







扫描器源码
扫描的源码从这里开始,我们之前讲postProcessor的时候涉及过这部分代码,但是没有展开讲
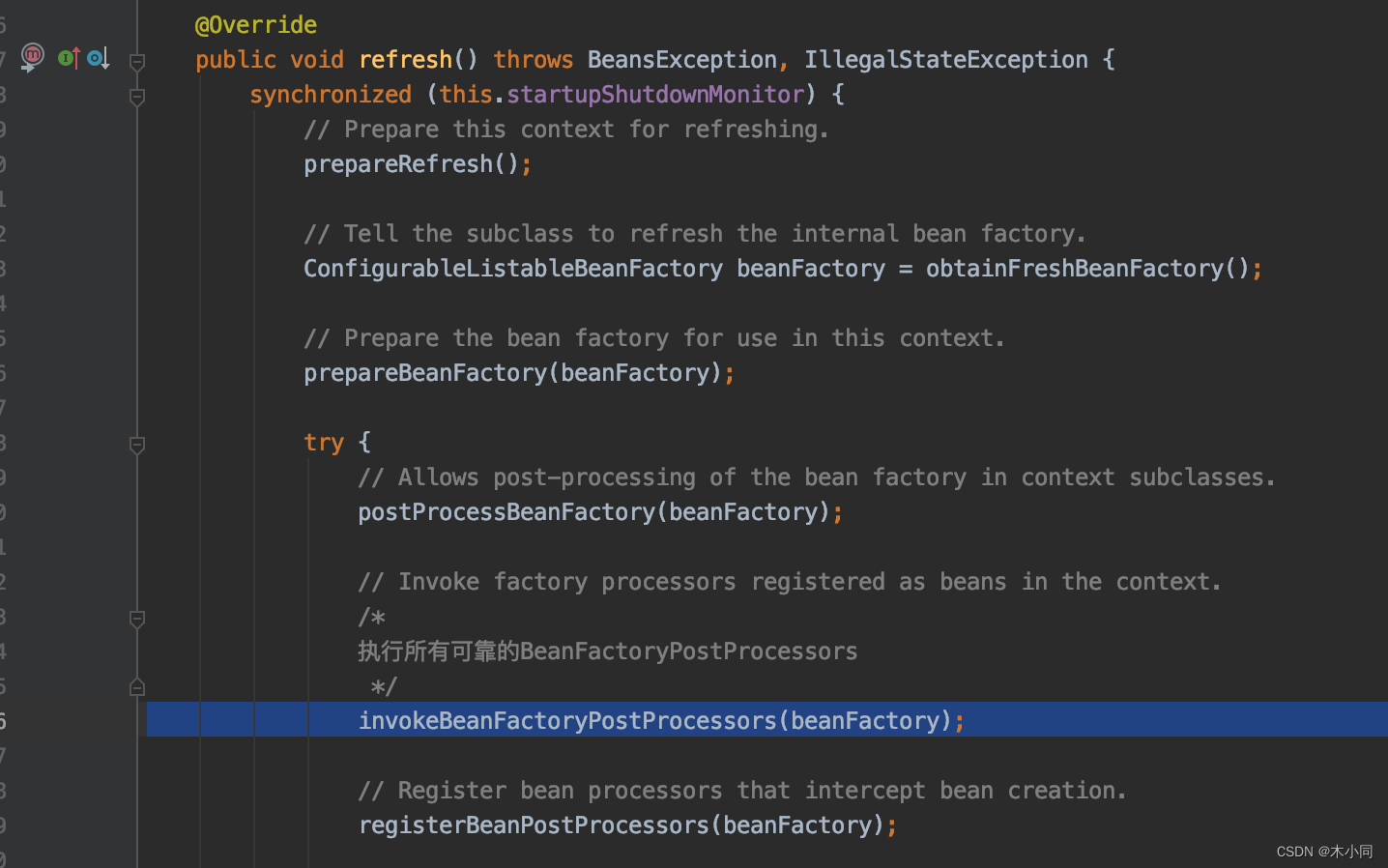
invokeBeanFactoryPostProcessors()–>
PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors()

这里就是我们之前涉及到的地方

ConfigurationClassPostProcessor.postProcessBeanDefinitionRegistry()

processConfigBeanDefinitions() --> ConfigurationClassParser.parse() --> parse()
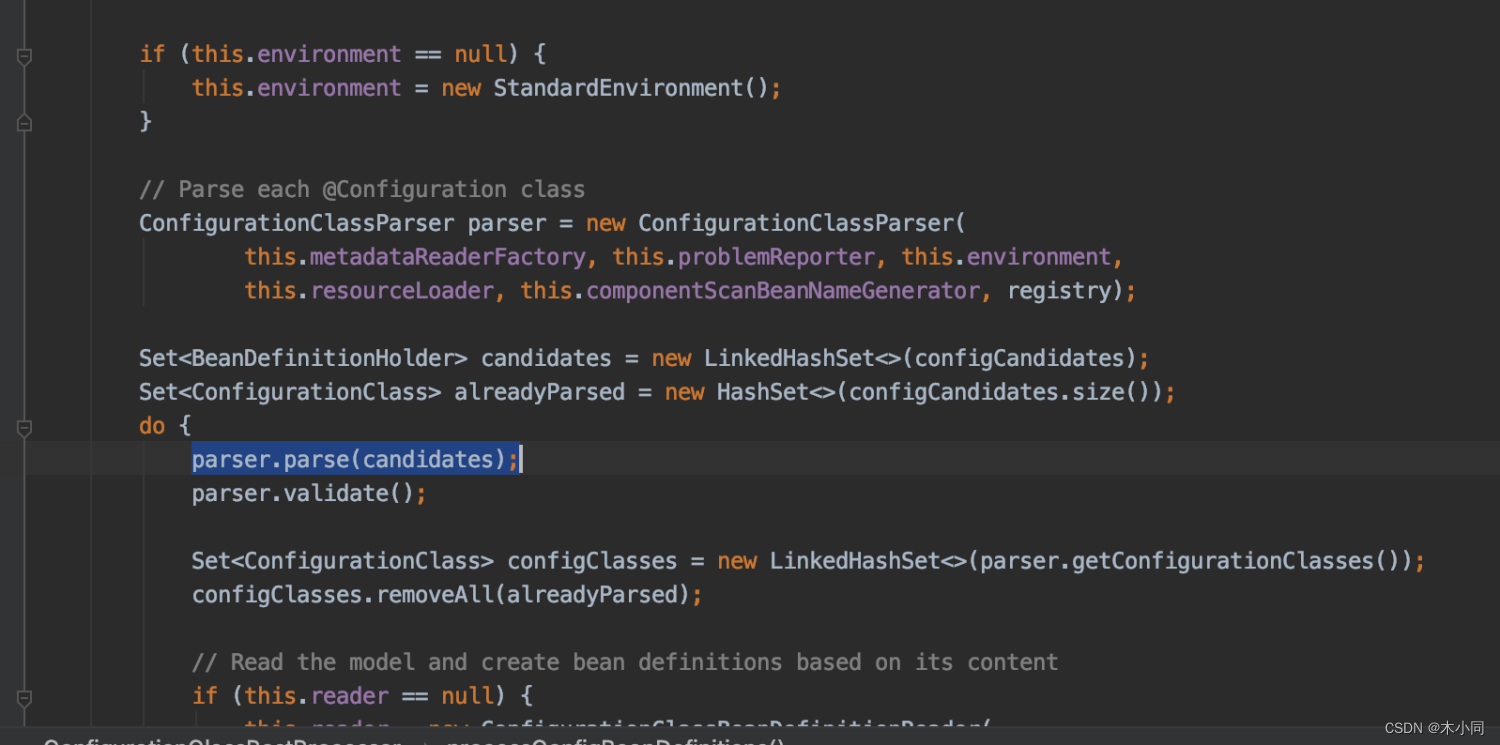
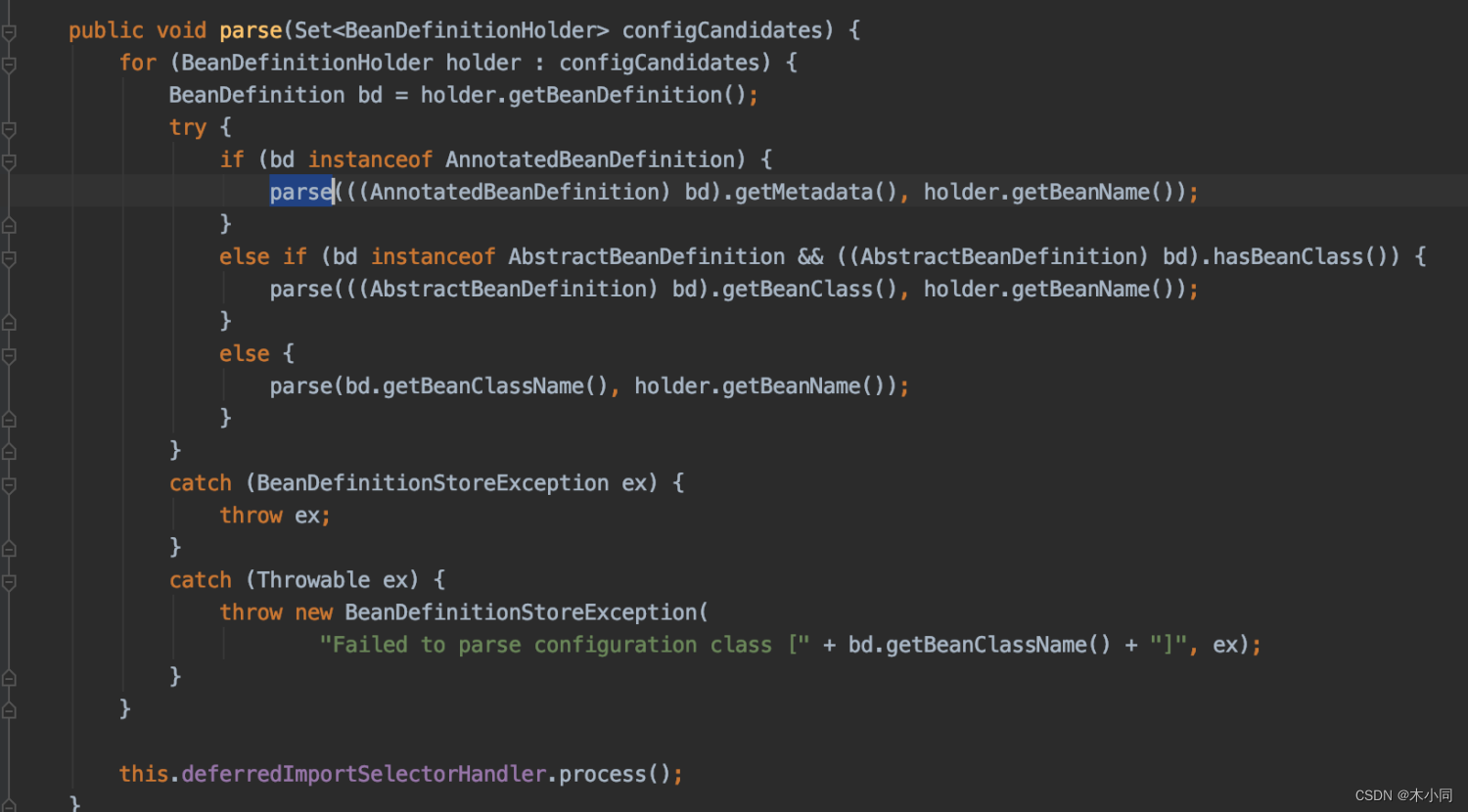
parse() – > processConfigurationClass()

processConfigurationClass() --> doProcessConfigurationClass()
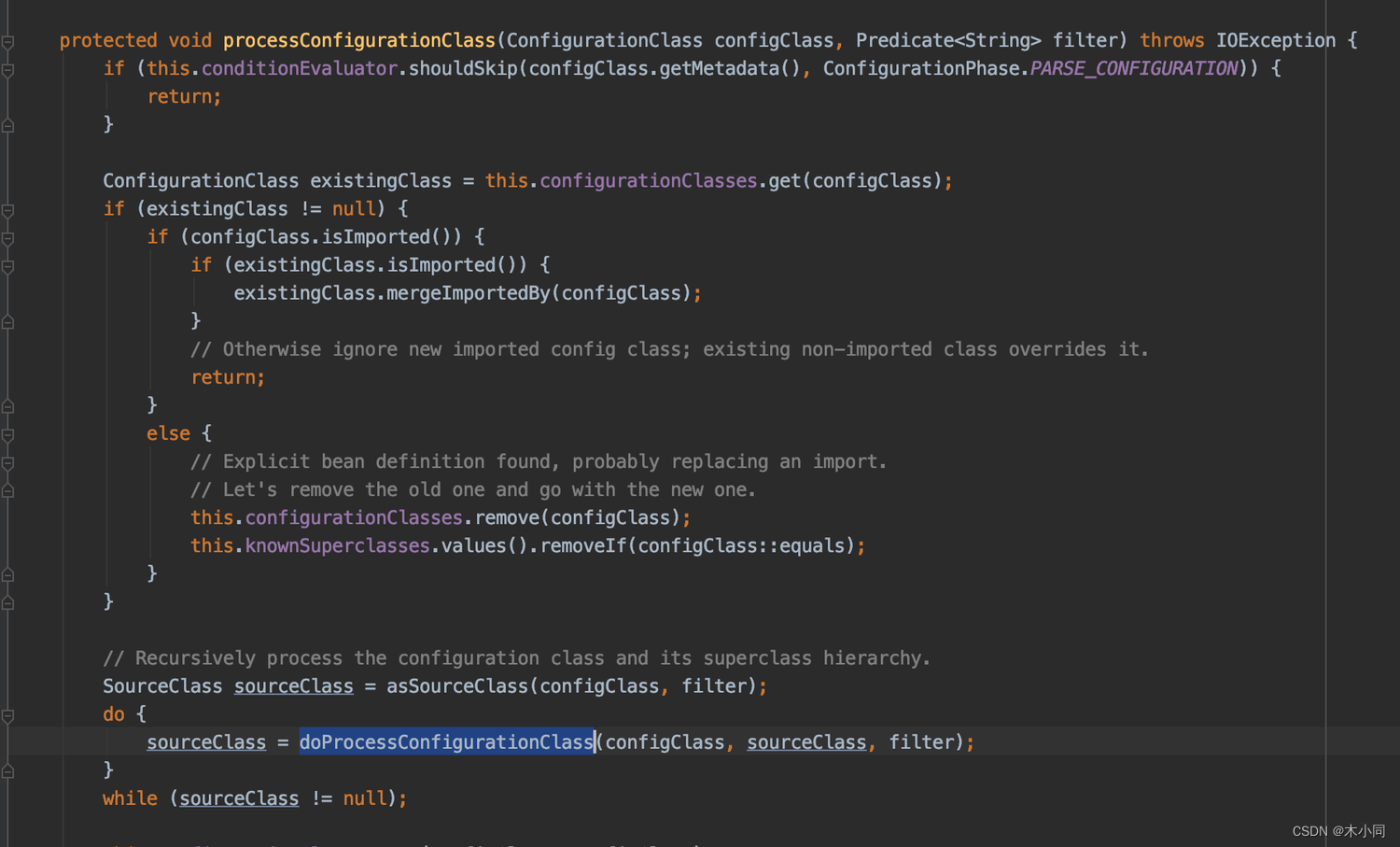
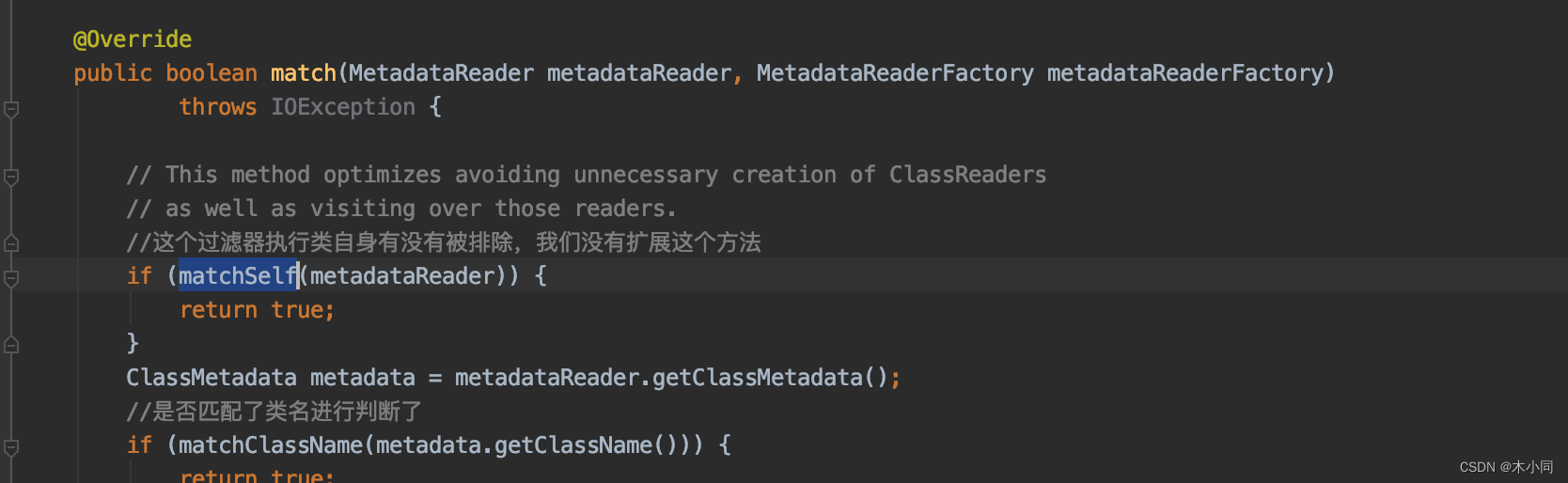
doProcessConfigurationClass() --> componentScanParser.parse()
