







 超级会员免费看
超级会员免费看
文章目录
1.Hive介绍
1.1 hive 基本情况
hive基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表。
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
其中Hive中每张表的数据存储在HDFS,Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)并且执行程序运行在yarn上。
1.2 Hive架构原理
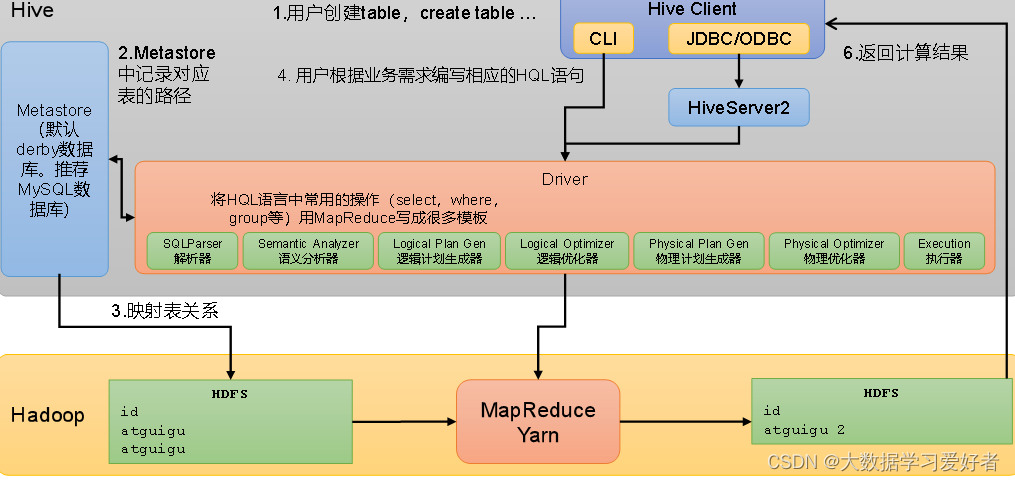
1.metastore 服务:
元数据访问接口,用户创建表的信息,表中的数据信息,数据库对应hdfs路径,表对应hdfs路径的信息。每个字段的类型等等。只提供元数据的访问接口,不保存元数据。
元数据保存在mysql数据库中。
2.Hiveserver2服务:
提供jdbc/odbc的访问的接口。用户认证的接口。
3.cli 命令行端口,远程访问jdbc的接口数据。
用户建表->meta信息对应表的路径信息->mysql 和hdfs的映射关系。文件的数据和hive一行的数据。
4.比如查询,编译和执行的都是在driver中执行。当运行在命令行客户端,driver就在命令行当中,当jdbc客户端hiveserver2的driver运行的hiveserver中。
driver就是讲hive sql转换成mapreduce执行。
driver在编译hivesql 需要使

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 316
316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











