务检查,只使用 Try 阶段预留的业务资源,Confirm 操作要求具备幂等设计,Confirm 失败后需要进行重试。
-
Cancel 阶段:取消执行,释放 Try 阶段预留的业务资源。Cancel 阶段的异常和 Confirm 阶段异常处理方案基本上一致,要求满足幂等设计。
Try里面冻结金额,但不扣款,
Confirm里面扣款
Cancel里面解冻金额
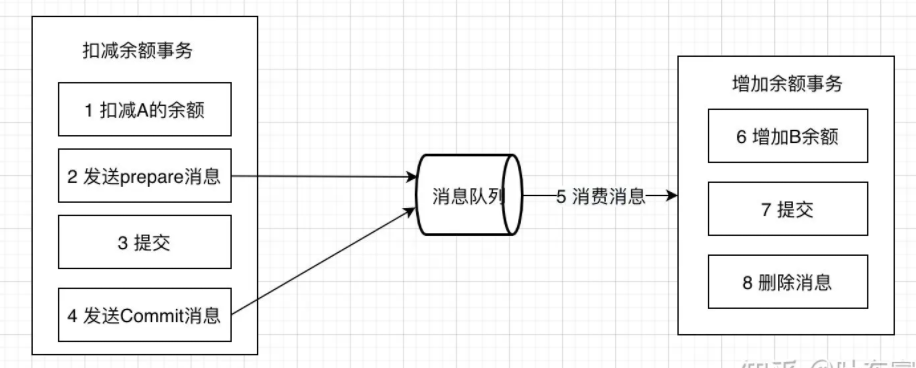
2 事务消息
该事务消息本质上是把本地消息表放到RocketMQ上,解决生产端的消息发送与本地事务执行的原子性问题。
事务消息发送及提交:
-
发送消息(半消息)
-
服务端存储消息,并响应消息的写入结果
-
根据发送结果执行本地事务(如果写入失败,此时half消息对业务不可见,本地逻辑不执行)
-
根据本地事务状态执行Commit或者Rollback(Commit操作发布消息,消息对消费者可见)
正常发送的流程图如下:
补偿流程:
对没有Commit/Rollback的事务消息(pending状态的消息),从服务端发起一次“回查”
Producer收到回查消息,返回消息对应的本地事务的状态,为Commit或者Rollback
事务消息方案与本地消息表机制非常类似,区别主要在于原先相关的本地表操作替换成了一个反查接口
事务消息特点如下:
-
长事务仅需要分拆成多个任务,并提供一个反查接口,使用简单
-
消费者的逻辑如果无法通过重试成功,那么还需要更多的机制,来回滚操作
适用于可异步执行的业务,且后续操作无需回滚的业务
如何实现分布式锁?
redis分布式锁
zk分布式锁
数据库














 3404
3404











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