这个方法配置了ClassPathBeanDefinitionScanner扫描器
//解析配置类上面的componentScan注解
public Set<BeanDefinitionHolder> parse(AnnotationAttributes componentScan, String declaringClass) {
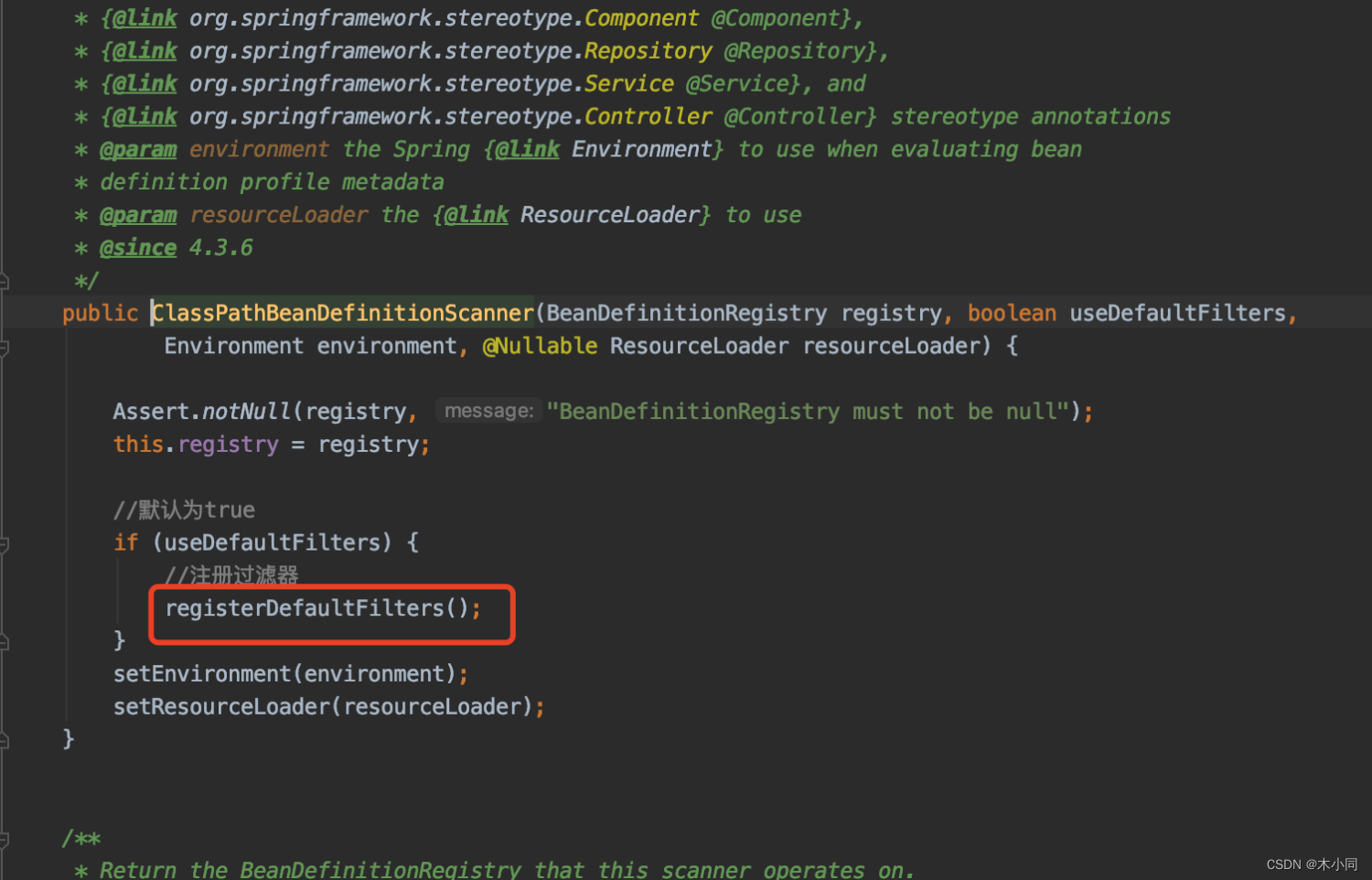
//useDefaultFilters比较重要,这个值默认是true
//意思是判断是否使用默认的过滤器,
/**
* 分为这里面的过滤器有两种,
* 1、include 引入
* 2、exclude 排除
*/
ClassPathBeanDefinitionScanner scanner = new ClassPathBeanDefinitionScanner(this.registry,
componentScan.getBoolean("useDefaultFilters"), this.environment, this.resourceLoader);
/*
判断是否配置有名字生成规则策略器
*/
Class<? extends BeanNameGenerator> generatorClass = componentScan.getClass("nameGenerator");
boolean useInheritedGenerator = (BeanNameGenerator.class == generatorClass);
