







本文以线性回归为例,讲解了批量梯度下降、随机梯度下降、小批量梯度下降、冲量梯度下降等算法,由浅入深,并结合精心设计的例子,使读者最快掌握这种最常用的优化方法。每一种优化方法,笔者都基于R语言给出了相应的代码,供读者参考,
梯度下降
假如我们有以下身高和体重的数据,我们希望用身高来预测体重。如果你学过统计,那么很自然地就能想到建立一个线性回归模型:
\[y=a+bx\]
其中\(a\)是截距,\(b\)是斜率,\(y\)是体重,\(x\)是身高。

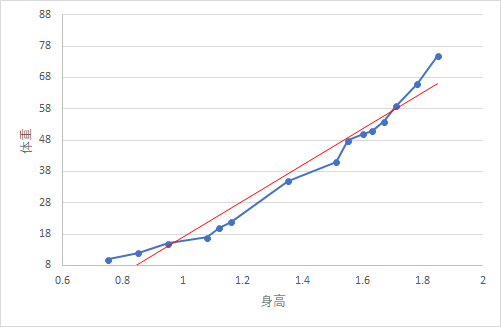
我们将身高与体重的关系在Excel里面用折线图表示,并且添加了线性的趋势线。蓝色的线条是真实数据,红色的实线是模型给出的预测值。蓝色线条与红色线条之间的距离绝对值是预测误差。所以,我们要找到最优的\(a\)和\(b\)来拟合这条直线,使得我们模型的总误差最小。
\[Error = \frac{1}{2}(Actual\ weight - Predicted\ weight)^2=\frac{1}{2}(Y-Ypred)^2\]
我们使用均方误差来表示模型的误差,由于\(Ypred = a + bx\),因此,模型的均方误差可以表示为
\[SSE = \sum \frac{1}{2}(Y-a-bx)^2\]
也就是说,\(SSE\)是关于\(a\)和\(b\)的函数,我们只需要不断调整\(a\)和\(b\),使\(SSE\)降到最低就可以了。这个时候,我们就可以利用梯度下降算法,来求解\(a\)和\(b\)的值。
梯度下降的计算过程如下:
step 1:随机初始化权重\(a\)和\(b\),计算出误差\(SSE\)
step 2:计算梯度。 \(a\)和\(b\)的轻微变化都会导致\(SSE\)的变化,因此,我们只需要找到能使\(SSE\)减小的\(a\)和\(b\)的变化方向就可以了。这个方向,一般就是由梯度决定的。
step 3:调整权重值,使得\(SSE\)不断接近最小值。
step 4:使用新的权重去做预测,并且计算出新的\(SSE\)。
step 5:重复step2-step3,直到权重不再显著变化为止。

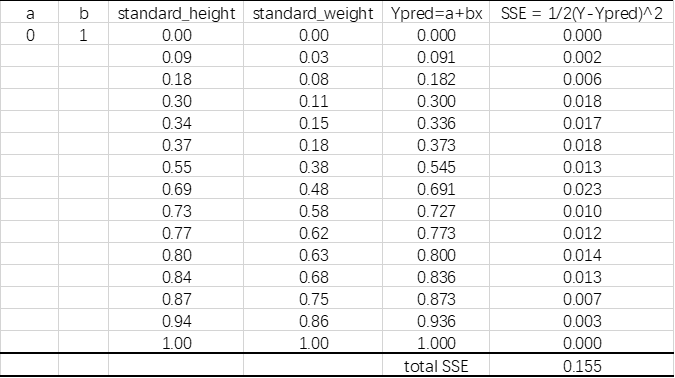
我们在Excel中进行上述步骤。为了计算能够快一点,我们首先对数据进行Min-Max标准化。得到如下数据:

step1:随机选取一组权重(此处我们设置a=0,b=1),我们计算出预测值和误差:
step2:计算梯度
\[\frac{\partial SSE}{\partial a} = \sum-(Y-a-bx)=\sum-(Y-Ypred)\]
\[\frac{\partial SSE}{\partial b}=\sum-(Y-a-bx)x=\sum-(Y-Ypred)x\]
\(\frac{\partial SSE}{\partial a}\)和\(\frac{\partial SSE}{\partial b}\)就是梯度,他们决定了\(a\)和\(b\)的移动方向和距离。
step3: 调整权重值,使得\(SSE\)不断接近最小值。
调整规则为:
\[a_{new} = a_{old} - \eta \nabla a = a_{old} - \eta \cdot \partial SSE/\partial a\]
\[b_{new} = b_{old} - \eta \nabla b = b_{old} - \eta \cdot \partial SSE / \partial b\]
其中,\(\eta\)是一个被我们称之为学习率(learning rate)的东西,一般设置为0.01或者你希望的任何比较小的数值。
本文选择0.01作为学习率。
\[a_{new} = 0 - 0.01 \times 1.925 = -0.01925\]
\[b_{new} = 1 - 0.01 \times 1.117 = 0.98883\]
step4:使用新的权重去做预测,并且计算出新的\(SSE\)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 701
701











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









