







前言
尽管通过如下命令分别产生了vcd波形文件和逐条指令的csv文件:
# 导出vcd波形文件
./ci/blackbox.sh --driver=rtlsim --app=demo --debug=1
# 导出逐条指令的csv文件
./ci/trace_csv.py -trtlsim run.log -otrace_rtlsim.csv
但在看波形前,还是先确认blackbox.sh文件和trace_csv.py文件分别哪个源文件通过什么样的选项限制得到波形文件。
一、./build/ci下的文件结构
./build/ci下的文件结构如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/ci$ tree
.
├── blackbox.sh
├── datagen.py
├── install_dependencies.sh
├── regression.sh
├── toolchain_env.sh
├── toolchain_install.sh
├── toolchain_prebuilt.sh
├── trace_csv.py
└── travis_run.py
0 directories, 9 files
二、基于驱动进行仿真过程牵扯的文件
2.1 blackbox.sh文件
blackbox.sh文件内容如下,一点点分析,首先是show_usage()和show_help()函数:
show_usage()
{
echo "Vortex BlackBox Test Driver v1.0"
echo "Usage: $0 [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]"
}
show_help()
{
show_usage
echo " where"
echo "--driver: gpu, simx, rtlsim, oape, xrt"
echo "--app: any subfolder test under regression or opencl"
echo "--class: 0=disable, 1=pipeline, 2=memsys"
echo "--rebuild: 0=disable, 1=force, 2=auto, 3=temp"
}
功能相同,都用于显示脚本的基本使用方法,测一下:
# 测试show_help()的功能
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --help
Vortex BlackBox Test Driver v1.0
Usage: ./ci/blackbox.sh [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]
where
--driver: gpu, simx, rtlsim, oape, xrt
--app: any subfolder test under regression or opencl
--class: 0=disable, 1=pipeline, 2=memsys
--rebuild: 0=disable, 1=force, 2=auto, 3=temp
# 测试show_usage()的功能
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --invalid-option
Vortex BlackBox Test Driver v1.0
Usage: ./ci/blackbox.sh [[--clusters=#n] [--cores=#n] [--warps=#n] [--threads=#n] [--l2cache] [--l3cache] [[--driver=#name] [--app=#app] [--args=#args] [--debug=#level] [--scope] [--perf=#class] [--rebuild=#n] [--log=logfile] [--help]]
接下来是初始化变量:
SCRIPT_DIR=$(dirname "$0") # 获取脚本所在目录
ROOT_DIR=$SCRIPT_DIR/.. # 设置所在目录为根目录
# 以下变量和show_help()相对应
DRIVER=simx
APP=sgemm
CLUSTERS=1
CORES=1
WARPS=4
THREADS=4
L2=
L3=
DEBUG=0
DEBUG_LEVEL=0
SCOPE=0
HAS_ARGS=0
PERF_CLASS=0
REBUILD=2
TEMPBUILD=0
LOGFILE=run.log
然后是解析紧跟着./ci/blackbox.sh后的参数:
for i in "$@"
do
case $i in
--driver=*)
DRIVER=${i#*=}
shift
;;
--app=*)
APP=${i#*=}
shift
;;
--clusters=*)
CLUSTERS=${i#*=}
shift
;;
--cores=*)
CORES=${i#*=}
shift
;;
--warps=*)
WARPS=${i#*=}
shift
;;
--threads=*)
THREADS=${i#*=}
shift
;;
--l2cache)
L2=-DL2_ENABLE
shift
;;
--l3cache)
L3=-DL3_ENABLE
shift
;;
--debug=*)
DEBUG_LEVEL=${i#*=}
DEBUG=1
shift
;;
--scope)
SCOPE=1
CORES=1
shift
;;
--perf=*)
PERF_FLAG=-DPERF_ENABLE
PERF_CLASS=${i#*=}
shift
;;
--args=*)
ARGS=${i#*=}
HAS_ARGS=1
shift
;;
--rebuild=*)
REBUILD=${i#*=}
shift
;;
--log=*)
LOGFILE=${i#*=}
shift
;;
--help)
show_help
exit 0
;;
*)
show_usage
exit -1
;;
esac
done
其中上述的解析种--help和*分别指向了前面测试show_help()和show_usage()功能的方法。
然后就是设置驱动测试程序:
case $DRIVER in
gpu)
DRIVER_PATH=
;;
simx)
DRIVER_PATH=$ROOT_DIR/runtime/simx
;;
rtlsim)
DRIVER_PATH=$ROOT_DIR/runtime/rtlsim
;;
opae)
DRIVER_PATH=$ROOT_DIR/runtime/opae
;;
xrt)
DRIVER_PATH=$ROOT_DIR/runtime/xrt
;;
*)
echo "invalid driver: $DRIVER"
exit -1
;;
esac
其中./runtime下的文件如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/runtime$ ls
common.mk librtlsim.so libvortex-opae.so libvortex.so libxrtsim.so.obj_dir rtlsim vortex_afu.h
libopae-c-sim.so librtlsim.so.obj_dir libvortex-rtlsim.so libvortex-xrt.so Makefile simx xrt
libopae-c-sim.so.obj_dir libsimx.so libvortex-simx.so libxrtsim.so opae stub
除了gpu这个驱动选项外,可以比较好的对应起来!
然后是配置应用的路径:
if [ -d "$ROOT_DIR/tests/opencl/$APP" ];
then
APP_PATH=$ROOT_DIR/tests/opencl/$APP
elif [ -d "$ROOT_DIR/tests/regression/$APP" ];
then
APP_PATH=$ROOT_DIR/tests/regression/$APP
else
echo "Application folder not found: $APP"
exit -1
fi
可以发现这里限制了测试用例的路径为./tests/regression和./tests/opencl,看了./tests下的其他文件夹:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests$ ls
kernel Makefile opencl regression riscv unittest
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/regression$ ls
basic common.mk conv3x demo diverge dogfood fence io_addr Makefile matmul mstress printf sgemm2x sgemmx sort stencil3d vecaddx
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/opencl$ ls
bfs common.mk dotproduct kmeans Makefile oclprintf psum sfilter sgemm2 spmv transpose
blackscholes conv3 guassian lbm nearn psort saxpy sgemm sgemm3 stencil vecadd
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/kernel$ ls
common.mk conform fibonacci hello Makefile
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/unittest$ ls
common.mk Makefile vx_malloc
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/riscv$ ls
benchmarks_32 benchmarks_64 common.mk isa Makefile riscv-vector-tests
从kernel、riscv的测试用例文件名中大致可以推测,应该也可能可以对这俩文件夹下的测试用例进行测试。咱不妨尝试对比一下./opencl/Makefile和./regression/Makefile:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests$ diff ./opencl/Makefile ./regression/Makefile
5,24c5,18
< $(MAKE) -C vecadd
< $(MAKE) -C sgemm
... # 省略一部分
< $(MAKE) -C blackscholes
< $(MAKE) -C bfs
---
> $(MAKE) -C basic
> $(MAKE) -C demo
... # 省略一部分
> $(MAKE) -C sgemm2x
> $(MAKE) -C stencil3d
27,45c21,34
< $(MAKE) -C vecadd run-simx
< $(MAKE) -C sgemm run-simx
... # 省略一部分
< $(MAKE) -C blackscholes run-simx
< $(MAKE) -C bfs run-simx
---
> $(MAKE) -C basic run-simx
> $(MAKE) -C demo run-simx
... # 省略一部分
> $(MAKE) -C sgemm2x run-simx
> $(MAKE) -C stencil3d run-simx
48,66c37,50
< $(MAKE) -C vecadd run-rtlsim
< $(MAKE) -C sgemm run-rtlsim
... # 省略一部分
< $(MAKE) -C blackscholes run-rtlsim
< $(MAKE) -C bfs run-rtlsim
---
> $(MAKE) -C basic run-rtlsim
> $(MAKE) -C demo run-rtlsim
... # 省略一部分
> $(MAKE) -C sgemm2x run-rtlsim
> $(MAKE) -C stencil3d run-rtlsim
69,88c53,66
< $(MAKE) -C vecadd clean
< $(MAKE) -C sgemm clean
... # 省略一部分
< $(MAKE) -C blackscholes clean
< $(MAKE) -C bfs clean
\ No newline at end of file
---
> $(MAKE) -C basic clean
> $(MAKE) -C demo clean
... # 省略一部分
> $(MAKE) -C sgemm2x clean
> $(MAKE) -C stencil3d clean
\ No newline at end of file
从以上差异可以看出./opencl/Makefile和./regression/Makefile仅支持simx和rtlsim这两种模式。此外./kernel/Makefile和./riscv/Makefile也仅支持simx和rtlsim,估计应该可以设置opae和xrt这两种选项,不过实际上执行./ci/blackbox.sh --driver=opae和./ci/blackbox.sh --driver=xrt可以直接运行出结果。结果如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=opae
Running: make -C ./ci/../runtime/opae > /dev/null
Running: make -C ./ci/../tests/opencl/sgemm run-opae
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
SCOPE_JSON_PATH=/home/dention/Desktop/vortex/vortex/build/runtime/scope.json OPAE_DRV_PATHS=libopae-c-sim.so LD_LIBRARY_PATH=/home/dention/tools/pocl/lib:/home/dention/Desktop/vortex/vortex/build/runtime:/home/dention/tools/llvm-vortex/lib:/lib/x86_64-linux-gnu/: POCL_VORTEX_XLEN=32 LLVM_PREFIX=/home/dention/tools/llvm-vortex POCL_VORTEX_BINTOOL="OBJCOPY=/home/dention/tools/llvm-vortex/bin/llvm-objcopy /home/dention/Desktop/vortex/vortex/kernel/scripts/vxbin.py" POCL_VORTEX_CFLAGS="-march=rv32imaf -mabi=ilp32f -O3 -mcmodel=medany --sysroot=/home/dention/tools/riscv32-gnu-toolchain/riscv32-unknown-elf --gcc-toolchain=/home/dention/tools/riscv32-gnu-toolchain -fno-rtti -fno-exceptions -nostartfiles -nostdlib -fdata-sections -ffunction-sections -I/home/dention/Desktop/vortex/vortex/build/hw -I/home/dention/Desktop/vortex/vortex/kernel/include -DXLEN_32 -DNDEBUG -Xclang -target-feature -Xclang +vortex -Xclang -target-feature -Xclang +zicond -mllvm -disable-loop-idiom-all " POCL_VORTEX_LDFLAGS="-Wl,-Bstatic,--gc-sections,-T/home/dention/Desktop/vortex/vortex/kernel/scripts/link32.ld,--defsym=STARTUP_ADDR=0x80000000 /home/dention/Desktop/vortex/vortex/build/kernel/libvortex.a -L/home/dention/tools/libc32/lib -lm -lc /home/dention/tools/libcrt32/lib/baremetal/libclang_rt.builtins-riscv32.a" VORTEX_DRIVER=opae ./sgemm -n32
Workload size=32
CONFIGS: num_threads=4, num_warps=4, num_cores=1, num_clusters=1, socket_size=1, local_mem_base=0xffff0000, num_barriers=2
Create context
Create program from kernel source
Upload source buffers
Execute the kernel
Elapsed time: 14155 ms
Download destination buffer
Verify result
PASSED!