/*
如果有的话就实例化出来,如果没有的话就使用本身默认的,可配置
*/
scanner.setBeanNameGenerator(useInheritedGenerator ? this.beanNameGenerator :
BeanUtils.instantiateClass(generatorClass));
ScopedProxyMode scopedProxyMode = componentScan.getEnum("scopedProxy");
if (scopedProxyMode != ScopedProxyMode.DEFAULT) {
scanner.setScopedProxyMode(scopedProxyMode);
}
else {
Class<? extends ScopeMetadataResolver> resolverClass = componentScan.getClass("scopeResolver");
scanner.setScopeMetadataResolver(BeanUtils.instantiateClass(resolverClass));
}
scanner.setResourcePattern(componentScan.getString("resourcePattern"));
//判断你的ComponentScan注解中是否配置了 includeFilters,有的话就加入过滤器中
for (AnnotationAttributes filter : componentScan.getAnnotationArray("includeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addIncludeFilter(typeFilter);
}
}
//判断你的ComponentScan注解中是否配置了 excludeFilters,有的话就排除某个类的规则加入过滤器中
for (AnnotationAttributes filter : componentScan.getAnnotationArray("excludeFilters")) {
for (TypeFilter typeFilter : typeFiltersFor(filter)) {
scanner.addExcludeFilter(typeFilter);
}
}
//是否会懒加载
boolean lazyInit = componentScan.getBoolean("lazyInit");
if (lazyInit) {
scanner.getBeanDefinitionDefaults().setLazyInit(true);
}
//获取用户配置的扫描路径
//集合是因为可以配置多个
Set<String> basePackages = new LinkedHashSet<>();
String[] basePackagesArray = componentScan.getStringArray("basePackages");
for (String pkg : basePackagesArray) {
