







文章出处:2018 CVPR
作者:Krishna Regmi and Ali Borji
单位:中佛罗里达大学计算机视觉研究中心
1. Motivation
In this paper, we attempt to solve the novel problem of cross-view image synthesis, aerial to street-view and vice versa, using conditional generative adversarial networks(cGAN).
目的:解决跨视角图像生成问题
the challenges pertaining to cross-view synthesis task are as follows:
- 空中图像比街景图像覆盖的地面区域更大,而街景图像比空中图像包含更多有关物体(例如房屋,道路,树木)的细节。因此,不仅航空图像中的信息太嘈杂,而且街景图像合成的信息量也较少。同样地,网络需要估计很多区域以合成航拍图像。
- 瞬态物体(例如汽车(也包括人))不在图像对的相应位置出现,因为它们是在不同的时间拍摄的
- 街景不同的房屋与鸟瞰图相似。这会导致合成的街景图像包含具有相似颜色或纹理的建筑物,从而阻止了生成建筑物的多样性。
- 由于视角和遮挡,在两种视图中道路之间的变化。虽然道路边缘几乎呈直线形,并且在街景视图中可见,但它们通常被茂密的植被遮挡并在鸟瞰图中扭曲。
- 当使用模型生成的分割图作为基础事实来提高生成图像的质量时,标签噪声和模型错误会在结果中引入一些伪像
2. Contribution
- 证明了 conditional GANs广泛的适应性和可解释性
- 提出了一个“Image-to-Image Translation”的通用框架,并分析几个重要架构选择的效果。
3. Introduction
以pix2pix网络为baseline,提出两种 new cGAN network,分别为 X-Fork (对baseline修改,在倒数第二个块处分叉以生成两个输出,即目标视图图像和分割图)和 X-Seq (是具有连接两个baseline network 的序列)
4. Method
- Crossview Fork(X-Fork)
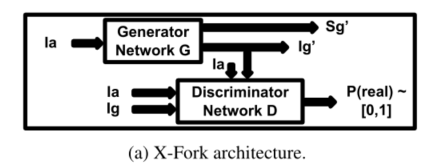
上图为本文所提出的 X-Fork 架构,其中判别器D是依据pix2pix 的baseline,生成器G 有两个分支,用以合成图像及分割图像。
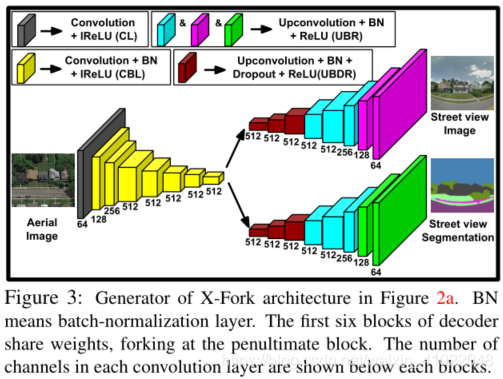
上图为X-Fork 架构的生成器G结构图,前六个解码器共享权重(image与其分割图有很多相同特征),生成器G 中每个块中使用的卷积核数在该块对应下方。 - Crossview Sequential (X-Seq)
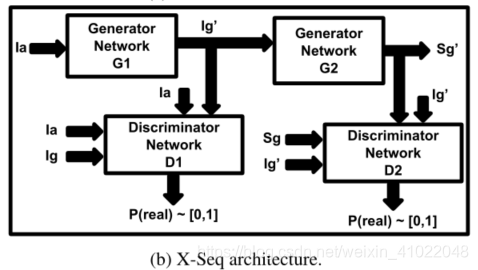
上图为本文所提出的 X-Sep 架构,用了两个 cGAN 网络。第一个网络生成的 cross-view image 类似于 baselin,在同一视角下第二个网络将第一个网络的输出图作为条件输入用以合成分割图。因此,第一个网络是 跨视角 cGAN,第二个则是 图像–分割图 cGAN。整个网络结构是训练 end-to-end ,为了让两个 cGAN 同时学习。
优势:通过训练第一个网络来生成更好的 cross-view images ,在经由第二个生成器更好地增强了输出的分割图。两个子网络串联,第二个网络的反馈会强制第一个网络不断地改善生成输出,已达到更好的效果。
- 损失函数



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