PERF: instrs=289393, cycles=159694, IPC=1.812172
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=xrt
Running: make -C ./ci/../runtime/xrt > /dev/null
Running: make -C ./ci/../tests/opencl/sgemm run-xrt
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
SCOPE_JSON_PATH=/home/dention/Desktop/vortex/vortex/build/runtime/scope.json LD_LIBRARY_PATH=/lib:/home/dention/tools/pocl/lib:/home/dention/Desktop/vortex/vortex/build/runtime:/home/dention/tools/llvm-vortex/lib:/lib/x86_64-linux-gnu/: POCL_VORTEX_XLEN=32 LLVM_PREFIX=/home/dention/tools/llvm-vortex POCL_VORTEX_BINTOOL="OBJCOPY=/home/dention/tools/llvm-vortex/bin/llvm-objcopy /home/dention/Desktop/vortex/vortex/kernel/scripts/vxbin.py" POCL_VORTEX_CFLAGS="-march=rv32imaf -mabi=ilp32f -O3 -mcmodel=medany --sysroot=/home/dention/tools/riscv32-gnu-toolchain/riscv32-unknown-elf --gcc-toolchain=/home/dention/tools/riscv32-gnu-toolchain -fno-rtti -fno-exceptions -nostartfiles -nostdlib -fdata-sections -ffunction-sections -I/home/dention/Desktop/vortex/vortex/build/hw -I/home/dention/Desktop/vortex/vortex/kernel/include -DXLEN_32 -DNDEBUG -Xclang -target-feature -Xclang +vortex -Xclang -target-feature -Xclang +zicond -mllvm -disable-loop-idiom-all " POCL_VORTEX_LDFLAGS="-Wl,-Bstatic,--gc-sections,-T/home/dention/Desktop/vortex/vortex/kernel/scripts/link32.ld,--defsym=STARTUP_ADDR=0x80000000 /home/dention/Desktop/vortex/vortex/build/kernel/libvortex.a -L/home/dention/tools/libc32/lib -lm -lc /home/dention/tools/libcrt32/lib/baremetal/libclang_rt.builtins-riscv32.a" VORTEX_DRIVER=xrt ./sgemm -n32
Workload size=32
CONFIGS: num_threads=4, num_warps=4, num_cores=1, num_clusters=1, socket_size=1, local_mem_base=0xffff0000, num_barriers=2
info: device name=vortex_xrtsim, memory_capacity=0x100000000 bytes, memory_banks=2.
Create context
Create program from kernel source
Upload source buffers
allocating bank0...
reusing bank0...
Execute the kernel
reusing bank0...
reusing bank0...
allocating bank1...
Elapsed time: 12817 ms
Download destination buffer
Verify result
PASSED!
freeing bank0...
freeing bank1...
allocating bank0...
PERF: instrs=289393, cycles=159485, IPC=1.814547
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
(有点意思的是,这俩cycles不一样,为后续探索多了点理由!!!!)
此外,以下这段可以接着修改:
if [ -d "$ROOT_DIR/tests/opencl/$APP" ];
then
APP_PATH=$ROOT_DIR/tests/opencl/$APP
elif [ -d "$ROOT_DIR/tests/regression/$APP" ];
then
APP_PATH=$ROOT_DIR/tests/regression/$APP
else
echo "Application folder not found: $APP"
exit -1
fi
||
||
\/
## 加入除了opencl和regression之外的kernel和riscv
# kernel支持的APP包括:conform hello fibonacci
# riscv支持的APP包括:benchmarks_${XLEN}
# opencl支持的APP包括:fs dotproduct kmeans oclprintf psum sfilter sgemm2 spmv transpose blackscholes conv3 guassian lbm nearn psort saxpy sgemm sgemm3 stencil vecadd
# regression支持的APP包括:basic conv3x demo diverge dogfood fence io_addr matmul mstress printf sgemm2x sgemmx sort stencil3d vecaddx
# 默认的设置:DRIVER=simx APP=sgemm
接下来是运行应用:
if [ "$DRIVER" = "gpu" ];
then
# running application
if [ $HAS_ARGS -eq 1 ]
then
echo "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER"
OPTS=$ARGS make -C $APP_PATH run-$DRIVER
status=$?
else
echo "running: make -C $APP_PATH run-$DRIVER"
make -C $APP_PATH run-$DRIVER
status=$?
fi
exit $status
fi
插入一次测试,由于笔记本并不支持NVIDIA GPU,但还是测了一下,不出意外,塌方了:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=gpu
Running: make -C ./ci/../tests/opencl/sgemm run-gpu
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
g++ -std=c++17 -Wall -Wextra -Wfatal-errors -Wno-deprecated-declarations -Wno-unused-parameter -Wno-narrowing -pthread -I/home/dention/tools/pocl/include -O2 -DNDEBUG main.cc.o -Wl,-rpath,/home/dention/tools/llvm-vortex/lib -lOpenCL -o sgemm.host
/usr/bin/ld: cannot find -lOpenCL: No such file or directory
collect2: error: ld returned 1 exit status
make: *** [../common.mk:88: sgemm.host] Error 1
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
看着error是链接阶段找不到-lOpenCL库,开始检查:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ldconfig -p | grep OpenCL
libOpenCL.so.1 (libc6,x86-64) => /lib/x86_64-linux-gnu/libOpenCL.so.1
这说明有库但没链接上,想了想可能是pkg-config没有正确配置OpenCL库。
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ pkg-config --libs OpenCL
Package OpenCL was not found in the pkg-config search path.
Perhaps you should add the directory containing `OpenCL.pc'
to the PKG_CONFIG_PATH environment variable
No package 'OpenCL' found
所以接下来就是:
sudo apt-get install pkg-config opencl-headers ocl-icd-opencl-dev
export LD_LIBRARY_PATH=/lib/x86_64-linux-gnu/:$LD_LIBRARY_PATH
export LDFLAGS="-L/lib/x86_64-linux-gnu/ -lOpenCL"
export CPPFLAGS="-I/home/dention/tools/pocl/include"
然后:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build$ ./ci/blackbox.sh --driver=gpu
Running: make -C ./ci/../tests/opencl/sgemm run-gpu
make: Entering directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
./sgemm.host -n32
Workload size=32
OpenCL Error: 'clGetPlatformIDs(1, &platform_id, NULL)' returned -1001!
make: *** [../common.mk:91: run-gpu] Error 255
make: Leaving directory '/home/dention/Desktop/vortex/vortex/build/tests/opencl/sgemm'
能输出Workload size=32的信息,只是说相关的设备没找到,大概率就是没匹配到gpu版本的opencv,因此报错。有条件的可以试试!