String[] tokenized = StringUtils.tokenizeToStringArray(this.environment.resolvePlaceholders(pkg),
ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS);
Collections.addAll(basePackages, tokenized);
}
for (Class<?> clazz : componentScan.getClassArray("basePackageClasses")) {
basePackages.add(ClassUtils.getPackageName(clazz));
}
if (basePackages.isEmpty()) {
basePackages.add(ClassUtils.getPackageName(declaringClass));
}
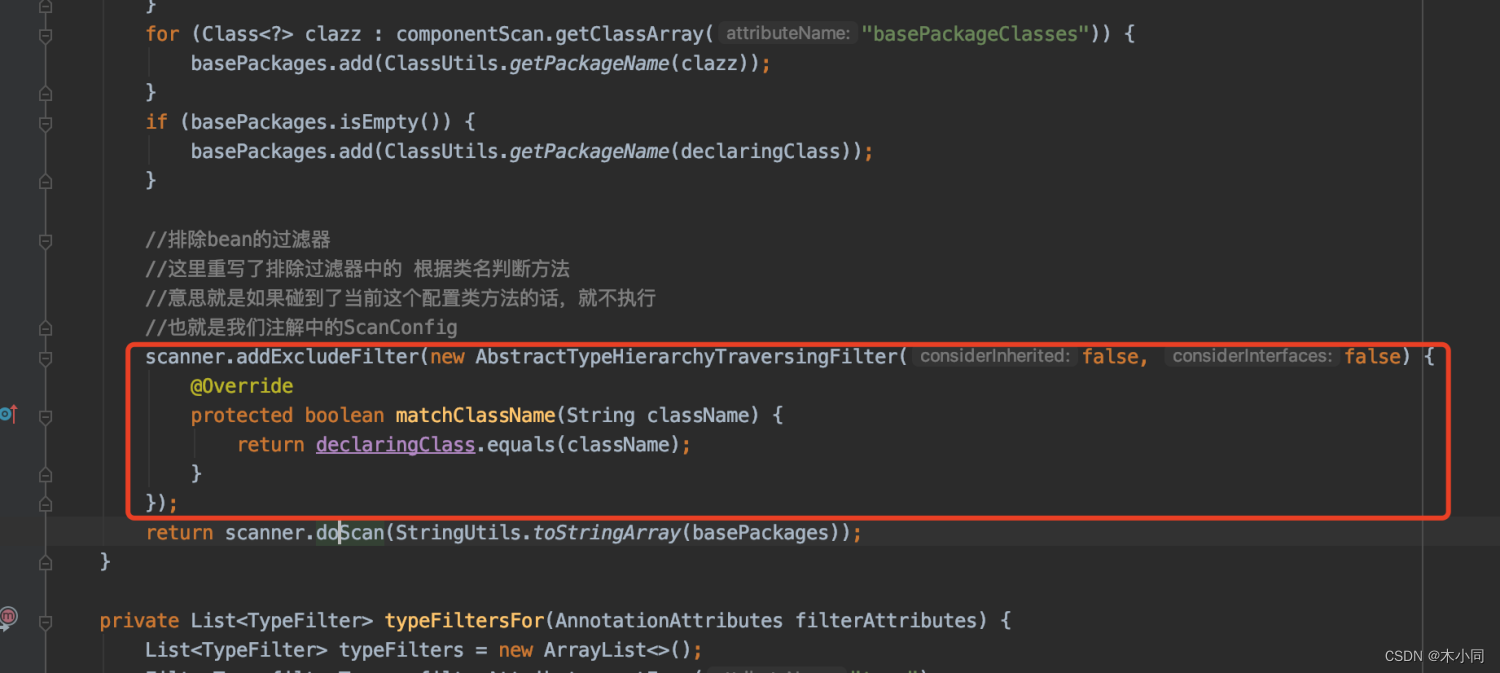
//排除bean的过滤器
//这里重写了排除过滤器中的 根据类名判断方法
//意思就是如果碰到了当前这个配置类方法的话,就不执行
//也就是我们注解中的ScanConfig
scanner.addExcludeFilter(new AbstractTypeHierarchyTraversingFilter(false, false) {
@Override
protected boolean matchClassName(String className) {
