










Hive介绍
- facebook开源
- 设计目的:Hive期初是为了提供给那些精通sql但是java编程能力相对较弱的数据工程师能够对facebook上存放的HDFS的大规模数据集进行查询
- Hive是构建在hdfs上的数据仓库框架
- 计算框架为MapReduce
- 数据存储在HDFS
- 适合离线数据处理
- 将HQL转为MR的语言翻译
Hive场景应用举例
- 日志分析
- 统计网站一个时间段内的pv、uv
- 多维度数据分析
- 海量结构化数据离线分析
Hive优缺点
优点
- 易上手
- 提供统一的元数据管理
- 多接口:Beeline,ODBC,JBCD,python,Thrift
- 类sql:类似sql ,提供大量内置函数
- 延展性:用户可根据自己的需求自定义函数
- 良好的容错性,节点出现问题SQL任可继续执行
缺点
- 不支持事务
- 表达能力有限
- 效率比较低
- 调优困难
- 可调控性差
- 延迟较高:默认MR为执行引擎,MR延迟较高
Hive与传统数据库对比
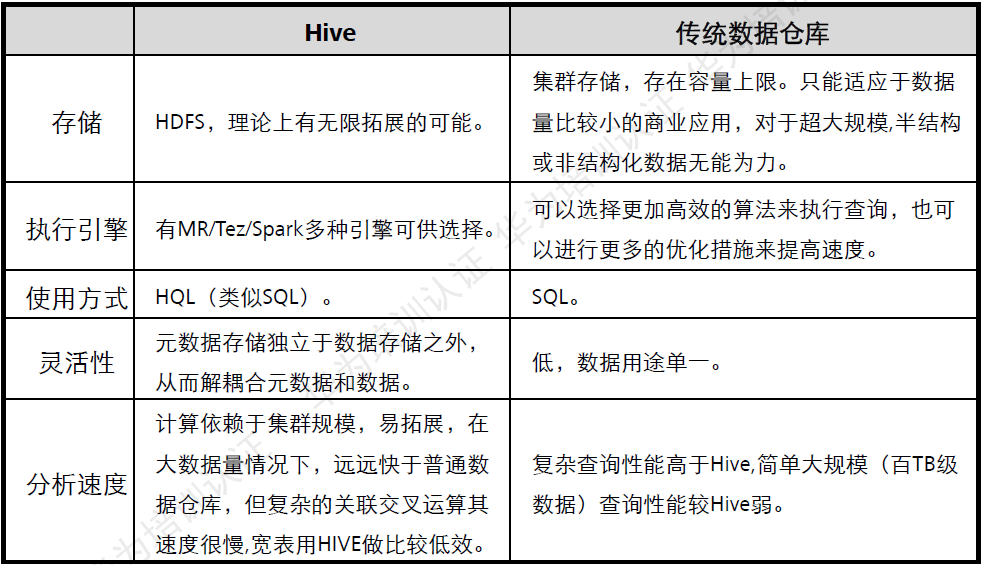
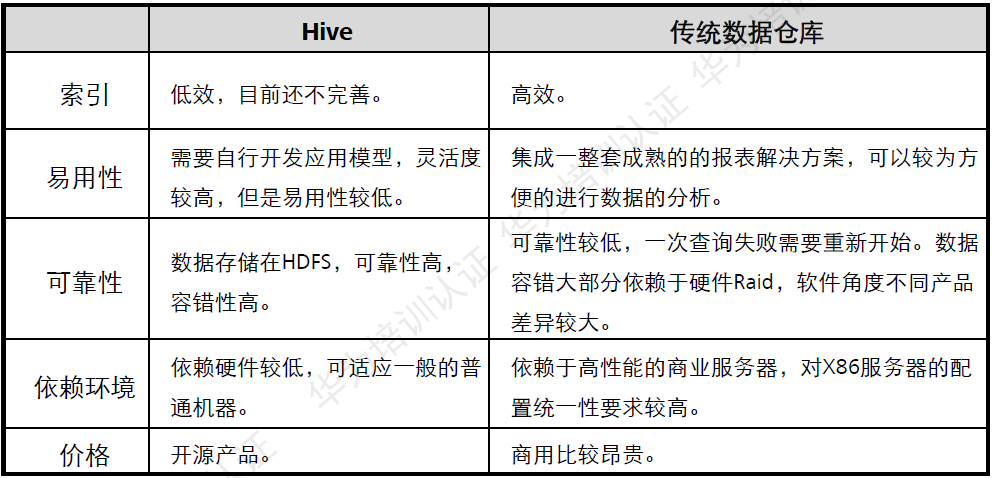
读时模式与写时模式
-
读时模式与写时模式
- 写时模式(传统数据库)
- 描述:在数据写入数据库时,对照模式进行检验
- 优点:在写入时已经对数据列进行索引排序,有利于提升查询速度
- 缺点:加载数据会花费更多时间,在加载模式为确定的情况下,查询条件未知时,不能提前确定会使用何种索引
- 读时模式(Hive)
- 描述:数据在查询时才对数据进行验证
- 优点:数据加载速度快,就是单纯的文件的复制与移动(数据在加载时不会对数据进行解析,序列化,在写入磁盘)
- 缺点:















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