接下来是配置和构建:
CONFIGS="-DNUM_CLUSTERS=$CLUSTERS -DNUM_CORES=$CORES -DNUM_WARPS=$WARPS -DNUM_THREADS=$THREADS $L2 $L3 $PERF_FLAG $CONFIGS"
echo "CONFIGS=$CONFIGS"
if [ $REBUILD -ne 0 ]
then
BLACKBOX_CACHE=blackbox.$DRIVER.cache
if [ -f "$BLACKBOX_CACHE" ]
then
LAST_CONFIGS=`cat $BLACKBOX_CACHE`
fi
if [ $REBUILD -eq 1 ] || [ "$CONFIGS+$DEBUG+$SCOPE" != "$LAST_CONFIGS" ];
then
make -C $DRIVER_PATH clean-driver > /dev/null
echo "$CONFIGS+$DEBUG+$SCOPE" > $BLACKBOX_CACHE
fi
fi
根据用户指定的配置(如集群数、核心数等),生成CONFIGS字符串。如果REBUILD不为0,脚本会检查是否需要重新构建驱动程序。如果配置发生变化或用户强制重新构建,脚本会清理旧的构建文件并重新构建。
接下来是运行应用:
if [ $DEBUG -ne 0 ]
then
# running application
if [ $TEMPBUILD -eq 1 ]
then
# setup temp directory
TEMPDIR=$(mktemp -d)
mkdir -p "$TEMPDIR/$DRIVER"
# driver initialization
if [ $SCOPE -eq 1 ]
then
echo "running: DESTDIR=$TEMPDIR/$DRIVER DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DESTDIR="$TEMPDIR/$DRIVER" DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
else
echo "running: DESTDIR=$TEMPDIR/$DRIVER DEBUG=$DEBUG_LEVEL CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DESTDIR="$TEMPDIR/$DRIVER" DEBUG=$DEBUG_LEVEL CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
fi
# running application
if [ $HAS_ARGS -eq 1 ]
then
echo "running: VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"
DEBUG=1 VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1
status=$?
else
echo "running: VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"
DEBUG=1 VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1
status=$?
fi
# cleanup temp directory
trap "rm -rf $TEMPDIR" EXIT
else
# driver initialization
if [ $SCOPE -eq 1 ]
then
echo "running: DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DEBUG=$DEBUG_LEVEL SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
else
echo "running: DEBUG=$DEBUG_LEVEL CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DEBUG=$DEBUG_LEVEL CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
fi
# running application
if [ $HAS_ARGS -eq 1 ]
then
echo "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"
DEBUG=1 OPTS=$ARGS make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1
status=$?
else
echo "running: make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1"
DEBUG=1 make -C $APP_PATH run-$DRIVER > $LOGFILE 2>&1
status=$?
fi
fi
if [ -f "$APP_PATH/trace.vcd" ]
then
mv -f $APP_PATH/trace.vcd .
fi
else
if [ $TEMPBUILD -eq 1 ]
then
# setup temp directory
TEMPDIR=$(mktemp -d)
mkdir -p "$TEMPDIR/$DRIVER"
# driver initialization
if [ $SCOPE -eq 1 ]
then
echo "running: DESTDIR=$TEMPDIR/$DRIVER SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DESTDIR="$TEMPDIR/$DRIVER" SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
else
echo "running: DESTDIR=$TEMPDIR/$DRIVER CONFIGS=$CONFIGS make -C $DRIVER_PATH"
DESTDIR="$TEMPDIR/$DRIVER" CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
fi
# running application
if [ $HAS_ARGS -eq 1 ]
then
echo "running: VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER"
VORTEX_RT_PATH=$TEMPDIR OPTS=$ARGS make -C $APP_PATH run-$DRIVER
status=$?
else
echo "running: VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER"
VORTEX_RT_PATH=$TEMPDIR make -C $APP_PATH run-$DRIVER
status=$?
fi
# cleanup temp directory
trap "rm -rf $TEMPDIR" EXIT
else
# driver initialization
if [ $SCOPE -eq 1 ]
then
echo "running: SCOPE=1 CONFIGS=$CONFIGS make -C $DRIVER_PATH"
SCOPE=1 CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
else
echo "running: CONFIGS=$CONFIGS make -C $DRIVER_PATH"
CONFIGS="$CONFIGS" make -C $DRIVER_PATH > /dev/null
fi
# running application
if [ $HAS_ARGS -eq 1 ]
then
echo "running: OPTS=$ARGS make -C $APP_PATH run-$DRIVER"
OPTS=$ARGS make -C $APP_PATH run-$DRIVER
status=$?
else
echo "running: make -C $APP_PATH run-$DRIVER"
make -C $APP_PATH run-$DRIVER
status=$?
fi
fi
fi
exit $status
具体功能可以分为三点:
1、如果启用了调试模式(DEBUG=1),脚本会根据配置运行应用,并将输出保存到日志文件中。
2、如果启用了临时构建(TEMPBUILD=1),脚本会创建一个临时目录来构建和运行应用,运行完成后清理临时目录。
3、如果未启用调试模式,脚本会直接运行应用。
以上blackbox.sh已经从blackbox变成whitebox了,咱先告一个段落!
2.2 demo文件
这个文件直接和波形挂钩,或者说直接和指令挂钩,为了看明白RTL代码,该文件绕不开。
在编译之前,./demo的文件内容如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/tests/regression/demo$ tree
.
├── common.h
├── kernel.cpp
├── main.cpp
└── Makefile
0 directories, 4 files
而在编译之后,./demo的文件内容如下:
dention@dention-virtual-machine:~/Desktop/vortex/vortex/build/tests/regression/demo$ tree
.
├── demo
├── kernel.dump
├── kernel.elf
├── kernel.vxbin
├── Makefile
├── ramulator.stats.log
└── trace
├── ramulator.log.ch0
└── ramulator.log.ch1
1 directory, 8 files
其中ramulator.stats.log根据文件名,结合2.3.3的1可以判断是通过ramulator输出的日志文件,其内容如下:
Frontend:
impl: GEM5
MemorySystem:
impl: GenericDRAM
total_num_other_requests: 0
total_num_write_requests: 7372
total_num_read_requests: 1480
memory_system_cycles: 22034
DRAM:
impl: HBM2
AddrMapper:
impl: RoBaRaCoCh
Controller:
impl: Generic
id: Channel 0
avg_read_latency_0: 60.5959473
read_queue_len_avg_0: 1.16075158
write_queue_len_0: 340590
queue_len_0: 366166
num_other_reqs_0: 0
num_write_reqs_0: 5508
read_latency_0: 44841
priority_queue_len_avg_0: 0
row_hits_0: 4367
priority_queue_len_0: 0
row_misses_0: 21
row_conflicts_0: 36
read_row_misses_0: 4
queue_len_avg_0: 16.618227
read_row_conflicts_core_0: 22
read_row_hits_0: 712
write_queue_len_avg_0: 15.4574747
read_row_conflicts_0: 22
write_row_misses_0: 17
write_row_conflicts_0: 14
read_queue_len_0: 25576
write_row_hits_0: 3655
read_row_hits_core_0: 712
read_row_misses_core_0: 4
num_read_reqs_0: 740
Scheduler:
impl: FRFCFS
RefreshManager:
impl: AllBank
RowPolicy:
impl: OpenRowPolicy
ControllerPlugin:
impl: TraceRecorder
Controller:
impl: Generic
id: Channel 1
read_queue_len_avg_1: 0.92838341
priority_queue_len_1: 0
write_queue_len_1: 336405
num_write_reqs_1: 6379
row_hits_1: 4335
row_misses_1: 33
avg_read_latency_1: 53.7567558
queue_len_avg_1: 16.1959248
read_queue_len_1: 20456
read_row_misses_1: 2
priority_queue_len_avg_1: 0
read_row_hits_1: 703
queue_len_1: 356861
read_row_conflicts_1: 33
num_read_reqs_1: 740
num_other_reqs_1: 0
row_conflicts_1: 56
write_row_hits_1: 3632
write_queue_len_avg_1: 15.2675409
write_row_misses_1: 31
write_row_conflicts_1: 23
read_row_hits_core_0: 703
read_row_misses_core_0: 2
read_latency_1: 39780
read_row_conflicts_core_0: 33
Scheduler:
impl: FRFCFS
RefreshManager:
impl: AllBank
RowPolicy:
impl: OpenRowPolicy
ControllerPlugin:
impl: TraceRecorder
单纯就输出而言,其实和2.3.6的日志输出有所不同,但从trace的结果来看,八九不离十,估计有脚本经过进一步处理!