return declaringClass.equals(className);
}
});
return scanner.doScan(StringUtils.toStringArray(basePackages));
}
最终执行doScan()方法进行扫描
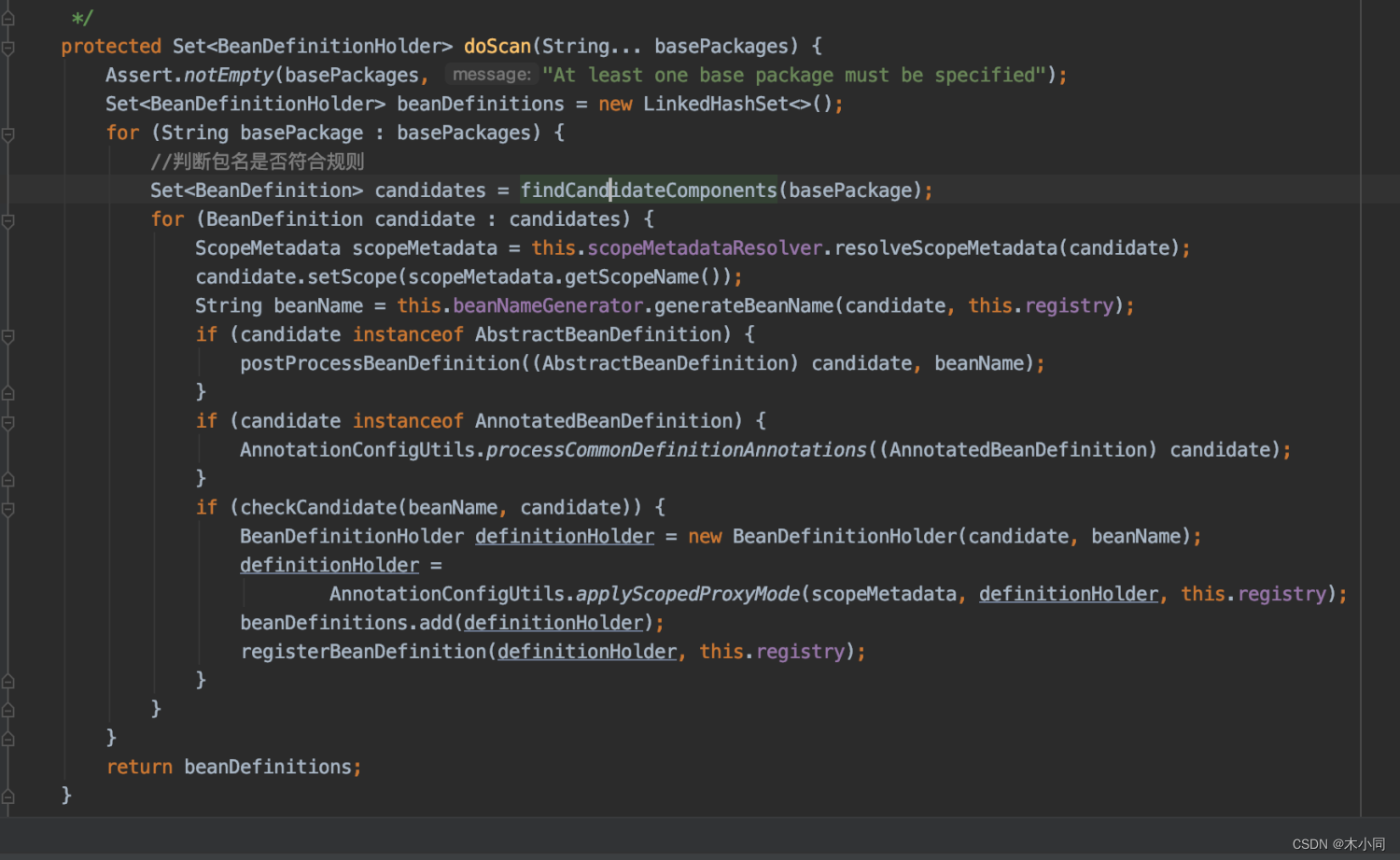

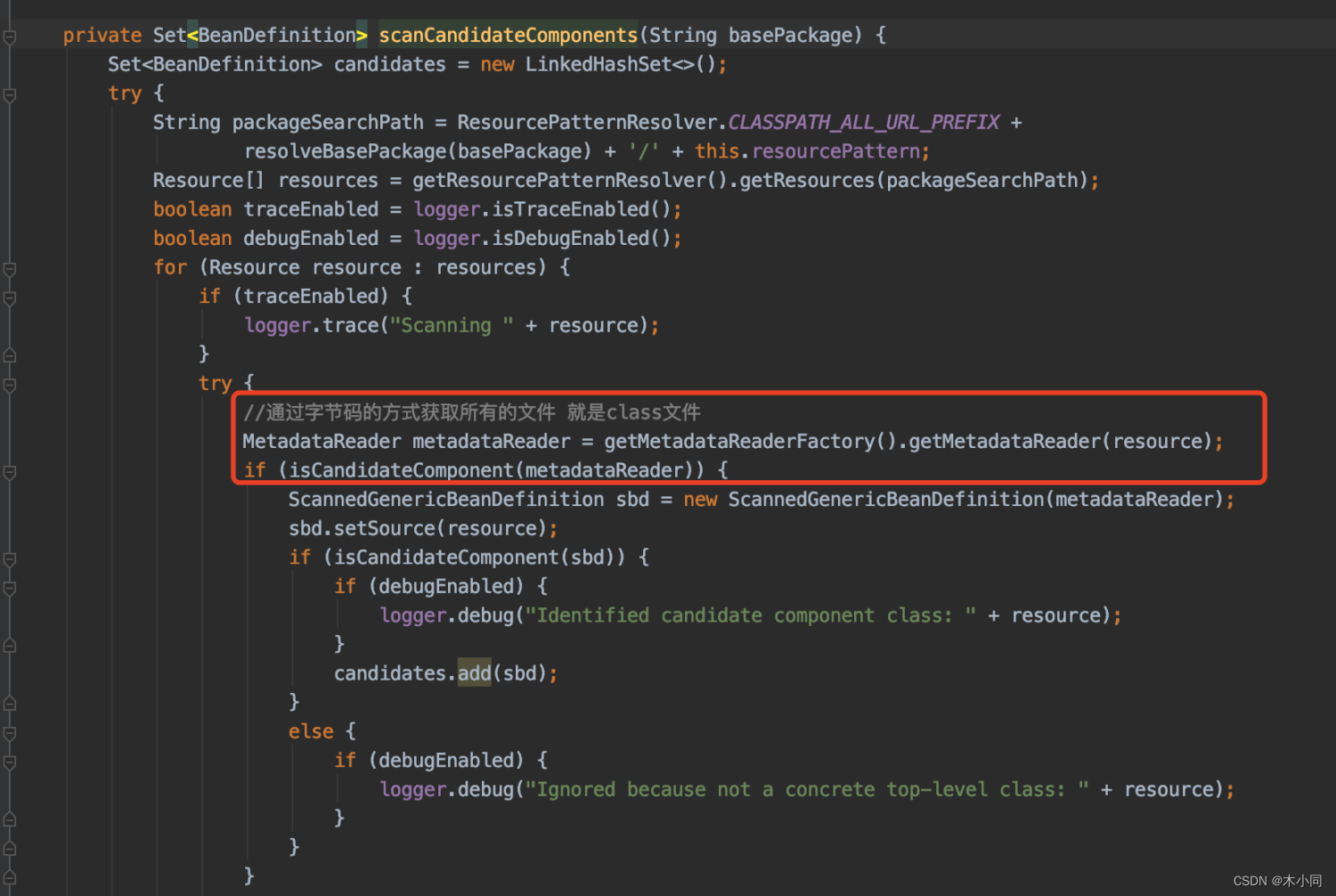
过滤器
扫描器的源码流程就上面那些,需要我们注意的是,其中的过滤器逻辑。
首先解释一下什么是过滤器
在componentScanParser.parse()方法中,配置扫描器的时候,有几行涉及过滤器的方法。
什么是过滤器呢,有两种:
1、包含这个类的话就引入 include
2、包含这个类的话就排除 exclude
在ComponentScan注解配置的时候也能配置这个,并且每个种过滤器中都可以配置多个
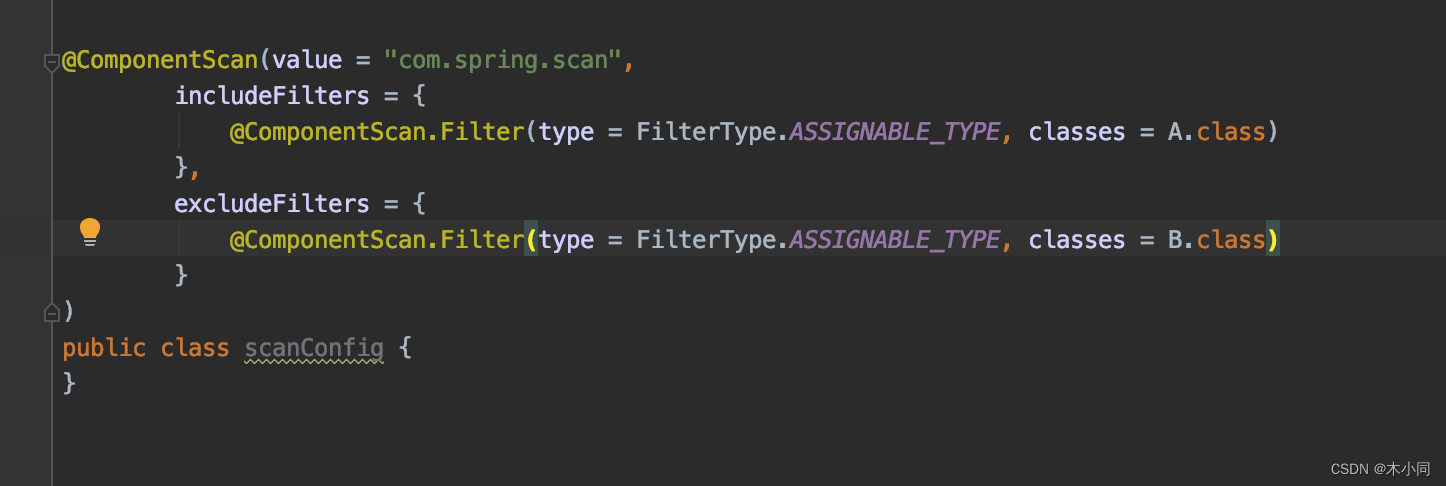
这两个配置的意思就是,
ASSIGNABLE_TYPE:通过类型去过滤,如果是A类的话,就把它扫描了,并且处理它塞入beanDefinitionMap中
ASSIGNABLE_TYPE:通过类型去过滤,如果是B类的话,就排除它,扫描之后的结果就不会有。
排除过滤器的实现原理
在扫描的源码中有个判断,isCandidateComponent()

先循环判断排除过滤器,因为每种过滤器都可能会有多种过滤规则,所以需要循环。
再循环判断包含规则过滤器。