然后再看看kernel.dump文件,太多了,贴一部分:
kernel.elf: file format elf32-littleriscv
Disassembly of section .init:
80000000 <_start>:
80000000: f3 22 10 fc csrr t0, nw
80000004: 17 03 00 00 auipc t1, 0x0
80000008: 13 03 c3 15 addi t1, t1, 0x15c
8000000c: 0b 90 62 00 vx_wspawn t0, t1
80000010: 93 02 f0 ff li t0, -0x1
80000014: 0b 80 02 00 vx_tmc t0
80000018: ef 00 80 11 jal 0x80000130 <init_regs>
看到这,估计有熟悉的感觉了,trace_rtlsim.csv的部分内容如下:
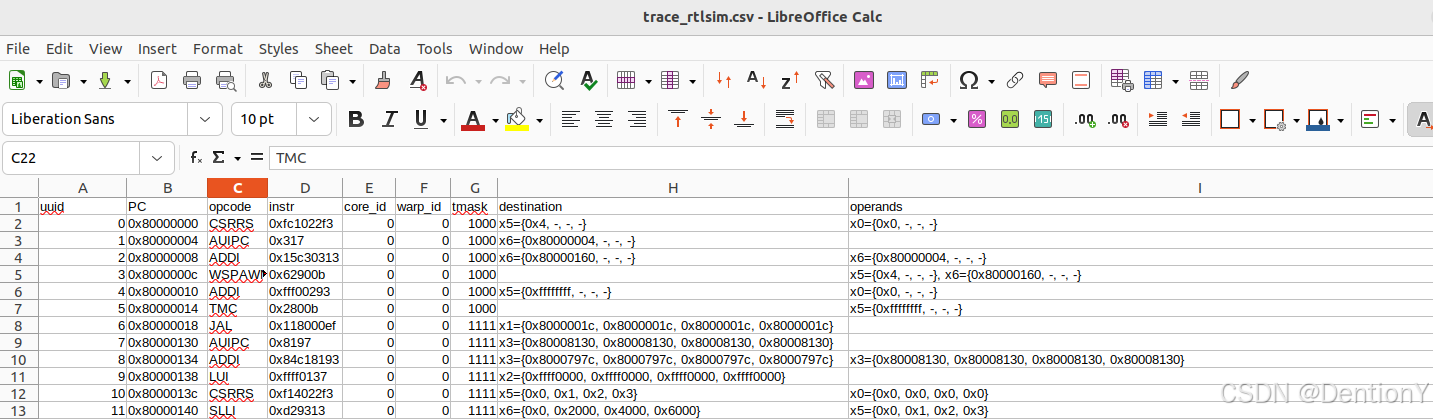
这不就对上了!
再看看ramulator.log.ch0和ramulator.log.ch1:
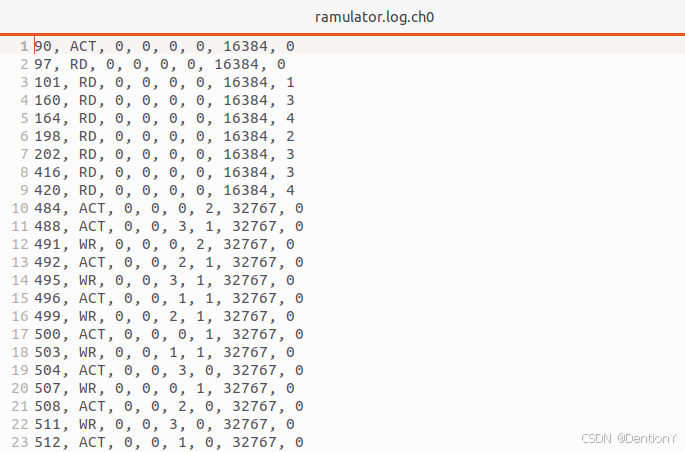
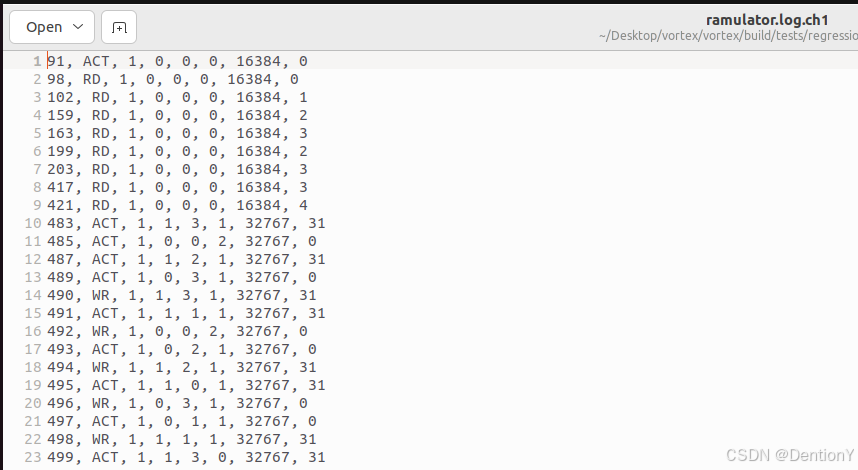
HBM2的两个channel的trace情况有差异,从第一个数字的角度来考虑,感觉是乒乓读取操作了!不过具体含义还得仔细推敲,这个值得挖一挖!
另外就是输入文件的功能,这个放到下一篇介绍!这一篇内容太多了!
├── common.h
├── kernel.cpp
├── main.cpp
└── Makefile
2.3 额外牵扯到的ramulator
2.3.1 ramulator简单介绍
此处简单尝试ramulator,而不去研究这个黑盒的原理,只研究测试用例的输入和输出及其含义:
# 下载ramulator
proxychains4 git clone --recursive https://github.com/CMU-SAFARI/ramulator.git
# 编译
cd ramulator
make -j8
根据官网的描述(直接照搬官网原文的直接翻译了):在2023年8月发布了一个更新版本的Ramulator,称为Ramulator 2.0。Ramulator 2.0更易于使用、扩展和修改。它还支持当时的最新DRAM标准(例如,DDR5、LPDDR5、HBM3、GDDR6)。Ramulator是一个快速且精确到周期的DRAM模拟器,支持广泛的商业和学术DRAM标准:
DDR3 (2007), DDR4 (2012)
LPDDR3 (2012), LPDDR4 (2014)
GDDR5 (2009)
WIO (2011), WIO2 (2014)
HBM (2013)
Ramulator的初始发布在以下论文中描述:
Y. Kim, W. Yang, O. Mutlu. "Ramulator: A Fast and Extensible DRAM Simulator". In IEEE Computer Architecture Letters, March 2015.
关于新特性的信息,以及使用Ramulator进行的广泛内存特性分析,请阅读:
S. Ghose, T. Li, N. Hajinazar, D. Senol Cali, O. Mutlu. "Demystifying Complex Workload–DRAM Interactions: An Experimental Study". In Proceedings of the ACM International Conference on Measurement and Modeling of Computer Systems (SIGMETRICS), June 2019 (slides). In Proceedings of the ACM on Measurement and Analysis of Computing Systems (POMACS), 2019.
2.3.2 ramulator使用方法
Ramulator支持三种常见的不同使用模式和补充方法。
1、内存轨迹驱动:Ramulator直接从文件中读取内存轨迹,并仅模拟DRAM子系统。轨迹文件中的每一行代表一个内存请求,以十六进制地址开头,后跟'R'或'W'表示读或写。
官网提供的测试用例如下:
$ cd ramulator
$ make -j
$ ./ramulator configs/DDR3-config.cfg --mode=dram dram.trace
Simulation done. Statistics written to DDR3.stats
# NOTE: dram.trace is a very short trace file provided only as an example.
$ ./ramulator configs/DDR3-config.cfg --mode=dram --stats my_output.txt dram.trace
Simulation done. Statistics written to my_output.txt
# NOTE: optional --stats flag changes the statistics output filename
2、CPU轨迹驱动:Ramulator直接从文件中读取指令轨迹,并模拟一个简化的“核心”模型,该模型向DRAM子系统生成内存请求。轨迹文件中的每一行代表一个内存请求,可以有以下两种格式之一。
<num-cpuinst> <addr-read>:对于包含两个标记的行,第一个标记表示在内存请求之前的CPU(即非内存)指令数量,第二个标记是读取的十进制地址。
<num-cpuinst> <addr-read> <addr-writeback>:对于包含三个标记的行,第三个标记是写回请求的十进制地址,这是由之前的读取请求引起的脏缓存行驱逐。
官网提供的测试用例如下:
$ cd ramulator
$ make -j
$ ./ramulator configs/DDR3-config.cfg --mode=cpu cpu.trace
Simulation done. Statistics written to DDR3.stats
# NOTE: cpu.trace is a very short trace file provided only as an example.
$ ./ramulator configs/DDR3-config.cfg --mode=cpu --stats my_output.txt cpu.trace
Simulation done. Statistics written to my_output.txt
# NOTE: optional --stats flag changes the statistics output filename
3、gem5驱动:Ramulator作为完整系统模拟器(gem5)的一部分运行,从其中接收生成的内存请求。
官网提供的测试用例如下:
$ hg clone http://repo.gem5.org/gem5-stable
$ cd gem5-stable
$ hg update -c 10231 # Revert to stable version from 5/31/2014 (10231:0e86fac7254c)
$ patch -Np1 --ignore-whitespace < /path/to/ramulator/gem5-0e86fac7254c-ramulator.patch
$ cd ext/ramulator
$ mkdir Ramulator
$ cp -r /path/to/ramulator/src Ramulator
# Compile gem5
# Run gem5 with `--mem-type=ramulator` and `--ramulator-config=configs/DDR3-config.cfg`
默认情况下,gem5使用原子CPU并采用原子内存访问方式,即实际上并没有使用像Ramulator这样详细的内存模型。若要以时序模式运行gem5,则需要通过命令行参数--cpu-type指定CPU类型。例如:--cpu-type=timing。
4、对于某些DRAM标准,Ramulator还能够通过依赖VAMPIRE或DRAMPower 作为后端来报告功耗。
2.3.3 ramulator的输出
Ramulator在每次运行时会报告一系列统计信息,这些信息会被写入一个文件。Statistics.h提供了一系列与gem5兼容的统计类。
1、内存轨迹/CPU轨迹驱动:当以内存轨迹驱动或CPU轨迹驱动模式运行时,Ramulator会将这些统计信息写入一个文件。默认情况下,文件名将是 <standard_name>.stats(例如,DDR3.stats)。你可以通过在--mode选项之后的命令行中添加--stats <filename>来将统计文件写入不同的文件名。
注意此条里的默认情况下,文件名将是 <standard_name>.stats(例如,DDR3.stats)是很关键的线索!
2、gem5驱动:Ramulator会自动将其统计信息集成到gem5中。Ramulator的统计信息会直接写入gem5的统计文件中,并且每个统计信息的名称前会加上 ramulator.前缀。
2.3.4 ramulator的复现
2.3.4.1 调试与验证
为了调试和验证,Ramulator可以打印其发出的每条DRAM命令的轨迹,以及它们的地址和时序信息。为此,请在配置文件中启用print_cmd_trace变量。
2.3.4.2 与其他模拟器的比较
为了将Ramulator与其他DRAM模拟器进行比较,我们提供了一个脚本,用于自动化此过程:test_ddr3.py。然而,在运行此脚本之前,你必须在脚本的源代码中指定的行中指定它们的可执行文件和配置文件的位置:
Ramulator
DRAMSim2 (https://wiki.umd.edu/DRAMSim2):test_ddr3.py 第 39-40 行
USIMM (http://www.cs.utah.edu/~rajeev/jwac12):test_ddr3.py 第 54-55 行
DrSim (http://lph.ece.utexas.edu/public/Main/DrSim):test_ddr3.py 第 66-67 行
NVMain (http://wiki.nvmain.org):test_ddr3.py 第 78-79 行
5种模拟器都使用相同的参数进行了配置:
DDR3-1600K (11-11-11),1 通道,1 级,2Gb x8 芯片
FR-FCFS 调度
Open-Row 策略
32/32 条目读/写队列
写队列的高/低水位线:28/16
最后,运行test_ddr3.py <num-requests>来启动模拟。请确保在模拟期间没有其他活动进程,以获得准确的内存使用量和CPU时间测量。
2.3.4.3 DRAM的轨迹研究
请使用cputraces文件夹中提供的CPU轨迹(SPEC 2006)来运行基于CPU轨迹的模拟。
2.3.5 功耗测试
为了估算功耗,Ramulator可以将它发出的每条DRAM命令的轨迹以 DRAMPower格式记录到一个文件中。为此,请在配置文件中启用record_cmd_trace变量。生成的DRAM命令轨迹(例如,cmd-trace-chan-N-rank-M.cmdtrace)应被输入到一个兼容的DRAM功耗模拟器(如VAMPIRE或DRAMPower)中,并使用正确的配置(标准/速度/组织)来估算单个等级(rank)的能耗/功耗(这是VAMPIRE和DRAMPower的一个当前限制)。
2.3.6 简单使用Ramulator的命令并阅读输入配置文件和输出文件
运行的命令如下:
# 使用内存轨迹驱动模式
dention@dention-virtual-machine:~/Desktop/ramulator$ ./ramulator configs/DDR3-config.cfg --mode=dram --stats my_output_DDR3_mode_dram.txt dram.trace
Simulation done. Statistics written to my_output_DDR3_mode_dram.txt
# 使用CPU轨迹驱动模式
dention@dention-virtual-machine:~/Desktop/ramulator$ ./ramulator configs/DDR3-config.cfg --mode=cpu --stats my_output_DDR3_mode_cpu.txt cpu.trace
tracenum: 1
trace_list[0]: cpu.trace
Warmup complete! Resetting stats...
Starting the simulation...
CPU heartbeat, cycles: 50000000
CPU heartbeat, cycles: 100000000
CPU heartbeat, cycles: 150000000
CPU heartbeat, cycles: 200000000
CPU heartbeat, cycles: 250000000
CPU heartbeat, cycles: 300000000
CPU heartbeat, cycles: 350000000
CPU heartbeat, cycles: 400000000
CPU heartbeat, cycles: 450000000
CPU heartbeat, cycles: 500000000
CPU heartbeat, cycles: 550000000
CPU heartbeat, cycles: 600000000
CPU heartbeat, cycles: 650000000
CPU heartbeat, cycles: 700000000
CPU heartbeat, cycles: 750000000
Simulation done. Statistics written to my_output_DDR3_mode_cpu.txt
输入配置文件DDR3-config.cfg是:
########################
# Example config file
# Comments start with #
# There are restrictions for valid channel/rank numbers
standard = DDR3
channels = 1
ranks = 1
speed = DDR3_1600K
org = DDR3_2Gb_x8
# record_cmd_trace: (default is off): on, off
record_cmd_trace = off
# print_cmd_trace: (default is off): on, off
print_cmd_trace = off
### Below are parameters only for CPU trace
cpu_tick = 4
mem_tick = 1
### Below are parameters only for multicore mode
# When early_exit is on, all cores will be terminated when the earliest one finishes.
early_exit = on
# early_exit = on, off (default value is on)
# If expected_limit_insts is set, some per-core statistics will be recorded when this limit (or the end of the whole trace if it's shorter than specified limit) is reached. The simulation won't stop and will roll back automatically until the last one reaches the limit.
expected_limit_insts = 200000000
# warmup_insts = 100000000
warmup_insts = 0
cache = no
# cache = no, L1L2, L3, all (default value is no)
translation = None
# translation = None, Random (default value is None)
#
########################
简单解释这里的配置,首先是DRAM标准和配置:
standard = DDR3 # 指定使用的DRAM标准为DDR3。
channels = 1 # 指定通道数为1。
ranks = 1 # 指定每个通道的等级数为1。
speed = DDR3_1600K # 指定DRAM的速度等级为DDR3_1600K。
org = DDR3_2Gb_x8 # 指定DRAM的组织方式为DDR3_2Gb_x8,即每个芯片为2Gb,数据宽度为8位。
然后是CPU轨迹相关参数:
cpu_tick = 4 # 指定 CPU 的时钟周期(tick)为 4。
mem_tick = 1 # 指定内存的时钟周期(tick)为 1。
最后是多核模式相关参数:
### Below are parameters only for multicore mode
# When early_exit is on, all cores will be terminated when the earliest one finishes.
early_exit = on # 在多核模式下,如果设置为on,则当最早的核完成时,所有核都将被终止。
# early_exit = on, off (default value is on)
# If expected_limit_insts is set, some per-core statistics will be recorded when this limit (or the end of the whole trace if it's shorter than specified limit) is reached. The simulation won't stop and will roll back automatically until the last one reaches the limit.
expected_limit_insts = 200000000 # 设置每个核预期执行的指令数上限。当达到这个限制(或整个轨迹的结束,如果它比指定的限制短)时,将记录一些每个核的统计信息。模拟不会停止,并会自动回滚,直到最后一个核达到限制。
# warmup_insts = 100000000
warmup_insts = 0 # 设置预热指令数。这里设置为0,表示不进行预热。
cache = no # 指定是否启用缓存。这里设置为no,表示不启用缓存。
# cache = no, L1L2, L3, all (default value is no)
translation = None # 指定地址转换方式。这里设置为None,表示不进行地址转换。
# translation = None, Random (default value is None)
类似配置文件太多了:

核心文件应该是:
不过先不做解读了。此外dram.trace是:
0x12345680 R
0x4cbd56c0 W
0x35d46f00 R
0x696fed40 W
0x7876af80 R
cpu.trace是:
3 20734016
1 20846400
6 20734208
8 20841280 20841280
0 20734144
2 20918976 20734016
这俩确实没看出来是个啥!先跳过!