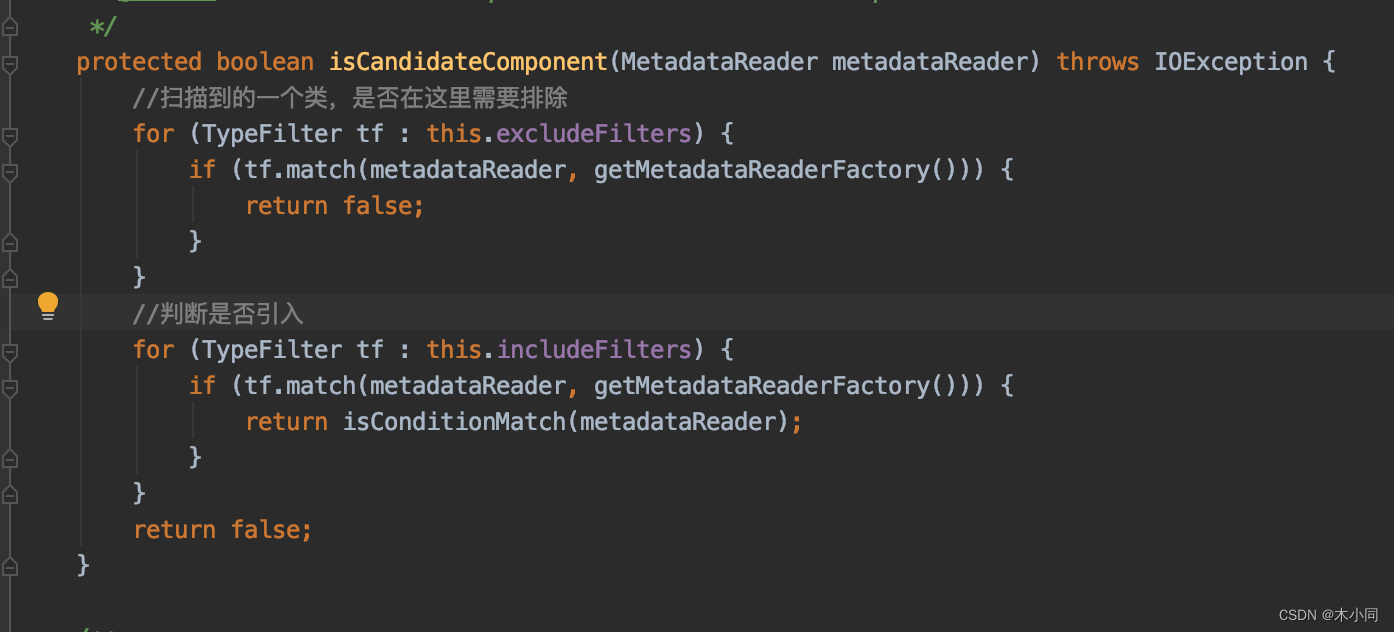
执行判断的具体代码是在这个类里面
AbstractTypeHierarchyTraversingFilter.match()
主要就是这个判断,如果当前是排除过滤器的话,在这里返回true,这个类则不会被引入容器
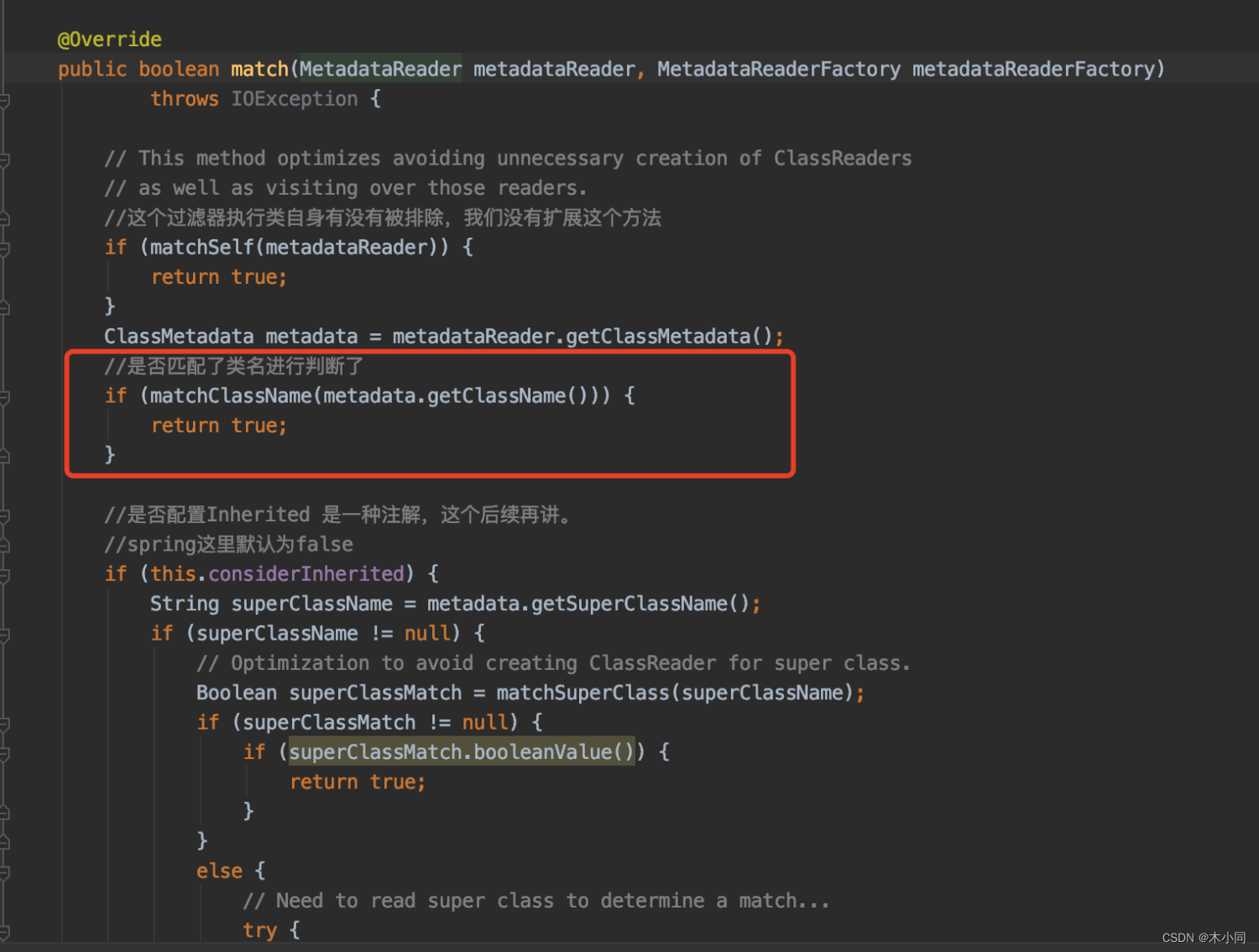
比如在配置扫描器的时候重写了排除过滤器matchClassName()方法,如果当前扫描的类和当前这个配置扫描类相同的话,则放弃,因为既然已经读取到扫描的包了,那么这个配置扫描的类肯定已经在容器中了。
引入过滤器的实现原理
哪怕是不用Component注解,也能在扫描的时候加入spring容器中,就是通过引入过滤器实现的。
而在真正的执行中,不止有我们配置的引入过滤器,还有另外三个,是在这里加入的

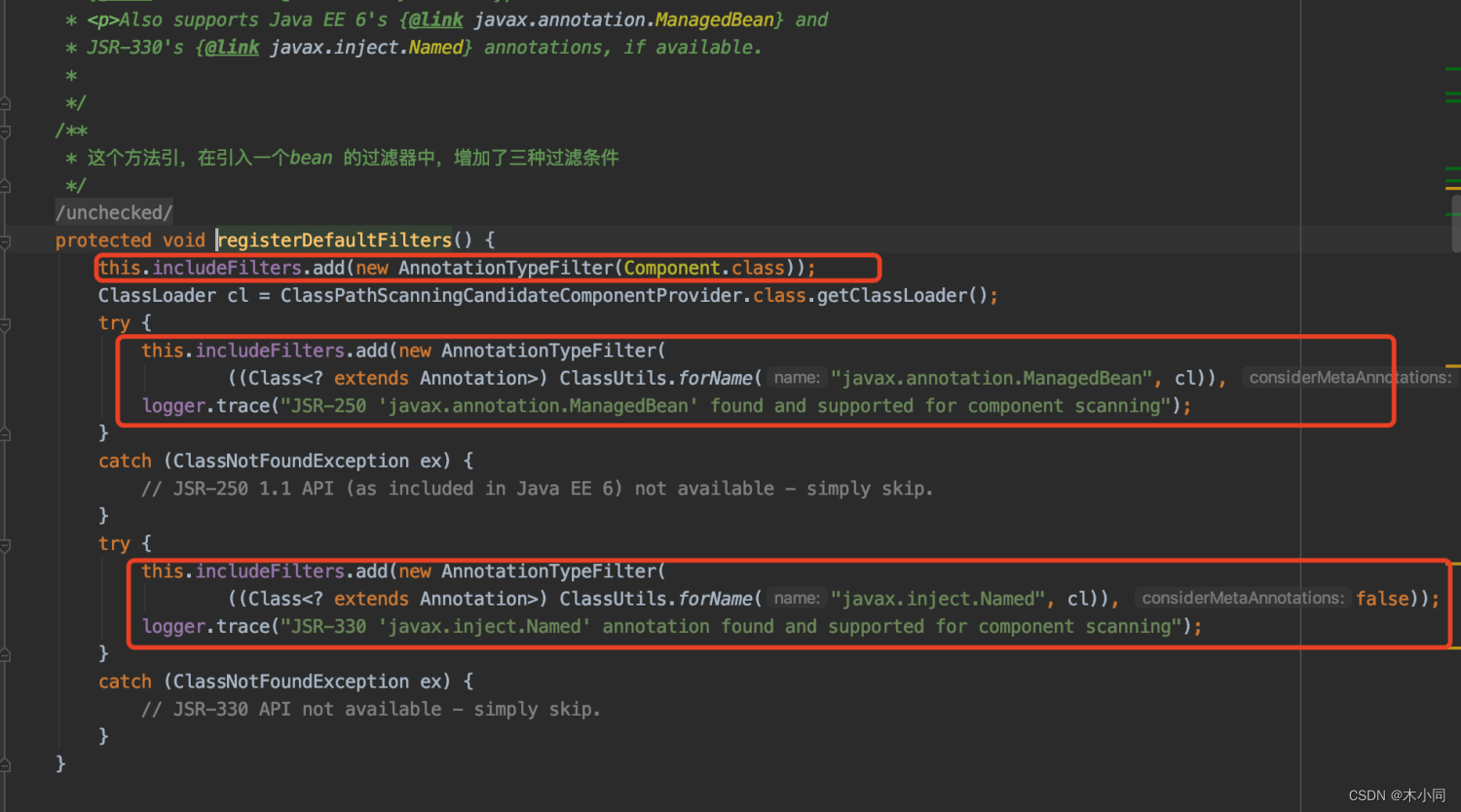
下面我们来分析一下这
三个引入过滤器
1、new AnnotationTypeFilter(Component.class)
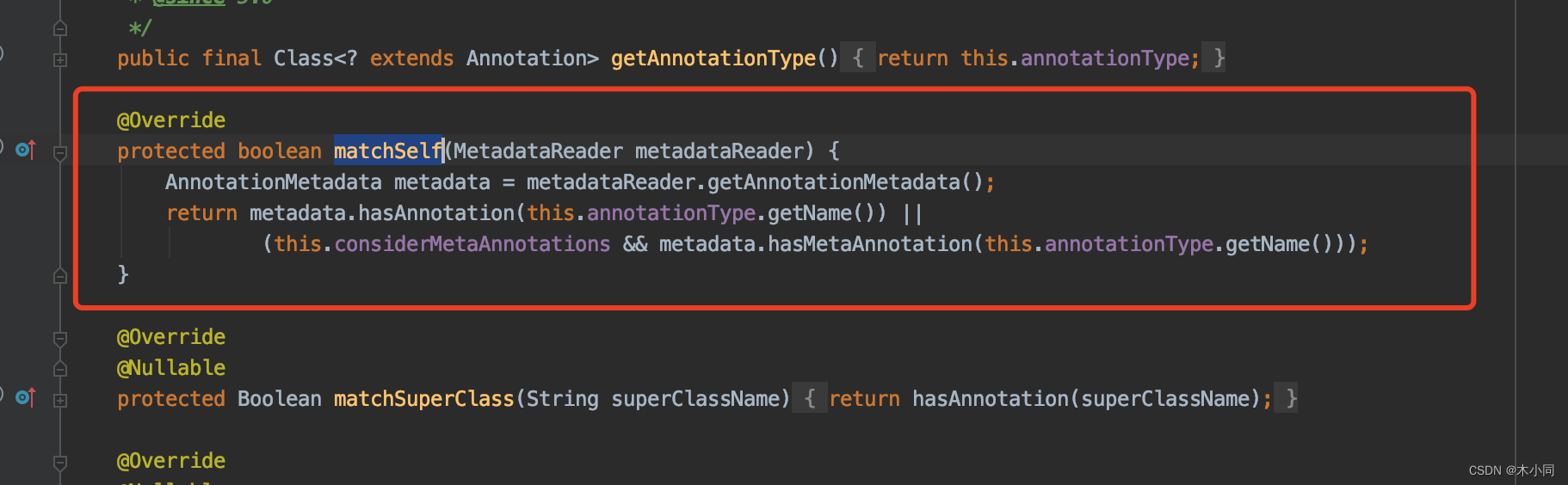
这个类中我们可以看到,重写了过滤器中的matchSelf()方法,也就是说,在过滤器执行的时候,如果到matchSelf()这个方法。就会进这个过滤器的实现。
AbstractTypeHierarchyTraversingFilter.match() – AnnotationTypeFilter.matchSelf()
这里实现了什么呢,判断当前类的注解类是否等于属性annotationType,而这个属性是构造方法中来的,也就是new AnnotationTypeFilter(Component.class) 这个,判断当前类是否加了Component注解。是的话则返回true。
2、new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName(“javax.annotation.ManagedBean”, cl)
这个过滤器等同于new AnnotationTypeFilter(ManagedBean.class),与上一个是同样的类,同样的逻辑。
判断当前类是否加了ManagedBean注解。
这个注解需要解释一下,假如说我们现在有一个小项目,需要把类交给Spring调用,但是又不想引入Spring,就可以之引入javax.inject这个jar包,使用ManagedBean注解来把类托管给spring。
这就是轻量级的JSR
3、new AnnotationTypeFilter(((Class<? extends Annotation>) ClassUtils.forName(“javax.inject.Named”, cl)
这个与上面的也是一样的,判断当前类是否加了Named注解















 1733
1733











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