输出包括了my_output_DDR3_mode_dram.txt和my_output_DDR3_mode_cpu.txt,my_output_DDR3_mode_dram.txt的内容如下:
ramulator.active_cycles_0 57 # Total active cycles for level _0
ramulator.busy_cycles_0 57 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0
ramulator.serving_requests_0 148 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0
ramulator.average_serving_requests_0 2.551724 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0
ramulator.active_cycles_0_0 57 # Total active cycles for level _0_0
ramulator.busy_cycles_0_0 57 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0
ramulator.serving_requests_0_0 148 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0
ramulator.average_serving_requests_0_0 2.551724 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0
ramulator.active_cycles_0_0_0 0 # Total active cycles for level _0_0_0
ramulator.busy_cycles_0_0_0 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_0
ramulator.serving_requests_0_0_0 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.average_serving_requests_0_0_0 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.active_cycles_0_0_1 0 # Total active cycles for level _0_0_1
ramulator.busy_cycles_0_0_1 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_1
ramulator.serving_requests_0_0_1 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.average_serving_requests_0_0_1 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.active_cycles_0_0_2 49 # Total active cycles for level _0_0_2
ramulator.busy_cycles_0_0_2 49 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_2
ramulator.serving_requests_0_0_2 49 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.average_serving_requests_0_0_2 0.844828 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.active_cycles_0_0_3 43 # Total active cycles for level _0_0_3
ramulator.busy_cycles_0_0_3 43 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_3
ramulator.serving_requests_0_0_3 43 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.average_serving_requests_0_0_3 0.741379 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.active_cycles_0_0_4 0 # Total active cycles for level _0_0_4
ramulator.busy_cycles_0_0_4 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_4
ramulator.serving_requests_0_0_4 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.average_serving_requests_0_0_4 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.active_cycles_0_0_5 41 # Total active cycles for level _0_0_5
ramulator.busy_cycles_0_0_5 41 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_5
ramulator.serving_requests_0_0_5 41 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.average_serving_requests_0_0_5 0.706897 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.active_cycles_0_0_6 0 # Total active cycles for level _0_0_6
ramulator.busy_cycles_0_0_6 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_6
ramulator.serving_requests_0_0_6 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.average_serving_requests_0_0_6 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.active_cycles_0_0_7 15 # Total active cycles for level _0_0_7
ramulator.busy_cycles_0_0_7 15 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_7
ramulator.serving_requests_0_0_7 15 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.average_serving_requests_0_0_7 0.258621 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.read_transaction_bytes_0 192 # The total byte of read transaction per channel
ramulator.write_transaction_bytes_0 128 # The total byte of write transaction per channel
ramulator.row_hits_channel_0_core 0 # Number of row hits per channel per core
ramulator.row_misses_channel_0_core 4 # Number of row misses per channel per core
ramulator.row_conflicts_channel_0_core 1 # Number of row conflicts per channel per core
ramulator.read_row_hits_channel_0_core 0 # Number of row hits for read requests per channel per core
[0] 0.0 #
ramulator.read_row_misses_channel_0_core 3 # Number of row misses for read requests per channel per core
[0] 3.0 #
ramulator.read_row_conflicts_channel_0_core 0 # Number of row conflicts for read requests per channel per core
[0] 0.0 #
ramulator.write_row_hits_channel_0_core 0 # Number of row hits for write requests per channel per core
[0] 0.0 #
ramulator.write_row_misses_channel_0_core 1 # Number of row misses for write requests per channel per core
[0] 1.0 #
ramulator.write_row_conflicts_channel_0_core 1 # Number of row conflicts for write requests per channel per core
[0] 1.0 #
ramulator.useless_activates_0_core 0 # Number of useless activations. E.g, ACT -> PRE w/o RD or WR
ramulator.read_latency_avg_0 44.333333 # The average memory latency cycles (in memory time domain) per request for all read requests in this channel
ramulator.read_latency_sum_0 133 # The memory latency cycles (in memory time domain) sum for all read requests in this channel
ramulator.req_queue_length_avg_0 1.896552 # Average of read and write queue length per memory cycle per channel.
ramulator.req_queue_length_sum_0 110 # Sum of read and write queue length per memory cycle per channel.
ramulator.read_req_queue_length_avg_0 1.172414 # Read queue length average per memory cycle per channel.
ramulator.read_req_queue_length_sum_0 68 # Read queue length sum per memory cycle per channel.
ramulator.write_req_queue_length_avg_0 0.724138 # Write queue length average per memory cycle per channel.
ramulator.write_req_queue_length_sum_0 42 # Write queue length sum per memory cycle per channel.
ramulator.record_read_hits 0.0 # record read hit count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_read_misses 0.0 # record_read_miss count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_read_conflicts 0.0 # record read conflict count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_write_hits 0.0 # record write hit count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_write_misses 0.0 # record write miss count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_write_conflicts 0.0 # record write conflict for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.dram_capacity 2147483648 # Number of bytes in simulated DRAM
ramulator.dram_cycles 58 # Number of DRAM cycles simulated
ramulator.incoming_requests 5 # Number of incoming requests to DRAM
ramulator.read_requests 3 # Number of incoming read requests to DRAM per core
[0] 3.0 #
ramulator.write_requests 2 # Number of incoming write requests to DRAM per core
[0] 2.0 #
ramulator.ramulator_active_cycles 57 # The total number of cycles that the DRAM part is active (serving R/W)
ramulator.incoming_requests_per_channel 5.0 # Number of incoming requests to each DRAM channel
[0] 5.0 #
ramulator.incoming_read_reqs_per_channel 3.0 # Number of incoming read requests to each DRAM channel
[0] 3.0 #
ramulator.physical_page_replacement 0 # The number of times that physical page replacement happens.
ramulator.maximum_bandwidth 12800000000 # The theoretical maximum bandwidth (Bps)
ramulator.in_queue_req_num_sum 110 # Sum of read/write queue length
ramulator.in_queue_read_req_num_sum 68 # Sum of read queue length
ramulator.in_queue_write_req_num_sum 42 # Sum of write queue length
ramulator.in_queue_req_num_avg 1.896552 # Average of read/write queue length per memory cycle
ramulator.in_queue_read_req_num_avg 1.172414 # Average of read queue length per memory cycle
ramulator.in_queue_write_req_num_avg 0.724138 # Average of write queue length per memory cycle
ramulator.record_read_requests 0.0 # record read requests for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_write_requests 0.0 # record write requests for this core when it reaches request limit or to the end
[0] 0.0 #
简单看下注释内容,如下:
| 分类 | 统计项 | 值 | 注释 |
|---|---|---|---|
| DRAM 活动周期和忙周期 | ramulator.active_cycles_0 | 57 | 级别 _0 的总活动周期 |
| DRAM 活动周期和忙周期 | ramulator.busy_cycles_0 | 57 | 级别 _0 的总忙周期(仅包括刷新时间) |
| DRAM 服务请求 | ramulator.serving_requests_0 | 148 | 级别 _0 每个内存周期内服务的读写请求总数 |
| DRAM 服务请求 | ramulator.average_serving_requests_0 | 2.551724 | 级别 _0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0 | 57 | 级别 _0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0 | 57 | 级别 _0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0 | 148 | 级别 _0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0 | 2.551724 | 级别 _0_0 每个内存周期内服务的读写请求的平均数 |
| 读写事务字节数 | ramulator.read_transaction_bytes_0 | 192 | 每个通道的读事务总字节数 |
| 读写事务字节数 | ramulator.write_transaction_bytes_0 | 128 | 每个通道的写事务总字节数 |
| 行命中、未命中和冲突 | ramulator.row_hits_channel_0_core | 0 | 每个通道每个核心的行命中次数 |
| 行命中、未命中和冲突 | ramulator.row_misses_channel_0_core | 4 | 每个通道每个核心的行未命中次数 |
| 行命中、未命中和冲突 | ramulator.row_conflicts_channel_0_core | 1 | 每个通道每个核心的行冲突次数 |
| 读写队列长度 | ramulator.req_queue_length_avg_0 | 1.896552 | 每个通道每个内存周期内读写队列长度的平均值 |
| 读写队列长度 | ramulator.req_queue_length_sum_0 | 110 | 每个通道每个内存周期内读写队列长度的总和 |
| DRAM 容量和周期 | ramulator.dram_capacity | 2147483648 | 模拟的 DRAM 容量(字节) |
| DRAM 容量和周期 | ramulator.dram_cycles | 58 | 模拟的 DRAM 周期数 |
| 其他统计信息 | ramulator.incoming_requests | 5 | 到达 DRAM 的请求数 |
| 其他统计信息 | ramulator.read_requests | 3 | 每个核心到达 DRAM 的读请求数 |
| 其他统计信息 | ramulator.write_requests | 2 | 每个核心到达 DRAM 的写请求数 |
| 队列长度统计 | ramulator.in_queue_req_num_sum | 110 | 读写队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_read_req_num_sum | 68 | 读队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_write_req_num_sum | 42 | 写队列长度的总和 |
| 平均队列长度 | ramulator.in_queue_req_num_avg | 1.896552 | 每个内存周期内读写队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_read_req_num_avg | 1.172414 | 每个内存周期内读队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_write_req_num_avg | 0.724138 | 每个内存周期内写队列长度的平均值 |
my_output_DDR3_mode_cpu.txt的内容如下:
ramulator.active_cycles_0 122445958 # Total active cycles for level _0
ramulator.busy_cycles_0 122445958 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0
ramulator.serving_requests_0 429759559 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0
ramulator.average_serving_requests_0 2.273115 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0
ramulator.active_cycles_0_0 122445958 # Total active cycles for level _0_0
ramulator.busy_cycles_0_0 126324102 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0
ramulator.serving_requests_0_0 429759559 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0
ramulator.average_serving_requests_0_0 2.273115 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0
ramulator.active_cycles_0_0_0 106259048 # Total active cycles for level _0_0_0
ramulator.busy_cycles_0_0_0 106259048 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_0
ramulator.serving_requests_0_0_0 107522760 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.average_serving_requests_0_0_0 0.568717 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_0
ramulator.active_cycles_0_0_1 104663261 # Total active cycles for level _0_0_1
ramulator.busy_cycles_0_0_1 104663261 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_1
ramulator.serving_requests_0_0_1 107556805 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.average_serving_requests_0_0_1 0.568897 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_1
ramulator.active_cycles_0_0_2 0 # Total active cycles for level _0_0_2
ramulator.busy_cycles_0_0_2 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_2
ramulator.serving_requests_0_0_2 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.average_serving_requests_0_0_2 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_2
ramulator.active_cycles_0_0_3 115429984 # Total active cycles for level _0_0_3
ramulator.busy_cycles_0_0_3 115429984 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_3
ramulator.serving_requests_0_0_3 214679974 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.average_serving_requests_0_0_3 1.135501 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_3
ramulator.active_cycles_0_0_4 0 # Total active cycles for level _0_0_4
ramulator.busy_cycles_0_0_4 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_4
ramulator.serving_requests_0_0_4 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.average_serving_requests_0_0_4 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_4
ramulator.active_cycles_0_0_5 0 # Total active cycles for level _0_0_5
ramulator.busy_cycles_0_0_5 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_5
ramulator.serving_requests_0_0_5 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.average_serving_requests_0_0_5 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_5
ramulator.active_cycles_0_0_6 0 # Total active cycles for level _0_0_6
ramulator.busy_cycles_0_0_6 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_6
ramulator.serving_requests_0_0_6 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.average_serving_requests_0_0_6 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_6
ramulator.active_cycles_0_0_7 0 # Total active cycles for level _0_0_7
ramulator.busy_cycles_0_0_7 0 # (All-bank refresh only. busy cycles only include refresh time in rank level) The sum of cycles that the DRAM part is active or under refresh for level _0_0_7
ramulator.serving_requests_0_0_7 0 # The sum of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.average_serving_requests_0_0_7 0.000000 # The average of read and write requests that are served in this DRAM element per memory cycle for level _0_0_7
ramulator.read_transaction_bytes_0 1828569600 # The total byte of read transaction per channel
ramulator.write_transaction_bytes_0 914284416 # The total byte of write transaction per channel
ramulator.row_hits_channel_0_core 42766197 # Number of row hits per channel per core
ramulator.row_misses_channel_0_core 90897 # Number of row misses per channel per core
ramulator.row_conflicts_channel_0_core 0 # Number of row conflicts per channel per core
ramulator.read_row_hits_channel_0_core 28491232 # Number of row hits for read requests per channel per core
[0] 28491232.0 #
ramulator.read_row_misses_channel_0_core 80168 # Number of row misses for read requests per channel per core
[0] 80168.0 #
ramulator.read_row_conflicts_channel_0_core 0 # Number of row conflicts for read requests per channel per core
[0] 0.0 #
ramulator.write_row_hits_channel_0_core 14274965 # Number of row hits for write requests per channel per core
[0] 14274965.0 #
ramulator.write_row_misses_channel_0_core 10729 # Number of row misses for write requests per channel per core
[0] 10729.0 #
ramulator.write_row_conflicts_channel_0_core 0 # Number of row conflicts for write requests per channel per core
[0] 0.0 #
ramulator.useless_activates_0_core 0 # Number of useless activations. E.g, ACT -> PRE w/o RD or WR
ramulator.read_latency_avg_0 151.034782 # The average memory latency cycles (in memory time domain) per request for all read requests in this channel
ramulator.read_latency_sum_0 6472919250 # The memory latency cycles (in memory time domain) sum for all read requests in this channel
ramulator.req_queue_length_avg_0 50.407613 # Average of read and write queue length per memory cycle per channel.
ramulator.req_queue_length_sum_0 9530162547 # Sum of read and write queue length per memory cycle per channel.
ramulator.read_req_queue_length_avg_0 35.435893 # Read queue length average per memory cycle per channel.
ramulator.read_req_queue_length_sum_0 6699579776 # Read queue length sum per memory cycle per channel.
ramulator.write_req_queue_length_avg_0 14.971719 # Write queue length average per memory cycle per channel.
ramulator.write_req_queue_length_sum_0 2830582771 # Write queue length sum per memory cycle per channel.
ramulator.record_read_hits 28491232.0 # record read hit count for this core when it reaches request limit or to the end
[0] 28491232.0 #
ramulator.record_read_misses 80168.0 # record_read_miss count for this core when it reaches request limit or to the end
[0] 80168.0 #
ramulator.record_read_conflicts 0.0 # record read conflict count for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.record_write_hits 14274965.0 # record write hit count for this core when it reaches request limit or to the end
[0] 14274965.0 #
ramulator.record_write_misses 10729.0 # record write miss count for this core when it reaches request limit or to the end
[0] 10729.0 #
ramulator.record_write_conflicts 0.0 # record write conflict for this core when it reaches request limit or to the end
[0] 0.0 #
ramulator.dram_capacity 2147483648 # Number of bytes in simulated DRAM
ramulator.dram_cycles 189061970 # Number of DRAM cycles simulated
ramulator.incoming_requests 57142857 # Number of incoming requests to DRAM
ramulator.read_requests 42857143 # Number of incoming read requests to DRAM per core
[0] 42857143.0 #
ramulator.write_requests 14285714 # Number of incoming write requests to DRAM per core
[0] 14285714.0 #
ramulator.ramulator_active_cycles 122445958 # The total number of cycles that the DRAM part is active (serving R/W)
ramulator.incoming_requests_per_channel 57142857.0 # Number of incoming requests to each DRAM channel
[0] 57142857.0 #
ramulator.incoming_read_reqs_per_channel 42857143.0 # Number of incoming read requests to each DRAM channel
[0] 42857143.0 #
ramulator.physical_page_replacement 0 # The number of times that physical page replacement happens.
ramulator.maximum_bandwidth 12800000000 # The theoretical maximum bandwidth (Bps)
ramulator.in_queue_req_num_sum 9530162547 # Sum of read/write queue length
ramulator.in_queue_read_req_num_sum 6699579776 # Sum of read queue length
ramulator.in_queue_write_req_num_sum 2830582771 # Sum of write queue length
ramulator.in_queue_req_num_avg 50.407613 # Average of read/write queue length per memory cycle
ramulator.in_queue_read_req_num_avg 35.435893 # Average of read queue length per memory cycle
ramulator.in_queue_write_req_num_avg 14.971719 # Average of write queue length per memory cycle
ramulator.record_read_requests 42857143.0 # record read requests for this core when it reaches request limit or to the end
[0] 42857143.0 #
ramulator.record_write_requests 14285714.0 # record write requests for this core when it reaches request limit or to the end
[0] 14285714.0 #
ramulator.L3_cache_read_miss 0 # cache read miss count
ramulator.L3_cache_write_miss 0 # cache write miss count
ramulator.L3_cache_total_miss 0 # cache total miss count
ramulator.L3_cache_eviction 0 # number of evict from this level to lower level
ramulator.L3_cache_read_access 0 # cache read access count
ramulator.L3_cache_write_access 0 # cache write access count
ramulator.L3_cache_total_access 0 # cache total access count
ramulator.L3_cache_mshr_hit 0 # cache mshr hit count
ramulator.L3_cache_mshr_unavailable 0 # cache mshr not available count
ramulator.L3_cache_set_unavailable 0 # cache set not available
ramulator.cpu_cycles 756247878 # cpu cycle number
ramulator.record_cycs_core_0 756247878 # Record cycle number for calculating weighted speedup. (Only valid when expected limit instruction number is non zero in config file.)
ramulator.record_insts_core_0 200000000 # Retired instruction number when record cycle number. (Only valid when expected limit instruction number is non zero in config file.)
ramulator.memory_access_cycles_core_0 184376713 # memory access cycles in memory time domain
ramulator.cpu_instructions_core_0 200000000 # cpu instruction number
同前面相同的操作,如下:
| 分类 | 统计项 | 值 | 注释 |
|---|---|---|---|
| DRAM 活动周期和忙周期 | ramulator.active_cycles_0 | 122445958 | 级别 _0 的总活动周期 |
| DRAM 活动周期和忙周期 | ramulator.busy_cycles_0 | 122445958 | 级别 _0 的总忙周期(仅包括刷新时间) |
| DRAM 服务请求 | ramulator.serving_requests_0 | 429759559 | 级别 _0 每个内存周期内服务的读写请求总数 |
| DRAM 服务请求 | ramulator.average_serving_requests_0 | 2.273115 | 级别 _0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0 | 122445958 | 级别 _0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0 | 126324102 | 级别 _0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0 | 429759559 | 级别 _0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0 | 2.273115 | 级别 _0_0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_0 | 106259048 | 级别 _0_0_0 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_0 | 106259048 | 级别 _0_0_0 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_0 | 107522760 | 级别 _0_0_0 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_0 | 0.568717 | 级别 _0_0_0 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_1 | 104663261 | 级别 _0_0_1 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_1 | 104663261 | 级别 _0_0_1 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_1 | 107556805 | 级别 _0_0_1 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_1 | 0.568897 | 级别 _0_0_1 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_2 | 0 | 级别 _0_0_2 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_2 | 0 | 级别 _0_0_2 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_2 | 0 | 级别 _0_0_2 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_2 | 0.000000 | 级别 _0_0_2 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_3 | 115429984 | 级别 _0_0_3 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_3 | 115429984 | 级别 _0_0_3 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_3 | 214679974 | 级别 _0_0_3 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_3 | 1.135501 | 级别 _0_0_3 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_4 | 0 | 级别 _0_0_4 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_4 | 0 | 级别 _0_0_4 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_4 | 0 | 级别 _0_0_4 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_4 | 0.000000 | 级别 _0_0_4 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_5 | 0 | 级别 _0_0_5 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_5 | 0 | 级别 _0_0_5 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_5 | 0 | 级别 _0_0_5 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_5 | 0.000000 | 级别 _0_0_5 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_6 | 0 | 级别 _0_0_6 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_6 | 0 | 级别 _0_0_6 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_6 | 0 | 级别 _0_0_6 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_6 | 0.000000 | 级别 _0_0_6 每个内存周期内服务的读写请求的平均数 |
| 多级统计 | ramulator.active_cycles_0_0_7 | 0 | 级别 _0_0_7 的总活动周期 |
| 多级统计 | ramulator.busy_cycles_0_0_7 | 0 | 级别 _0_0_7 的总忙周期(仅包括刷新时间) |
| 多级统计 | ramulator.serving_requests_0_0_7 | 0 | 级别 _0_0_7 每个内存周期内服务的读写请求总数 |
| 多级统计 | ramulator.average_serving_requests_0_0_7 | 0.000000 | 级别 _0_0_7 每个内存周期内服务的读写请求的平均数 |
| 读写事务字节数 | ramulator.read_transaction_bytes_0 | 1828569600 | 每个通道的读事务总字节数 |
| 读写事务字节数 | ramulator.write_transaction_bytes_0 | 914284416 | 每个通道的写事务总字节数 |
| 行命中、未命中和冲突 | ramulator.row_hits_channel_0_core | 42766197 | 每个通道每个核心的行命中次数 |
| 行命中、未命中和冲突 | ramulator.row_misses_channel_0_core | 90897 | 每个通道每个核心的行未命中次数 |
| 行命中、未命中和冲突 | ramulator.row_conflicts_channel_0_core | 0 | 每个通道每个核心的行冲突次数 |
| 行命中、未命中和冲突 | ramulator.read_row_hits_channel_0_core | 28491232 | 每个通道每个核心的读行命中次数 |
| 行命中、未命中和冲突 | ramulator.read_row_misses_channel_0_core | 80168 | 每个通道每个核心的读行未命中次数 |
| 行命中、未命中和冲突 | ramulator.read_row_conflicts_channel_0_core | 0 | 每个通道每个核心的读行冲突次数 |
| 行命中、未命中和冲突 | ramulator.write_row_hits_channel_0_core | 14274965 | 每个通道每个核心的写行命中次数 |
| 行命中、未命中和冲突 | ramulator.write_row_misses_channel_0_core | 10729 | 每个通道每个核心的写行未命中次数 |
| 行命中、未命中和冲突 | ramulator.write_row_conflicts_channel_0_core | 0 | 每个通道每个核心的写行冲突次数 |
| 其他统计信息 | ramulator.useless_activates_0_core | 0 | 无用激活次数 |
| 其他统计信息 | ramulator.read_latency_avg_0 | 151.034782 | 每个通道的平均读延迟(内存时间域) |
| 其他统计信息 | ramulator.read_latency_sum_0 | 6472919250 | 每个通道的读延迟总和(内存时间域) |
| 读写队列长度 | ramulator.req_queue_length_avg_0 | 50.407613 | 每个通道每个内存周期内读写队列长度的平均值 |
| 读写队列长度 | ramulator.req_queue_length_sum_0 | 9530162547 | 每个通道每个内存周期内读写队列长度的总和 |
| 读写队列长度 | ramulator.read_req_queue_length_avg_0 | 35.435893 | 每个通道每个内存周期内读队列长度的平均值 |
| 读写队列长度 | ramulator.read_req_queue_length_sum_0 | 6699579776 | 每个通道每个内存周期内读队列长度的总和 |
| 读写队列长度 | ramulator.write_req_queue_length_avg_0 | 14.971719 | 每个通道每个内存周期内写队列长度的平均值 |
| 读写队列长度 | ramulator.write_req_queue_length_sum_0 | 2830582771 | 每个通道每个内存周期内写队列长度的总和 |
| DRAM 容量和周期 | ramulator.dram_capacity | 2147483648 | 模拟的 DRAM 容量(字节) |
| DRAM 容量和周期 | ramulator.dram_cycles | 189061970 | 模拟的 DRAM 周期数 |
| 其他统计信息 | ramulator.incoming_requests | 57142857 | 到达 DRAM 的请求数 |
| 其他统计信息 | ramulator.read_requests | 42857143 | 每个核心到达 DRAM 的读请求数 |
| 其他统计信息 | ramulator.write_requests | 14285714 | 每个核心到达 DRAM 的写请求数 |
| 队列长度统计 | ramulator.in_queue_req_num_sum | 9530162547 | 读写队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_read_req_num_sum | 6699579776 | 读队列长度的总和 |
| 队列长度统计 | ramulator.in_queue_write_req_num_sum | 2830582771 | 写队列长度的总和 |
| 平均队列长度 | ramulator.in_queue_req_num_avg | 50.407613 | 每个内存周期内读写队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_read_req_num_avg | 35.435893 | 每个内存周期内读队列长度的平均值 |
| 平均队列长度 | ramulator.in_queue_write_req_num_avg | 14.971719 | 每个内存周期内写队列长度的平均值 |
以上关于Ramulator的介绍暂时到此为止!
2.4 额外牵扯到的GEM5
2.4.1 GEM5简单介绍
GEM5模拟器是一个用于计算机系统架构研究的模块化平台,涵盖了系统级架构以及处理器微架构。它主要用于评估新的硬件设计、系统软件变更,以及编译时和运行时的系统优化。
2.4.2 GEM5的源代码树
主源代码树包括以下子目录:
- build_opts:gem5 的预设默认配置
- build_tools:gem5 构建过程内部使用的工具
- configs:示例模拟配置脚本
- ext:构建 gem5 所需的不太常见的外部包
- include:供其他程序使用的头文件
- site_scons:构建系统的模块化组件
- src:gem5 模拟器的源代码。C++ 源代码、Python 包装器和 Python 标准库都位于此目录中。
- system:为模拟系统提供的一些可选系统软件的源代码
- tests:回归测试
- util:有用的工具程序和文件
因为GEM5模拟器确实很复杂,我暂时不想牵扯太多,只把前面与Ramulator相关的GEM5进行跑通!
2.4.3 基于gem5驱动的ramulator尝试
这个有点棘手,放到下一篇展开!遇到了不少bug,得修一修!
2025/05/26 补充:
这个bug的来源是ramulator的patch文件指定了特定版本的gem5,但是该版本的gem5我没在仓库里翻到。因此放弃修这个bug。
看了一下,有ramulator2,该新版本的ramulator可以比较方便地支持gem5,且官网有示例,对存储器的支持也额外扩展了如下:
DDR3, DDR4, DDR5
LPDDR5
GDDR6
HBM(2), HBM3
不想扯入太多支线任务,因此简单了解到这一步就行。感兴趣的大佬自行探索!
总结
这一篇为分析RTL代码做了点准备,探索了blackbox.sh的输入输出,ramulator的输入输出以及简单介绍了GEM5。
挖了不少坑:
1、xrt和opae两种驱动模式得到的cycles不一样;
2、HBM2的两个channel的trace情况探讨。
留给下一篇的:
1、trace_csv.py解读;
2、demo下的四个文件解读;


















 2253
2253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











